One of 55 free AI tools built by Zalt, an AI architect and consultant with 16 years of experience.
Free Image to Text
Upload or paste an image and instantly extract all text from it using Tesseract.js, the most popular open-source OCR engine. Supports 100+ languages including English, Arabic, Chinese, Japanese, Korean, Hindi, and more. All processing happens locally in your browser — no signup, no server, no API calls. Your images stay on your device.
Preparing OCR interface...
Hire AI Employees
Hire AI Employees that work 24/7. No code.Are you a solo founder still doing sales, marketing, and support by hand? Hire AI Employees to run it all for you. They work 24/7, set up with no code, and go live in minutes.


More Free Tools
More than 20 free AI tools.

Hire AI Expert
Mahmoud Zalt · Freelance AI Engineer
What Is Tesseract.js and How Does This OCR Tool Work?
This image-to-text tool is powered by Tesseract.js, the most popular open-source OCR library for the web. Tesseract.js is a JavaScript port of the Tesseract OCR engine, originally developed at Hewlett-Packard Labs in the 1980s and later maintained and improved by Google. It can extract text from images in over 100 languages, including English, Arabic, Chinese, Japanese, Korean, Hindi, Russian, and many more.
The engine runs entirely in your browser via WebAssembly — no server, no cloud processing, no API keys. You upload or paste an image, select the language, and the OCR engine analyzes pixel patterns to recognize characters and words. It works with JPG, PNG, BMP, WEBP, and GIF formats, and handles screenshots, photos of documents, receipts, signs, whiteboards, and scanned pages.
Tesseract.js v7 brings significant improvements over earlier versions: 54% smaller language files for English, 73% smaller for Chinese, approximately 50% faster initial load times, reduced runtime memory usage, and fixed memory leaks that affected long-running applications. The result is a fast, reliable OCR tool that runs on any modern device.
How Tesseract OCR Extracts Text From Images
Tesseract.js is available on npm and supports both browser and Node.js environments. The API is straightforward — create a worker with createWorker(), then call worker.recognize(image) to extract text. For high-throughput applications, the Scheduler pattern allows you to distribute OCR jobs across multiple workers for parallel processing, making it practical for batch document scanning or real-time video text extraction.
The library works with webpack, ESM imports, and CDN script tags. Language data files are loaded on demand from a CDN and cached locally, so only the languages you actually use are downloaded. Developers building document scanning apps, receipt processors, accessibility tools, or content extraction pipelines will find Tesseract.js a production-ready solution that eliminates the need for paid cloud OCR services. For PDF text extraction, the team recommends Scribe.js, a companion project built on the same OCR foundation.
How It Works
Upload an image, paste from clipboard, or drag and drop.
Select the language and click Extract Text to run OCR locally.
Copy the extracted text or download it as a file.
Automated document processing.
OCR, data extraction, classification. Thousands of documents per hour, zero manual work.
Key Features
Privacy & Trust
Use Cases
Limitations
- Accuracy depends on image quality and clarity
- Handwritten text recognition is limited
- Very large images may be slow on older devices
- Complex layouts (tables, multi-column) may not preserve formatting
- Initial language data download may take a few seconds on first use
- Does not support PDF files directly
Q&A SESSION
Got a question about OCR or document processing?
Struggling with accuracy, multi-language, or scaling? One conversation can unblock you.
Frequently Asked Questions
Is this image-to-text OCR tool completely free?
Yes, it is 100% free with no image limits, no watermarks, and no signup. Cloud OCR services like Google Cloud Vision, AWS Textract, and Adobe Acrobat charge per page or per API call. Because this tool runs Tesseract.js locally in your browser, there are no server costs, so you can extract text from as many images as you need without paying anything.
Is my image sent to a server or stored anywhere?
No. All OCR processing happens entirely inside your browser using WebAssembly — your images never leave your device. There are no API calls, no uploads, and no analytics on your image content. This makes it safe for extracting text from confidential documents, medical records, legal contracts, financial statements, or any image you would not want uploaded to a third-party server. You can verify this by watching the Network tab in DevTools during extraction.
What is Tesseract.js and how reliable is it?
Tesseract.js is a JavaScript port of the Tesseract OCR engine, originally developed at Hewlett-Packard Labs in the 1980s and maintained by Google for over a decade. It is the most widely used open-source OCR library for the web. The underlying Tesseract engine is used in production by companies worldwide for document digitization, and the JavaScript port brings the same recognition accuracy directly to your browser via WebAssembly.
What image formats does the OCR tool support?
The tool accepts JPG, PNG, BMP, WEBP, and GIF formats — covering virtually every image type you encounter in daily use. JPG and PNG deliver the best OCR results because they preserve text clarity, especially at resolutions above 300 DPI. WEBP files from web screenshots also work well. GIF support is included, but animated GIFs will only process the first frame. For scanned documents, save as PNG at 300+ DPI for optimal text extraction accuracy.
Which languages does the OCR support?
Tesseract.js supports over 100 languages including English, Spanish, French, German, Portuguese, Italian, Dutch, Russian, Arabic, Chinese (Simplified and Traditional), Japanese, Korean, Hindi, Thai, Vietnamese, and many more. You select the language before extraction so the engine loads the appropriate trained data. For documents with mixed languages, select the primary language — the engine will still attempt to recognize characters from other scripts it encounters.
Can this tool extract text from handwritten notes?
Tesseract.js is optimized for printed text and performs best with typed, machine-generated characters. It can recognize neat, clearly written block letters with moderate accuracy, but cursive handwriting, messy notes, or stylized handwriting will produce poor results. For handwriting recognition, dedicated handwriting OCR services using neural networks (like Google Cloud Vision Handwriting or Apple Live Text) perform significantly better, though they require cloud processing.
Why is the first text extraction slower than subsequent ones?
On first use, the tool downloads the trained language data file for your selected language — about 4MB for English, up to 15MB for Chinese or Japanese. This file is cached in your browser, so all subsequent extractions are nearly instant because the data loads from local cache rather than the network. If you switch to a new language, that language's data will download once as well.
Can I paste an image directly from my clipboard?
Yes, and this is often the fastest workflow. Press Ctrl+V (Windows/Linux) or Cmd+V (Mac) to paste a screenshot or copied image directly into the tool. This is especially useful for quickly grabbing text from screenshots of emails, chat messages, error dialogs, presentation slides, or any on-screen content. The pasted image is processed immediately without needing to save a file first.
Does the OCR tool work on phones and tablets?
Yes. The tool works on any modern mobile or desktop browser. On phones, you can take a photo of a document, receipt, or sign, then upload it directly for text extraction. The camera on modern smartphones produces images with more than enough resolution for accurate OCR. Performance is good even on older devices because the Tesseract.js engine is well-optimized for mobile WebAssembly.
How does this compare to Google Lens, Apple Live Text, or Adobe OCR?
Google Lens and Apple Live Text use proprietary neural-network OCR that runs on Google/Apple servers or their custom chips, and they often achieve slightly higher accuracy on difficult images (poor lighting, unusual fonts, handwriting). Adobe Acrobat OCR is highly accurate but requires a paid subscription. This tool uses the open-source Tesseract engine, which is competitive for clean printed text but may lag behind on challenging inputs. The key advantage here is complete privacy — your images never leave your device — and zero cost.
How do I get the best OCR results from this tool?
For optimal accuracy, use clear images with high contrast between text and background. Ensure text is not skewed or rotated — straight, level text produces the best results. Crop the image tightly around the text area to reduce noise and speed up processing. For scanned documents, 300 DPI or higher resolution is ideal. Avoid images with heavy compression artifacts (low-quality JPGs), watermarks over text, or decorative fonts, as these reduce recognition accuracy significantly.
Can I extract text from screenshots of code, emails, or chat messages?
Yes, screenshots are among the best inputs for OCR because they contain clean, high-contrast, machine-rendered text. This works excellently for capturing code from images or videos, extracting text from email screenshots, copying messages from chat apps that do not allow text selection, and grabbing content from presentation slides. Take a screenshot and paste it directly with Ctrl+V / Cmd+V for the fastest workflow.
Does this tool support extracting text from PDF files?
This tool does not support PDF files directly — it works with image formats (JPG, PNG, BMP, WEBP, GIF). If you need to extract text from a scanned PDF, take a screenshot of the relevant pages or convert the PDF pages to images first using any free PDF-to-image converter, then upload those images here. For PDFs that already contain selectable text (not scanned), you do not need OCR at all — just copy and paste the text directly from the PDF.
AI Agents Orchestration
To Run Your Business on Autopilot
I'm building a modern AI workforce for deploying autonomous AI agents at scale. Live since 15 April 2026 at www.sistava.com.
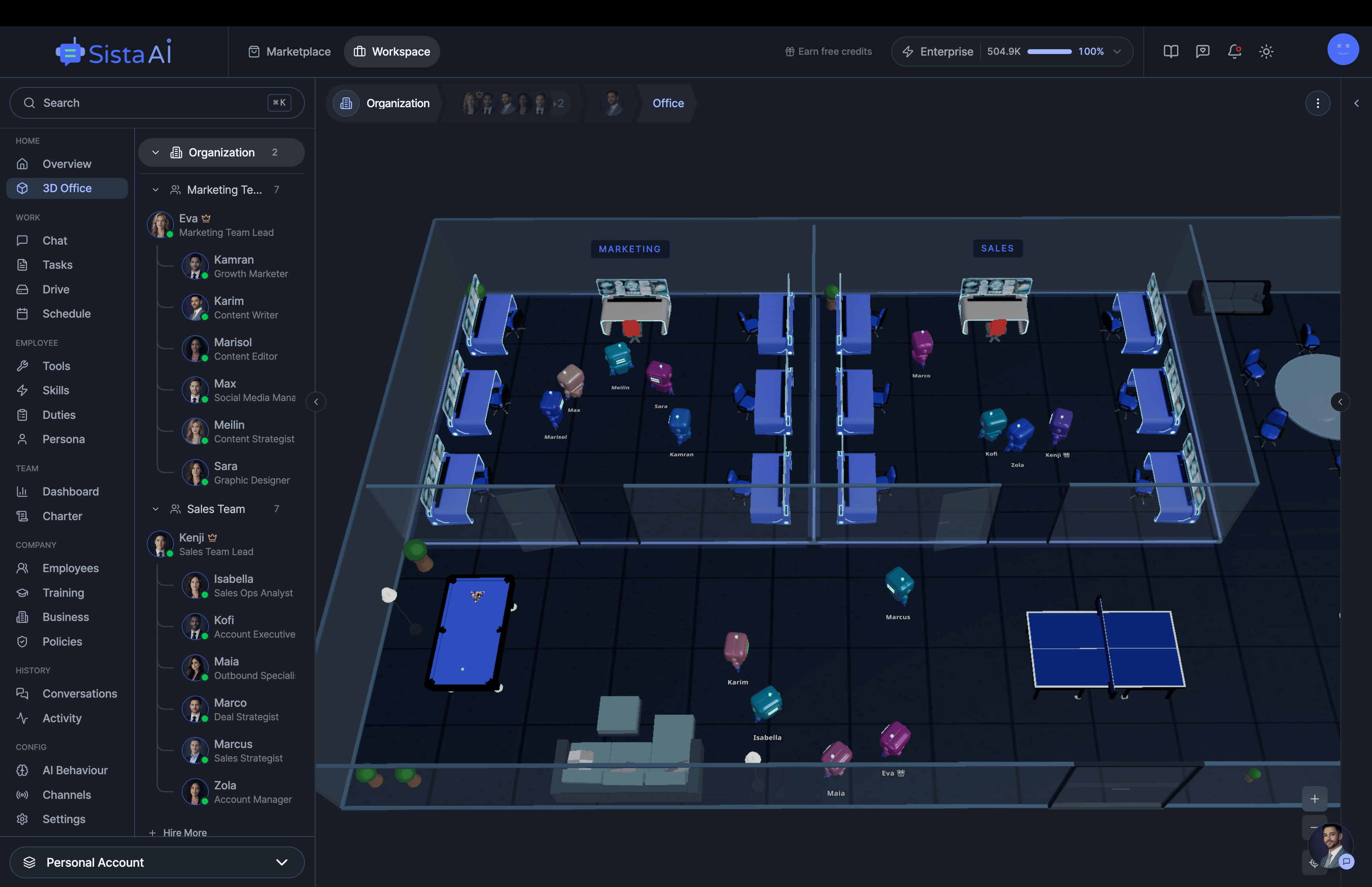
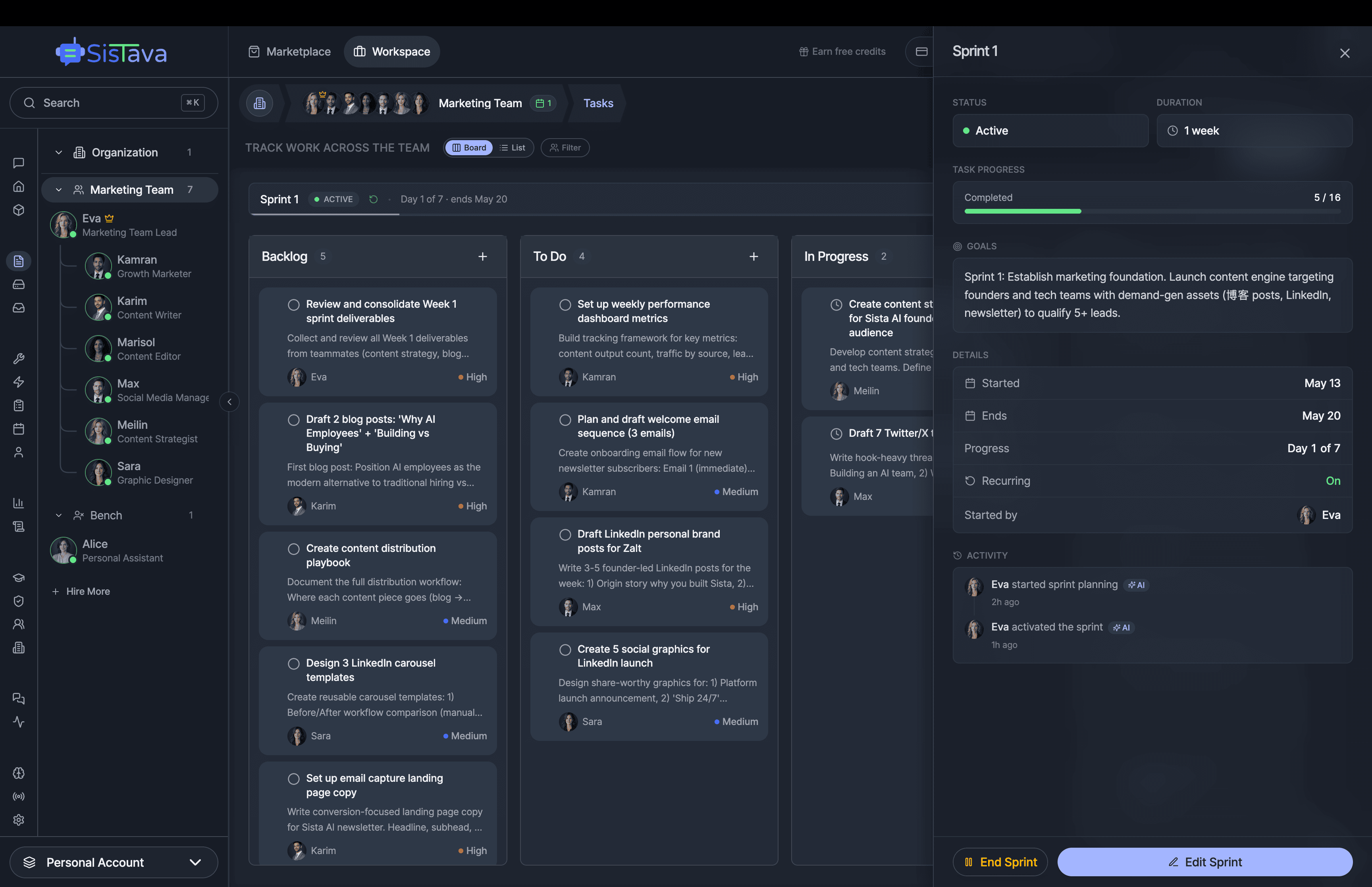
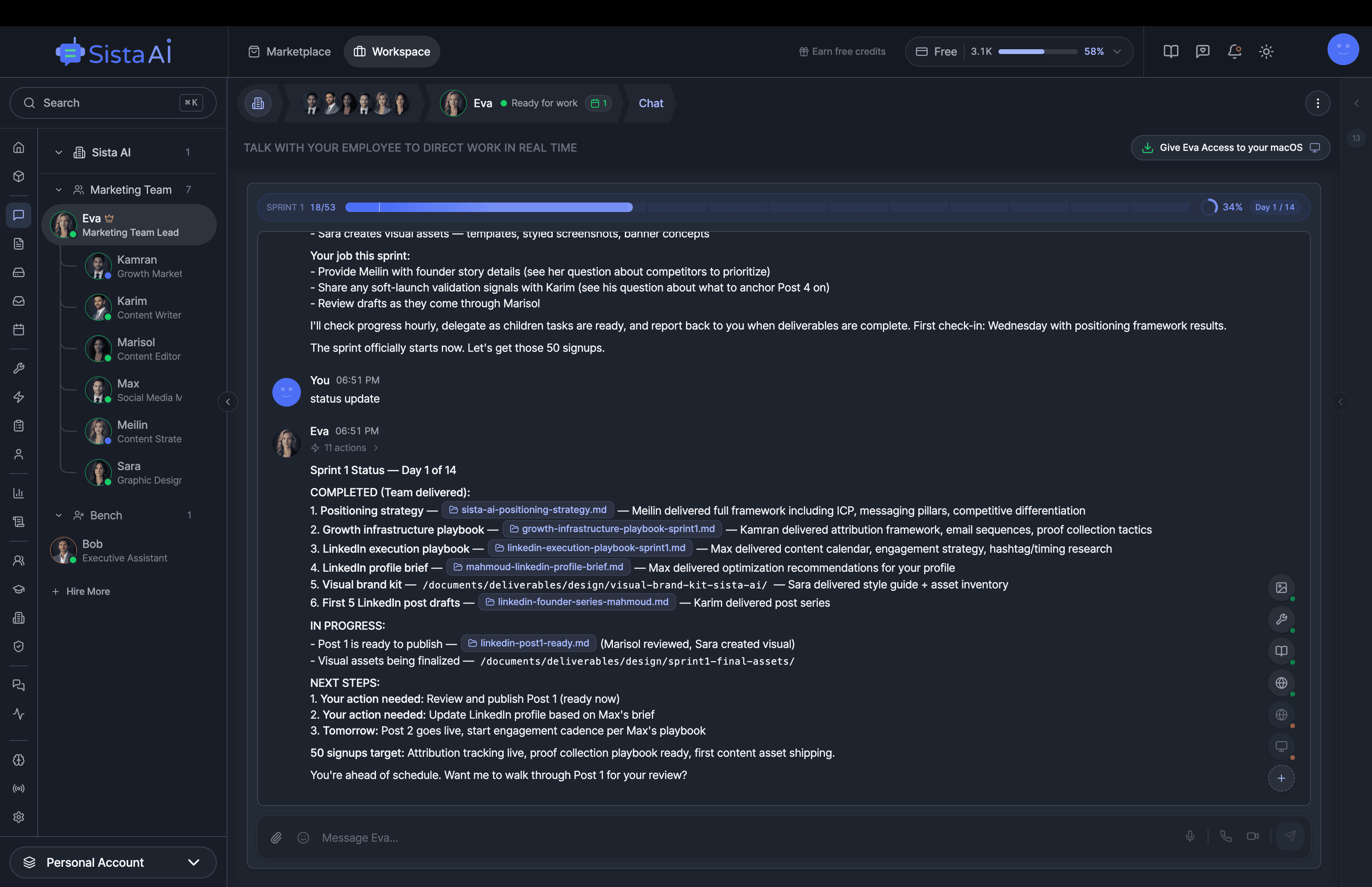
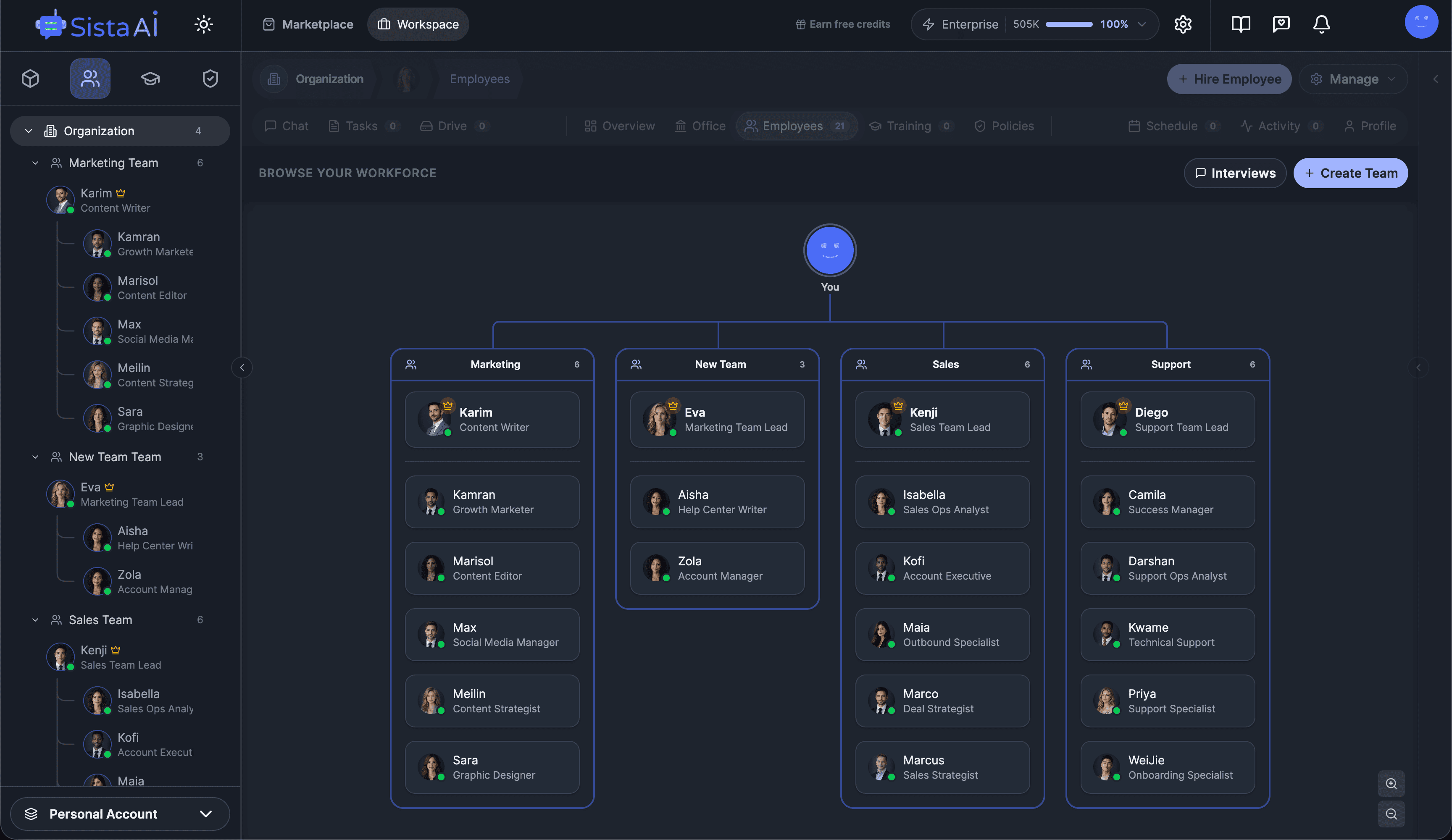

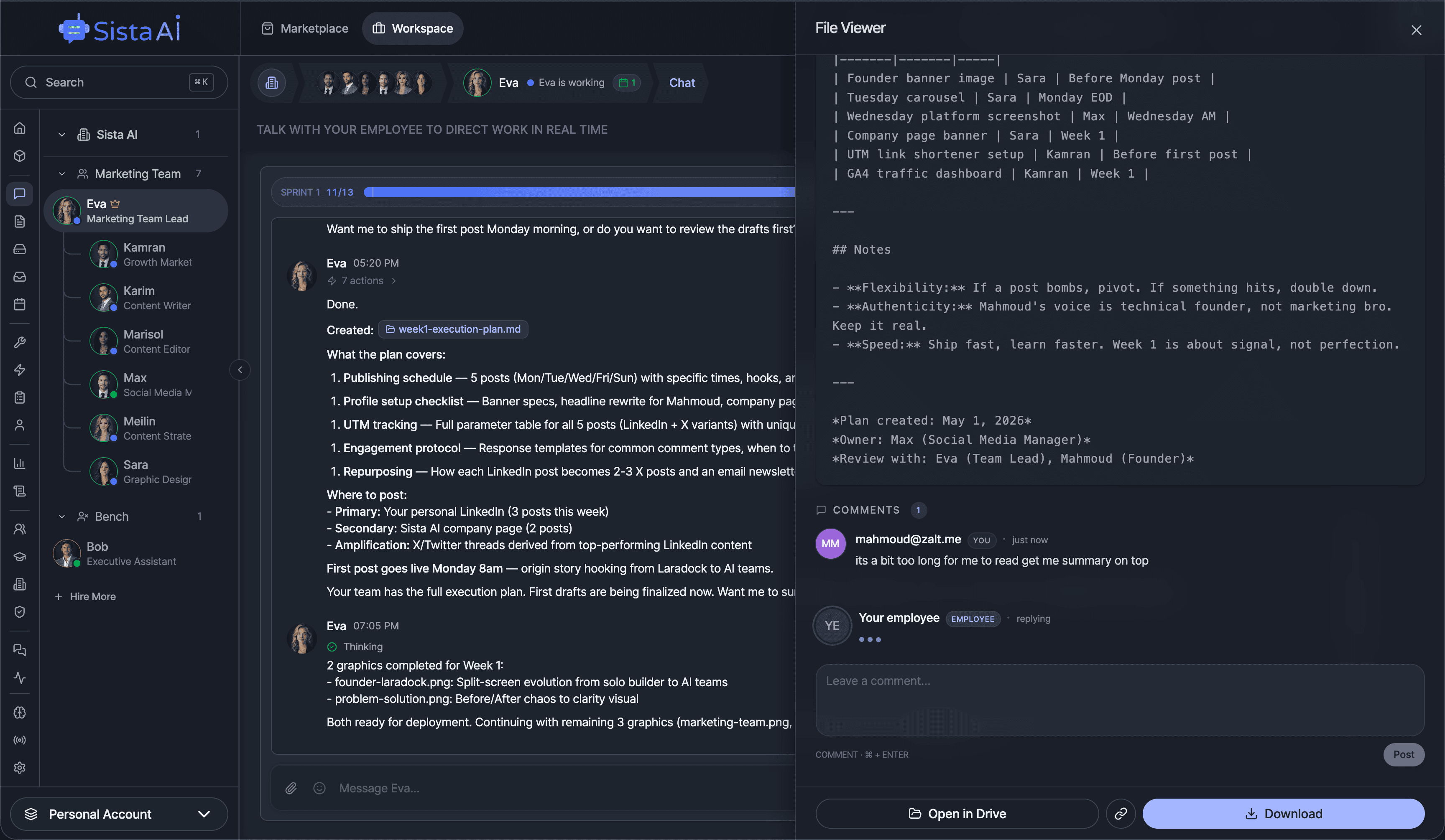
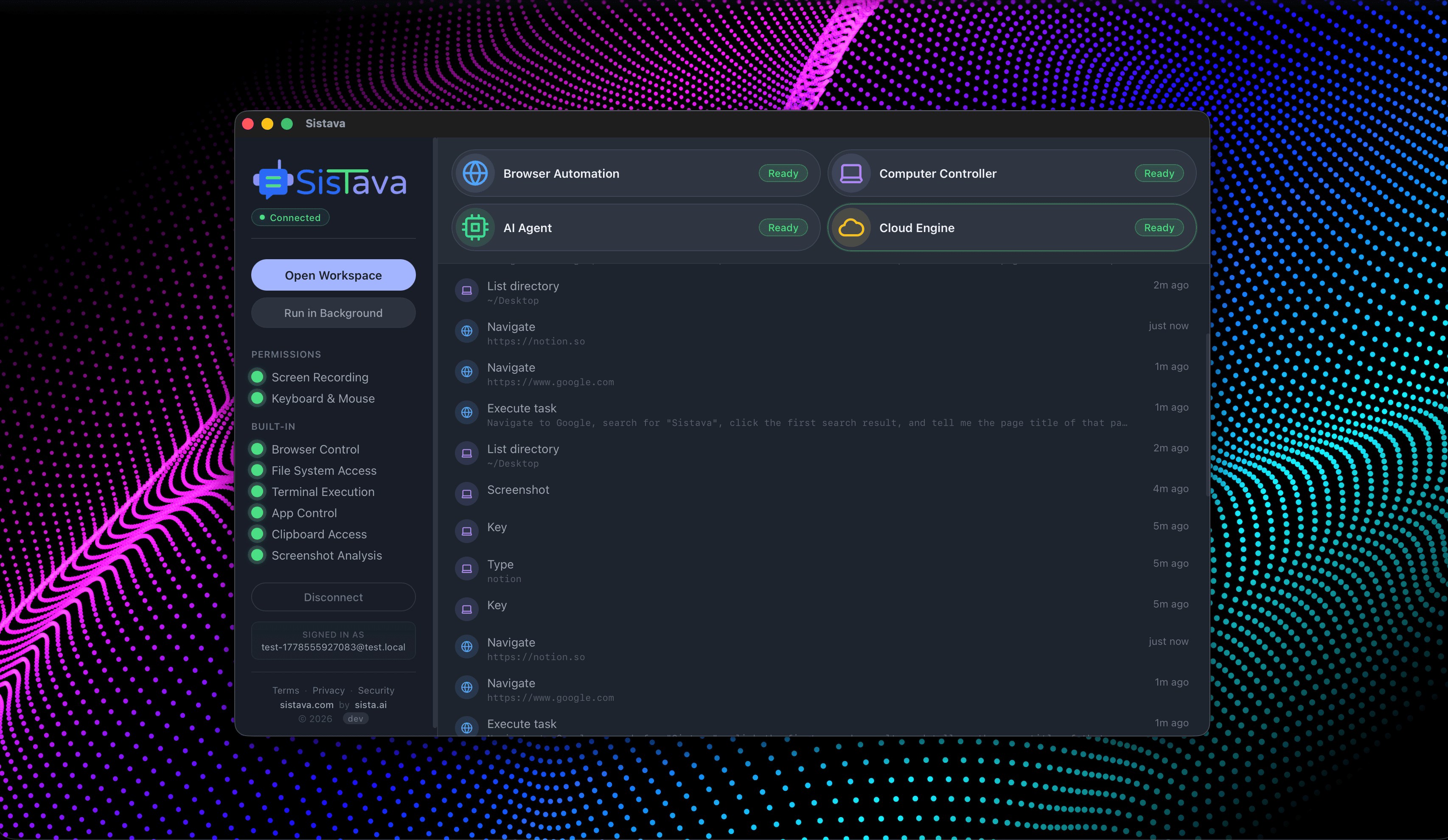
If you're a solo founder looking for AI agents to handle sales, marketing, and ops, check it out, You'll find it valuable. I use it myself to run my business. Your feedback is appreciated.
Building something similar? Let's exchange some knowledge.- Sales outreach
- Persistent memory
- Marketing automation
- MCP integrations
- Browser automation
- RAG knowledge base
- Meeting summaries
- Custom guardrails
- Computer control
- Multi-agent teams
- Ops & admin
- 3D office view