LLM Bench Marker
AI, AI Utility
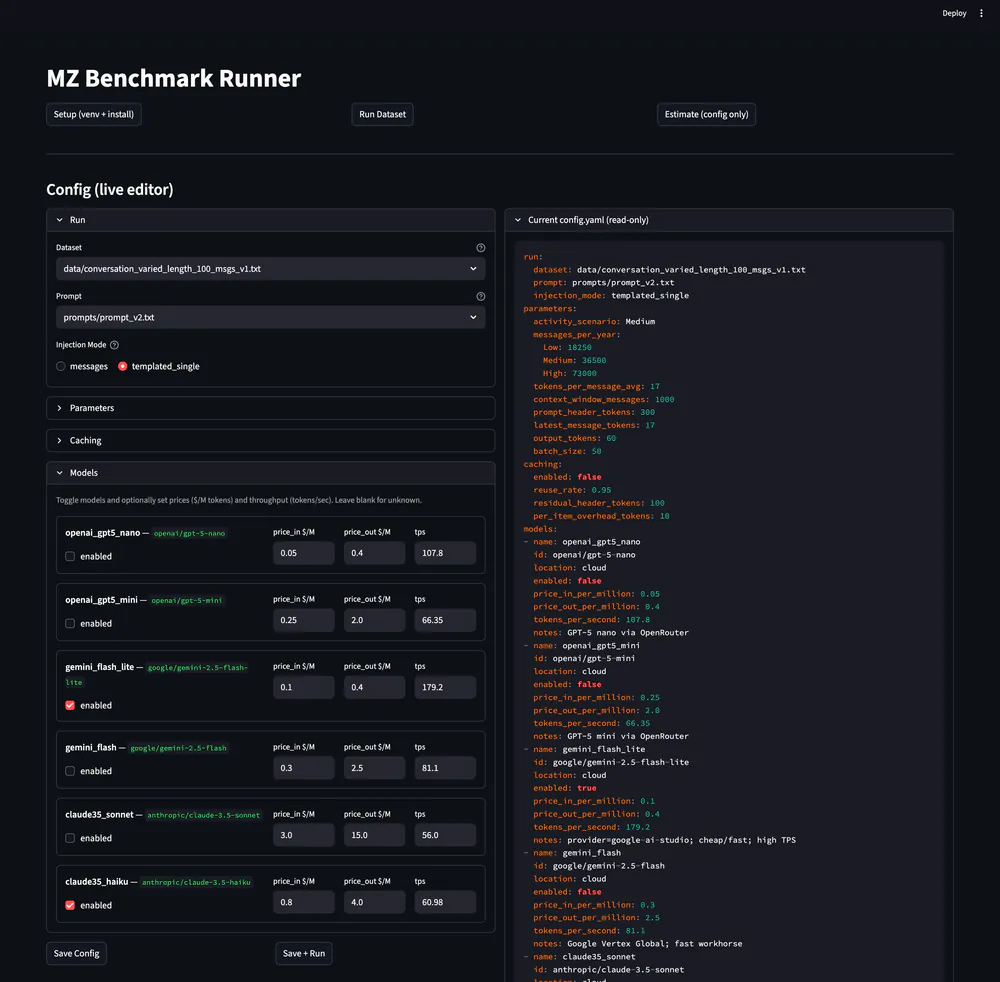
Project Summary
A benchmarking tool that runs multi‑model sweeps on curated datasets with fixed prompts to identify the best cost/quality trade‑offs.
It includes a live config editor with a read‑only YAML preview for reproducible runs, plus model toggles with pricing and throughput hints.
Runs log tokens, latency, and quality scores per prompt, compare models side‑by‑side, and highlight the most suitable option for a target budget or score.
Reports export to CSV/JSON with a table view, and a log inspector shows pretty JSON alongside parsed model response fields. A single‑model measurement mode helps quick spot checks.
Case Study
Overview
Built a repeatable evaluation pipeline to compare LLM providers on real production prompts, making model selection faster and less subjective.
Problem
Model selection was inconsistent and slow. Ad-hoc tests used different prompts, lacked versioning, and made it hard to compare cost, latency, and quality across providers.
Goals
- Reduce model evaluation time by >60% per selection cycle.
- Ensure runs are reproducible with versioned datasets + prompts.
- Support ≥10 models per sweep without manual tuning.
- Capture tokens, latency, and quality scores for every run.
- Produce exportable reports for product and engineering reviews.
Approach
- Chose OpenRouter as the primary router to avoid per-provider SDK sprawl and normalize rate limits, accepting less direct control over model-specific quirks.
- Kept reporting to CSV/JSON so stakeholders could slice data in their own tools without waiting for a bespoke dashboard.
- Used a rubric-based scoring pass with normalization per dataset to reduce model-family bias, then cross-checked scores on a small blind sample.
- Made the YAML config the source of truth so every run is auditable and reproducible, with the UI acting as a structured editor.
- Optimized for repeatable, batch-friendly sweeps rather than live inference to keep costs predictable and runs auditable.
Solution
A benchmarking utility with a web UI that includes a versioned dataset registry, a parallel sweep runner, a scoring module, a YAML config editor, CSV/JSON exports, a report table, and a log inspector.
Outcomes
- Cut evaluation cycles from ~2 days to ~8-12 hours across 8 recorded sweeps.
- Enabled 10–12 model sweeps over 3 datasets with consistent scoring and repeatable run IDs.
- Reduced log triage from hours to ~30-45 minutes using the JSON inspector and parsed response view.
- Delivered 5 decision-ready reports used in product and engineering reviews.
Key Metrics
Timeline
Challenges
- Keeping prompts deterministic while maintaining realistic outputs.
- Balancing cost constraints with enough coverage for confidence.
- Normalizing quality scores across model families.