One of 55 free AI tools built by Zalt, an AI architect and consultant with 16 years of experience.
Free AI Vision Detector
Real-time AI vision detection powered by Google MediaPipe — the same technology used in Google Meet, YouTube, and Android. Detect faces, hands, body poses, and objects using your webcam or uploaded images. All processing runs locally in your browser via WebAssembly and WebGL. No signup, no server, no API calls. Your camera feed never leaves your device.
Loading AI Vision Detector...
Hire AI Employees
Hire AI Employees that work 24/7. No code.Are you a solo founder still doing sales, marketing, and support by hand? Hire AI Employees to run it all for you. They work 24/7, set up with no code, and go live in minutes.


More Free Tools
More than 20 free AI tools.

Hire AI Expert
Mahmoud Zalt · Freelance AI Engineer
What Is Google MediaPipe and How Does This Vision Detector Work?
This AI vision detector is powered by Google MediaPipe, an open-source framework for building on-device machine learning pipelines. MediaPipe is the same technology that powers face detection in Google Meet, background segmentation on YouTube, and AR features across Android and iOS. It provides production-grade computer vision models that run directly on your device with no cloud processing.
The tool supports four detection modes: face detection with 478 facial landmarks for detailed face mesh analysis, hand tracking with 21 landmarks per hand for gesture recognition, full body pose estimation with 33 skeletal landmarks, and general object detection that identifies common everyday objects with bounding boxes and confidence scores. All detection runs in real-time at 30+ frames per second on modern hardware using WebAssembly and WebGL acceleration.
Unlike cloud-based computer vision APIs from Google Cloud Vision, AWS Rekognition, or Azure Computer Vision that charge per image and require uploading your photos to external servers, this tool processes everything locally in your browser. Your camera feed and uploaded images never leave your device, making it suitable for privacy-sensitive applications like security prototyping, health monitoring research, or educational demonstrations.
How MediaPipe Vision Detection Works
MediaPipe is available on npm as @mediapipe/tasks-vision and supports deployment across Android, iOS, web, desktop, and edge devices. The framework provides three layers: MediaPipe Tasks for ready-to-use cross-platform APIs, MediaPipe Models for pre-trained ML models, and MediaPipe Model Maker for fine-tuning models with your own data. Developers can also use MediaPipe Studio to visualize and benchmark results directly in the browser before integrating into their applications.
The underlying MediaPipe Framework uses a graph-based pipeline architecture where data flows through configurable "calculators" — modular processing units that handle everything from image preprocessing to model inference to result visualization. This design makes it straightforward to chain multiple detectors, add custom post-processing, or build complex multimodal pipelines. Notable real-world integrations include SignAll SDK for sign language interfaces, Alfred Camera for smart home monitoring, and Mirru for prosthesis control via hand tracking.
Need expert help with AI?
Looking for a specialist to help integrate, optimize, or consult on AI systems? Book a one-on-one technical consultation with an experienced AI consultant to get tailored advice.
Q&A SESSION
Got a quick technical question?
Skip the back-and-forth. Get a direct answer from an experienced engineer.
AI Agents Orchestration
To Run Your Business on Autopilot
I'm building a modern AI workforce for deploying autonomous AI agents at scale. Live since 15 April 2026 at www.sistava.com.
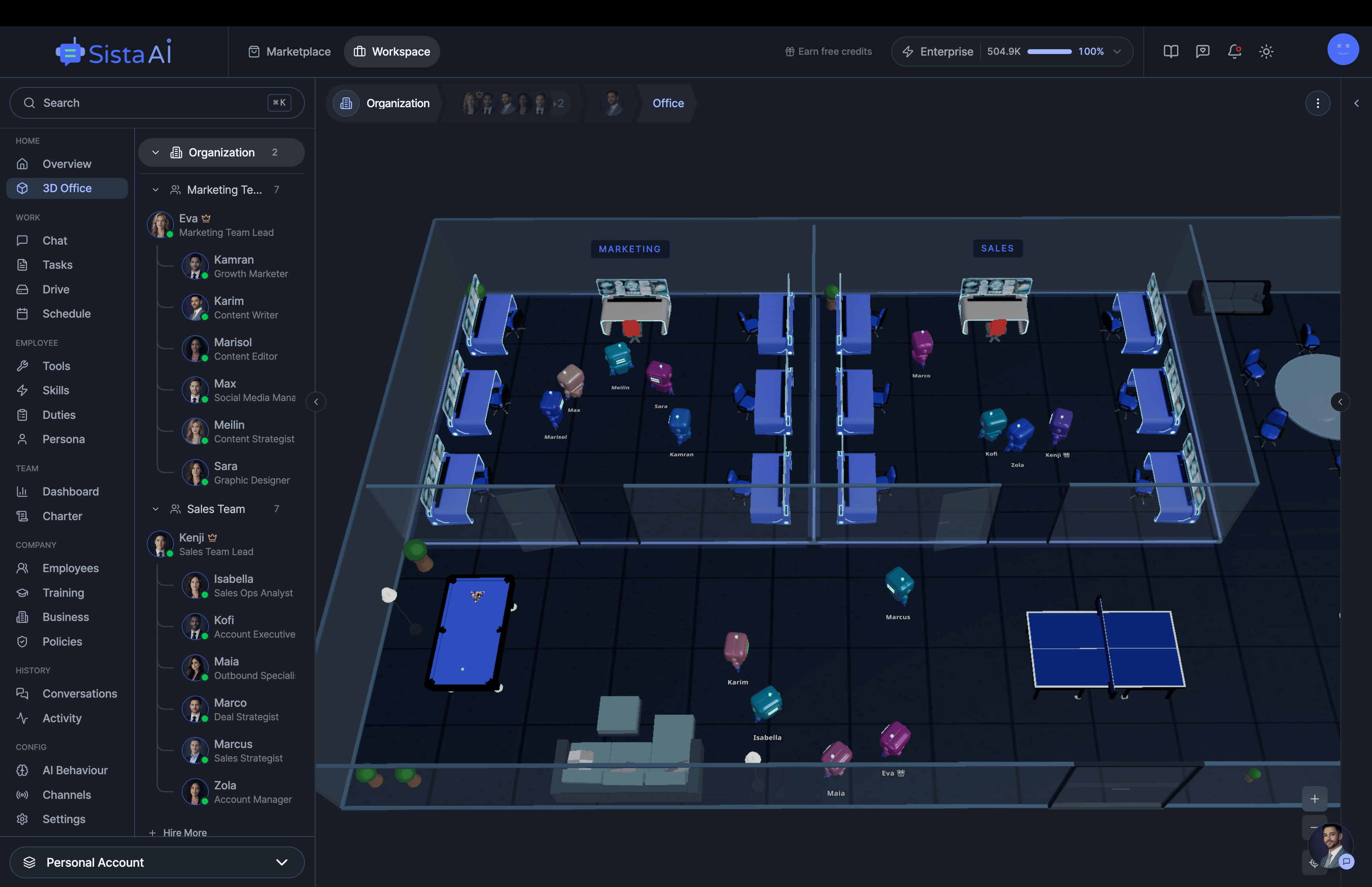
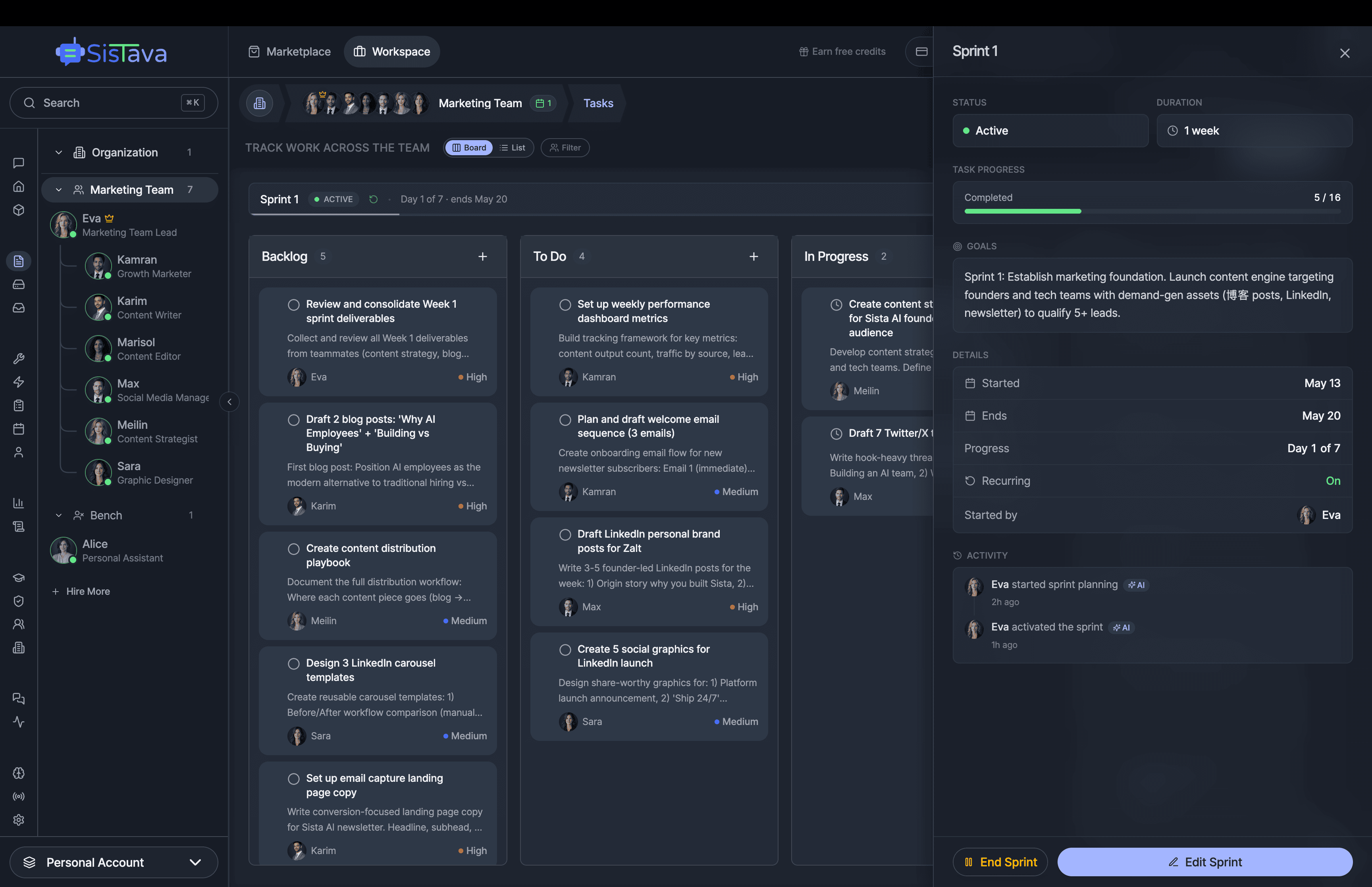
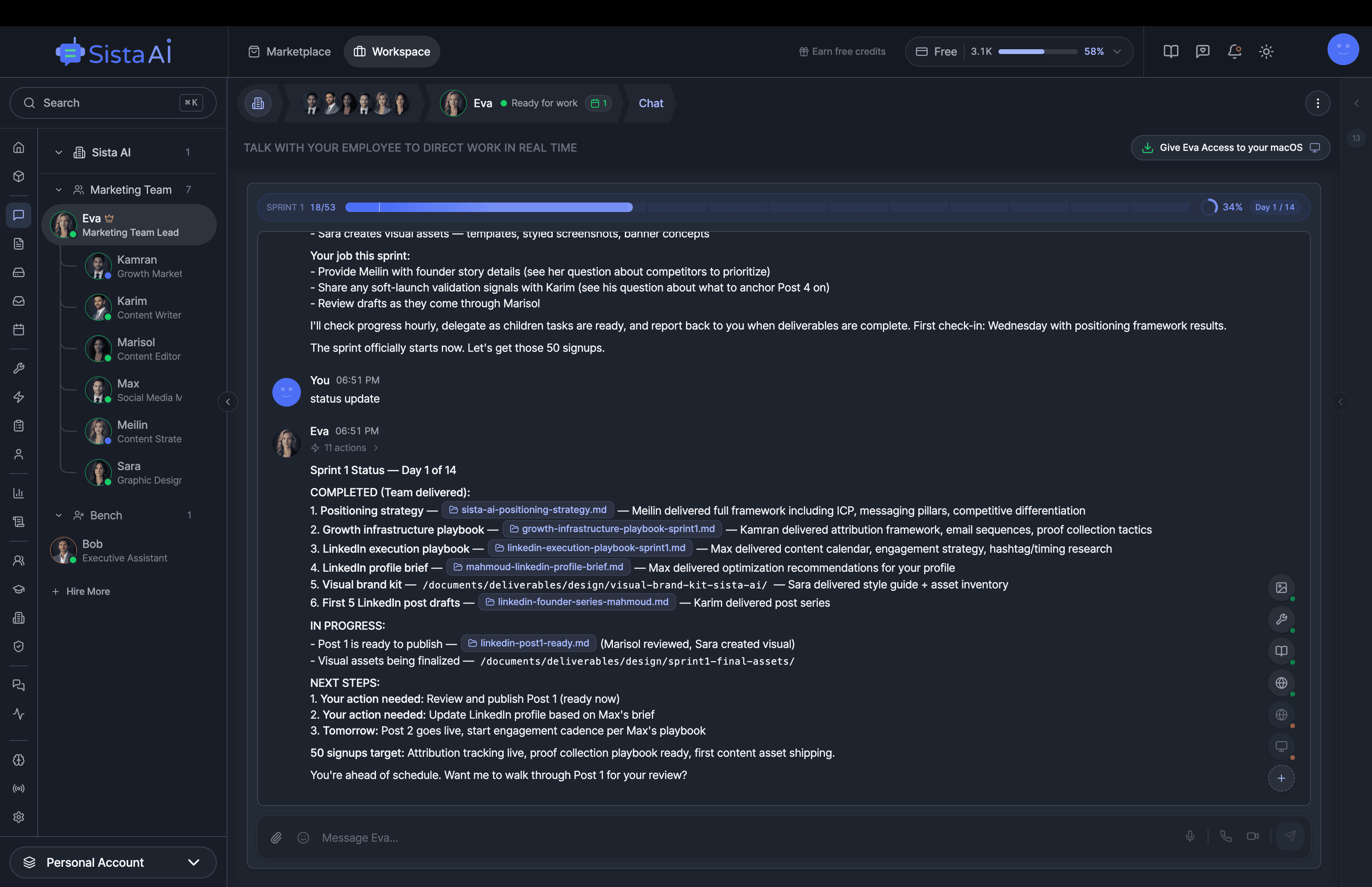
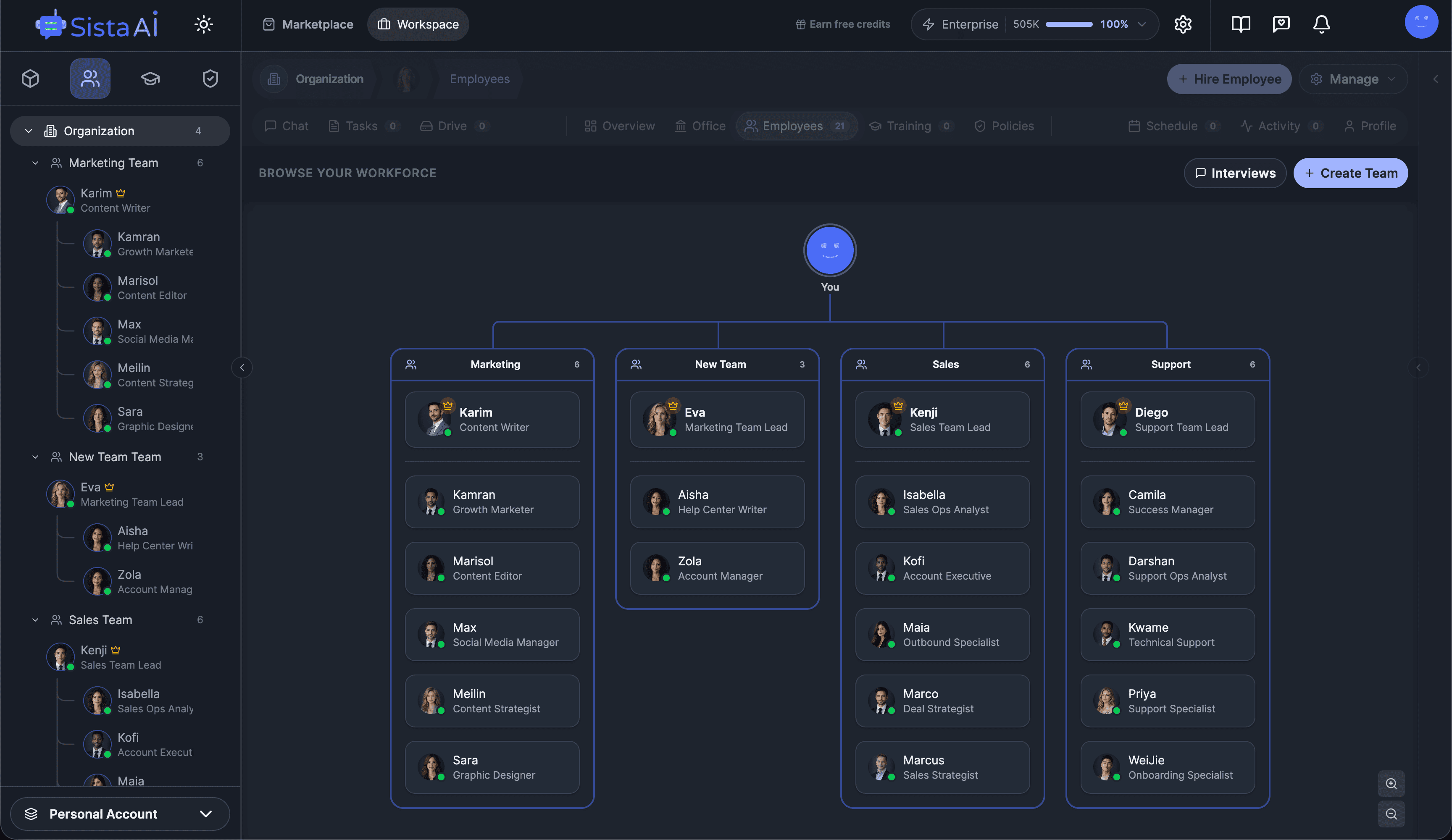
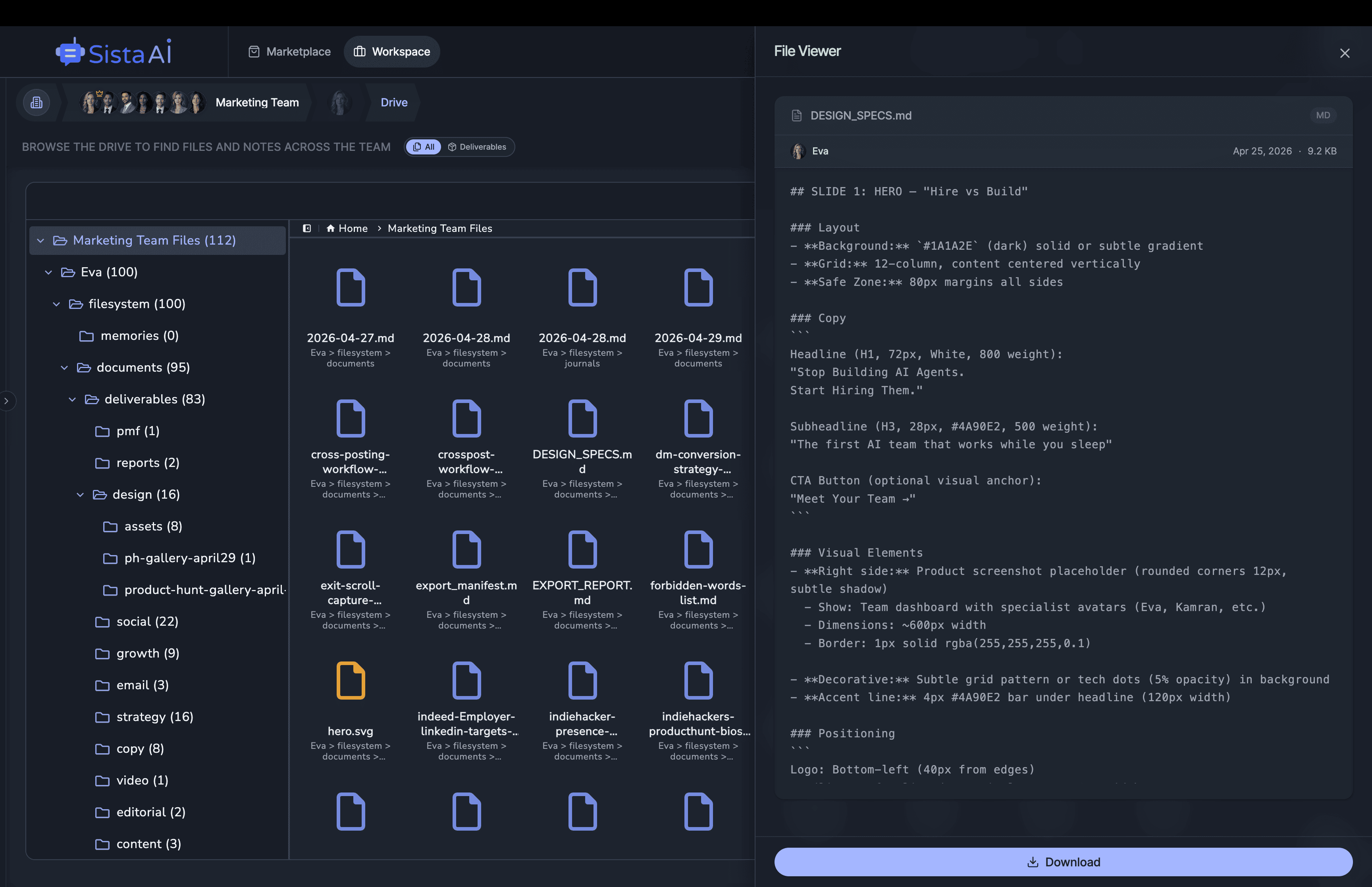
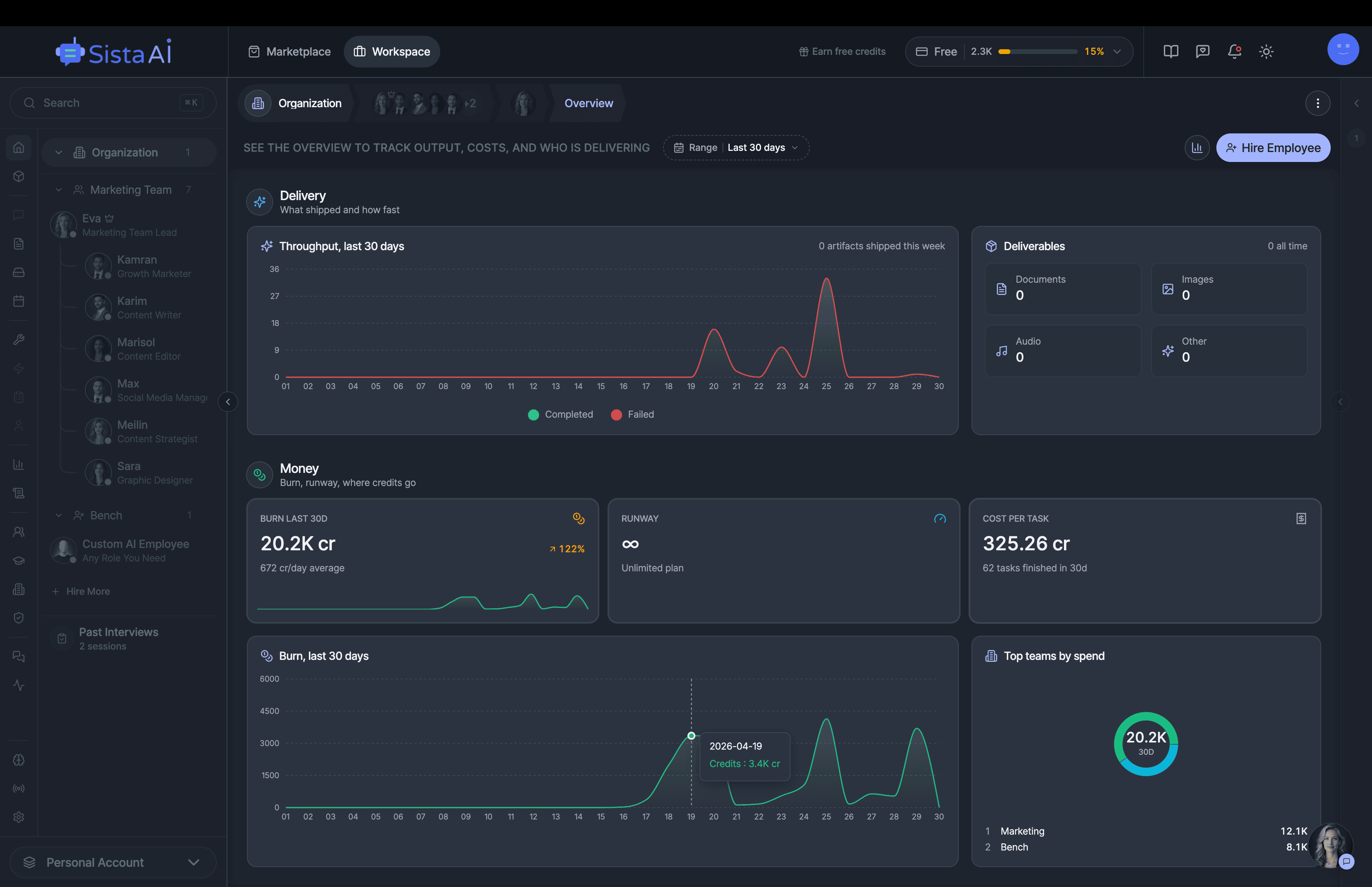

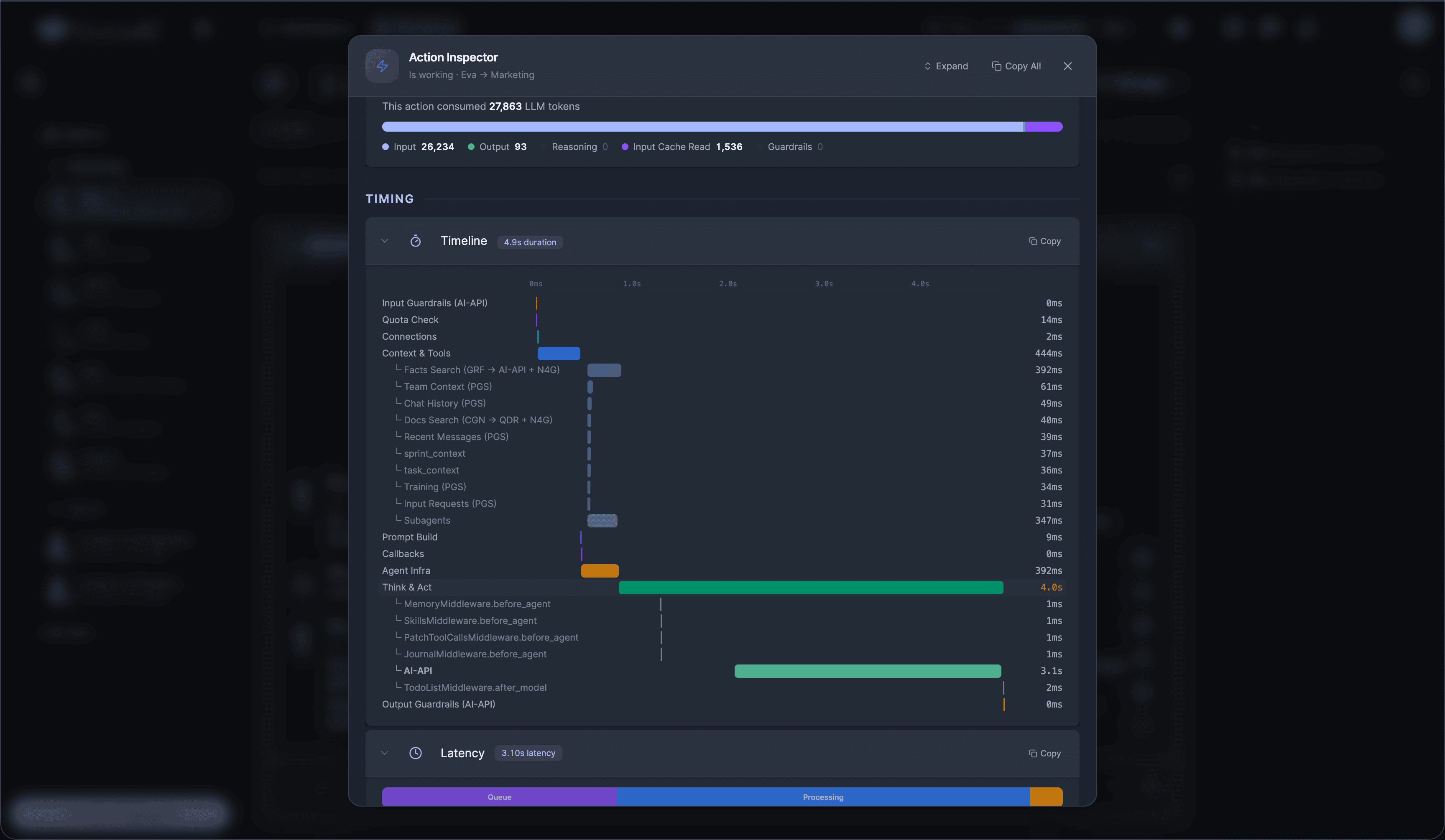
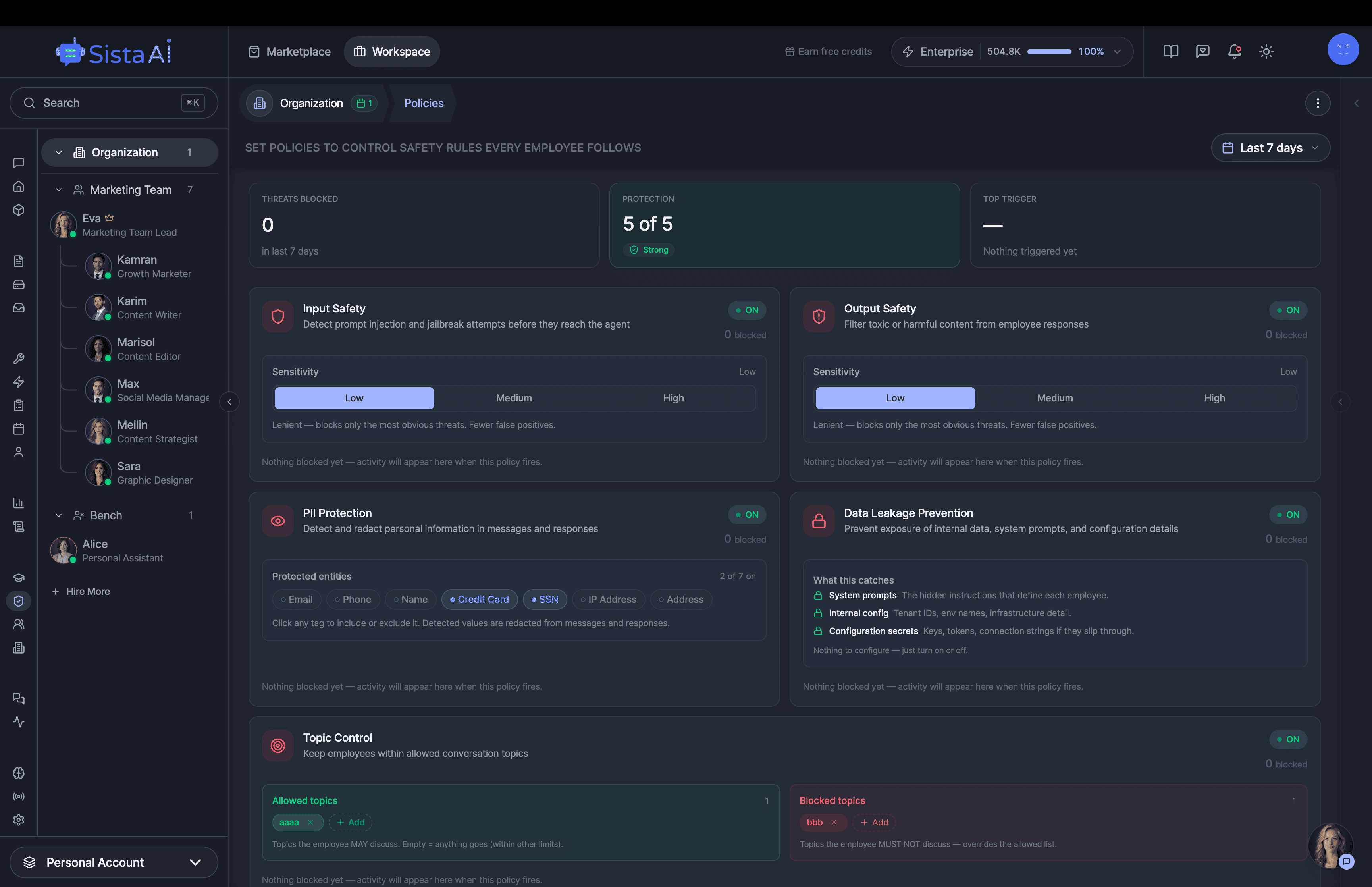
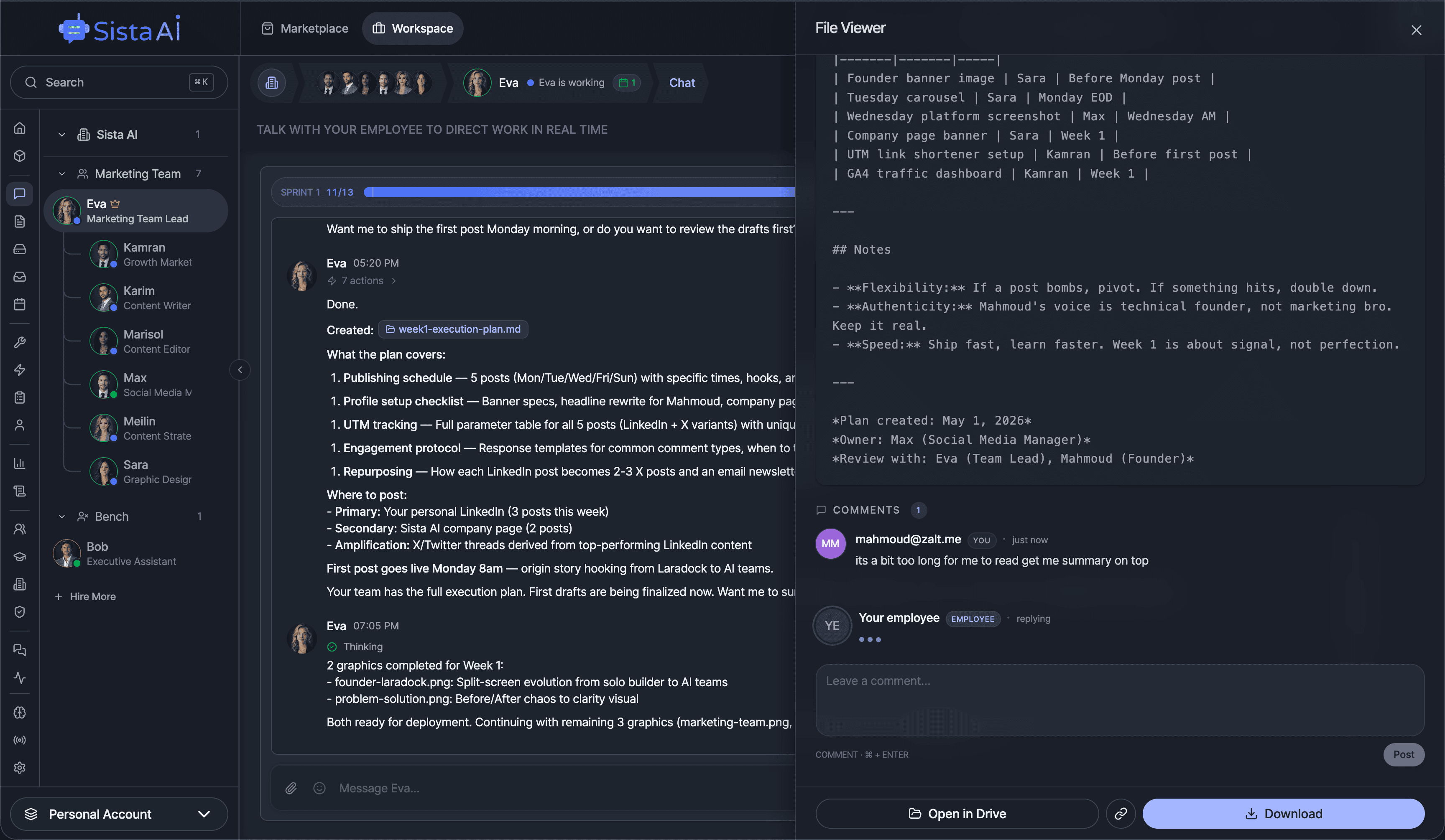
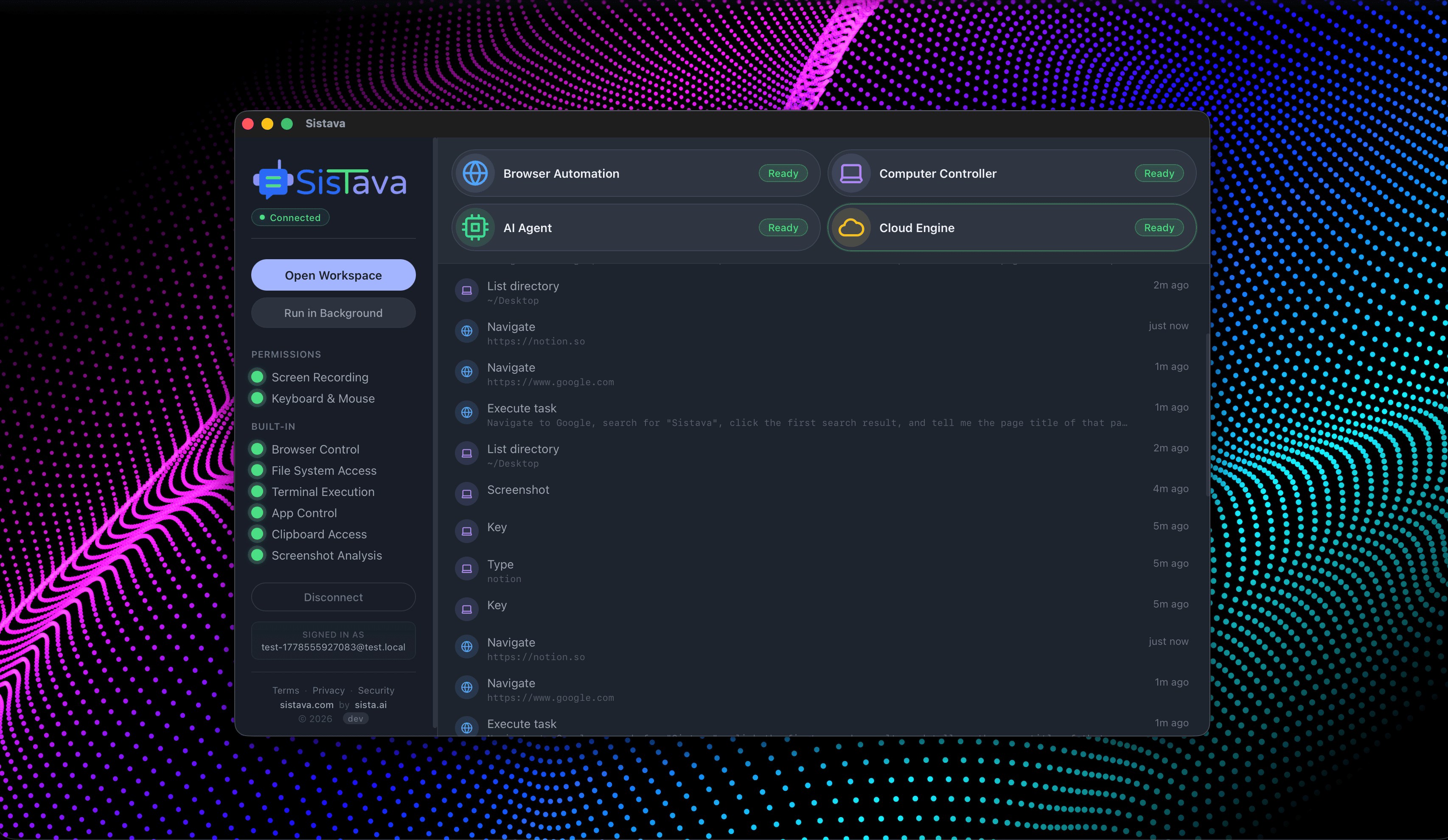
If you're a solo founder looking for AI agents to handle sales, marketing, and ops, check it out, You'll find it valuable. I use it myself to run my business. Your feedback is appreciated.
Building something similar? Let's exchange some knowledge.- Sales outreach
- Persistent memory
- Marketing automation
- MCP integrations
- Browser automation
- RAG knowledge base
- Meeting summaries
- Custom guardrails
- Computer control
- Multi-agent teams
- Ops & admin
- 3D office view
How It Works
Choose a detection mode — face, hands, pose, or object detection.
Use your webcam for real-time detection or upload an image.
See AI detections drawn live on screen with landmarks and labels.
Production computer vision.
Security, quality control, real-time analytics. Detection that runs at scale.
Key Features
Privacy & Trust
Use Cases
Limitations
- Performance depends on device GPU and browser support
- Best results with good lighting and clear visibility
- Object detection limited to common everyday objects
- Models download on first use (~5-7MB per detector)
- Multiple simultaneous detectors may reduce frame rate
- Mobile devices may have lower frame rates than desktop