One of 55 free AI tools built by Zalt, an AI architect and consultant with 16 years of experience.
Free Image to Text
Upload or paste an image and instantly extract all text from it using Tesseract.js, the most popular open-source OCR engine. Supports 100+ languages including English, Arabic, Chinese, Japanese, Korean, Hindi, and more. All processing happens locally in your browser — no signup, no server, no API calls. Your images stay on your device.
Loading OCR...
Hire AI Employees
Hire AI Employees that work 24/7. No code.Are you a solo founder still doing sales, marketing, and support by hand? Hire AI Employees to run it all for you. They work 24/7, set up with no code, and go live in minutes.


More Free Tools
More than 20 free AI tools.

Hire AI Expert
Mahmoud Zalt · Freelance AI Engineer
What Is Tesseract.js and How Does This OCR Tool Work?
This image-to-text tool is powered by Tesseract.js, the most popular open-source OCR library for the web. Tesseract.js is a JavaScript port of the Tesseract OCR engine, originally developed at Hewlett-Packard Labs in the 1980s and later maintained and improved by Google. It can extract text from images in over 100 languages, including English, Arabic, Chinese, Japanese, Korean, Hindi, Russian, and many more.
The engine runs entirely in your browser via WebAssembly — no server, no cloud processing, no API keys. You upload or paste an image, select the language, and the OCR engine analyzes pixel patterns to recognize characters and words. It works with JPG, PNG, BMP, WEBP, and GIF formats, and handles screenshots, photos of documents, receipts, signs, whiteboards, and scanned pages.
Tesseract.js v7 brings significant improvements over earlier versions: 54% smaller language files for English, 73% smaller for Chinese, approximately 50% faster initial load times, reduced runtime memory usage, and fixed memory leaks that affected long-running applications. The result is a fast, reliable OCR tool that runs on any modern device.
How Tesseract OCR Extracts Text From Images
Tesseract.js is available on npm and supports both browser and Node.js environments. The API is straightforward — create a worker with createWorker(), then call worker.recognize(image) to extract text. For high-throughput applications, the Scheduler pattern allows you to distribute OCR jobs across multiple workers for parallel processing, making it practical for batch document scanning or real-time video text extraction.
The library works with webpack, ESM imports, and CDN script tags. Language data files are loaded on demand from a CDN and cached locally, so only the languages you actually use are downloaded. Developers building document scanning apps, receipt processors, accessibility tools, or content extraction pipelines will find Tesseract.js a production-ready solution that eliminates the need for paid cloud OCR services. For PDF text extraction, the team recommends Scribe.js, a companion project built on the same OCR foundation.
Need expert help with AI?
Looking for a specialist to help integrate, optimize, or consult on AI systems? Book a one-on-one technical consultation with an experienced AI consultant to get tailored advice.
Q&A SESSION
Got a quick technical question?
Skip the back-and-forth. Get a direct answer from an experienced engineer.
AI Agents Orchestration
To Run Your Business on Autopilot
I'm building a modern AI workforce for deploying autonomous AI agents at scale. Live since 15 April 2026 at www.sistava.com.
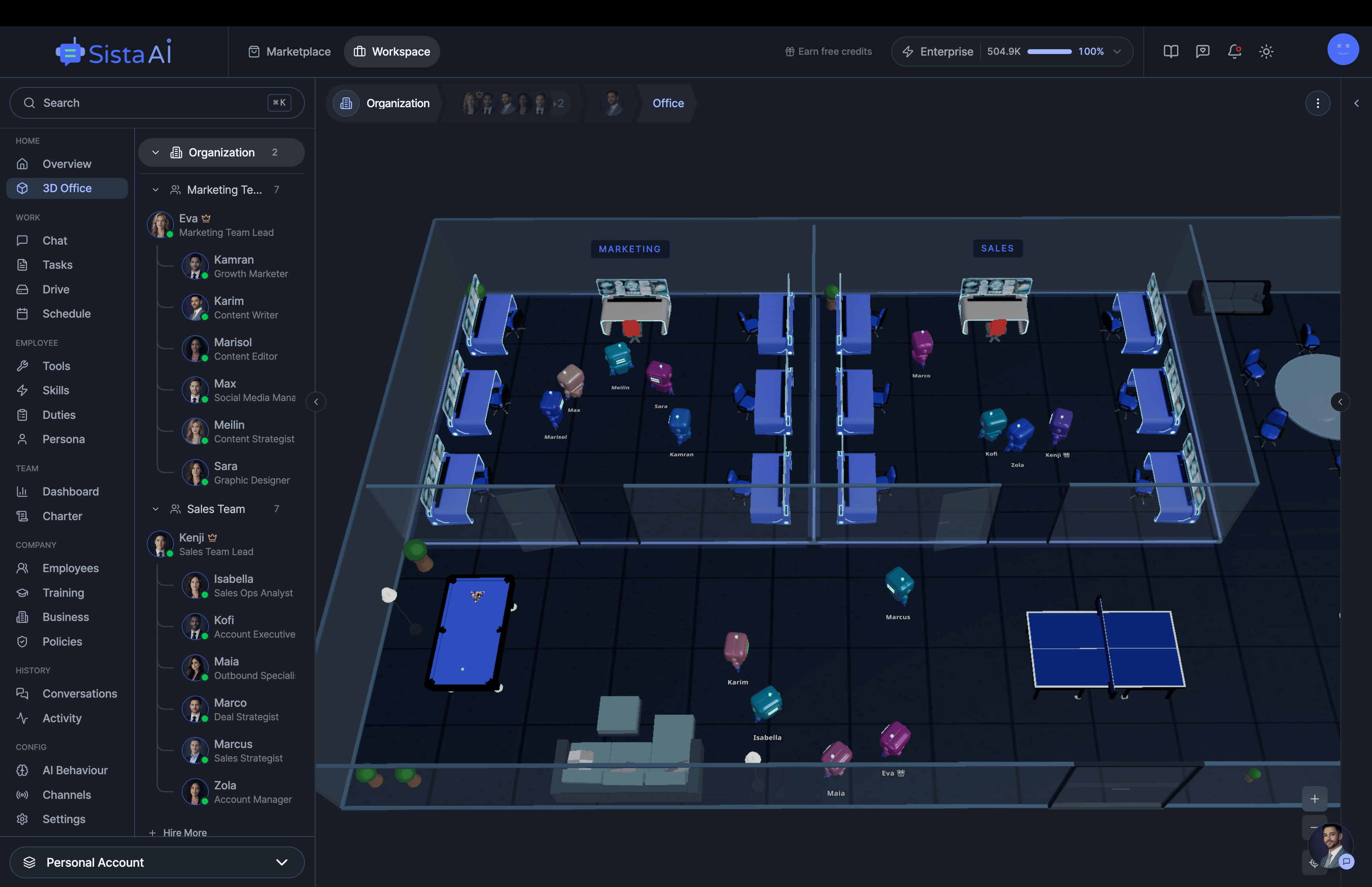
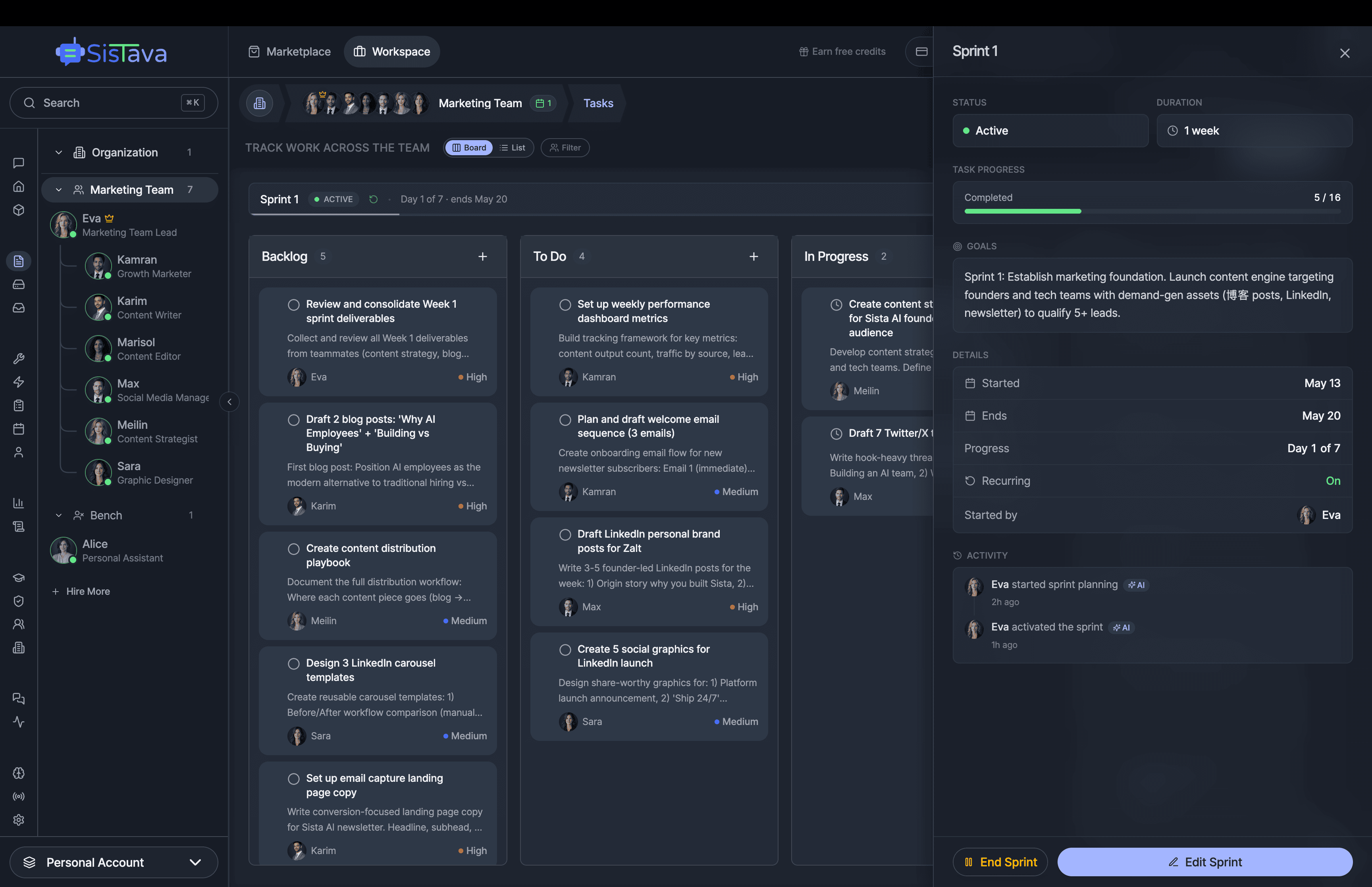
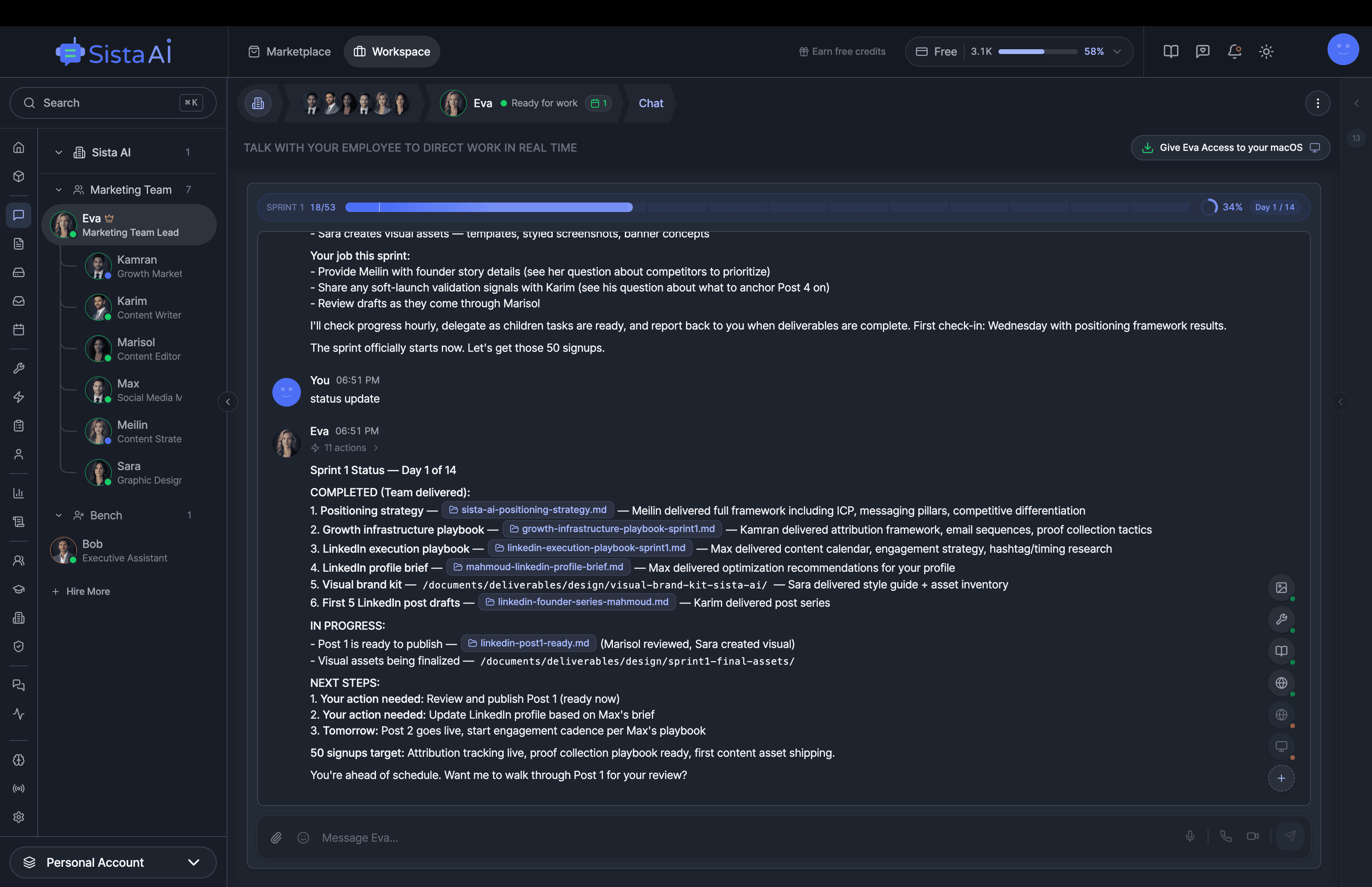
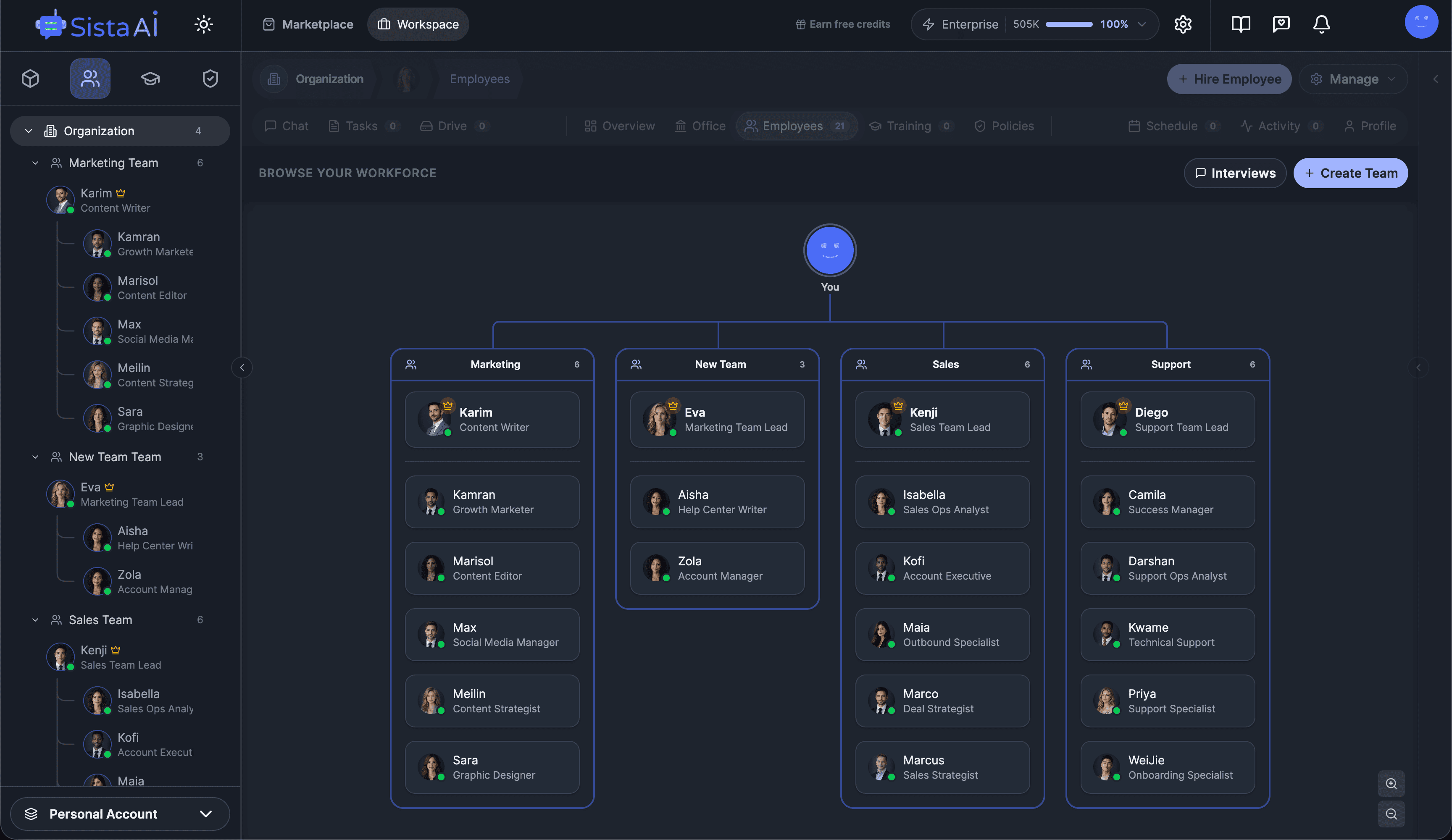
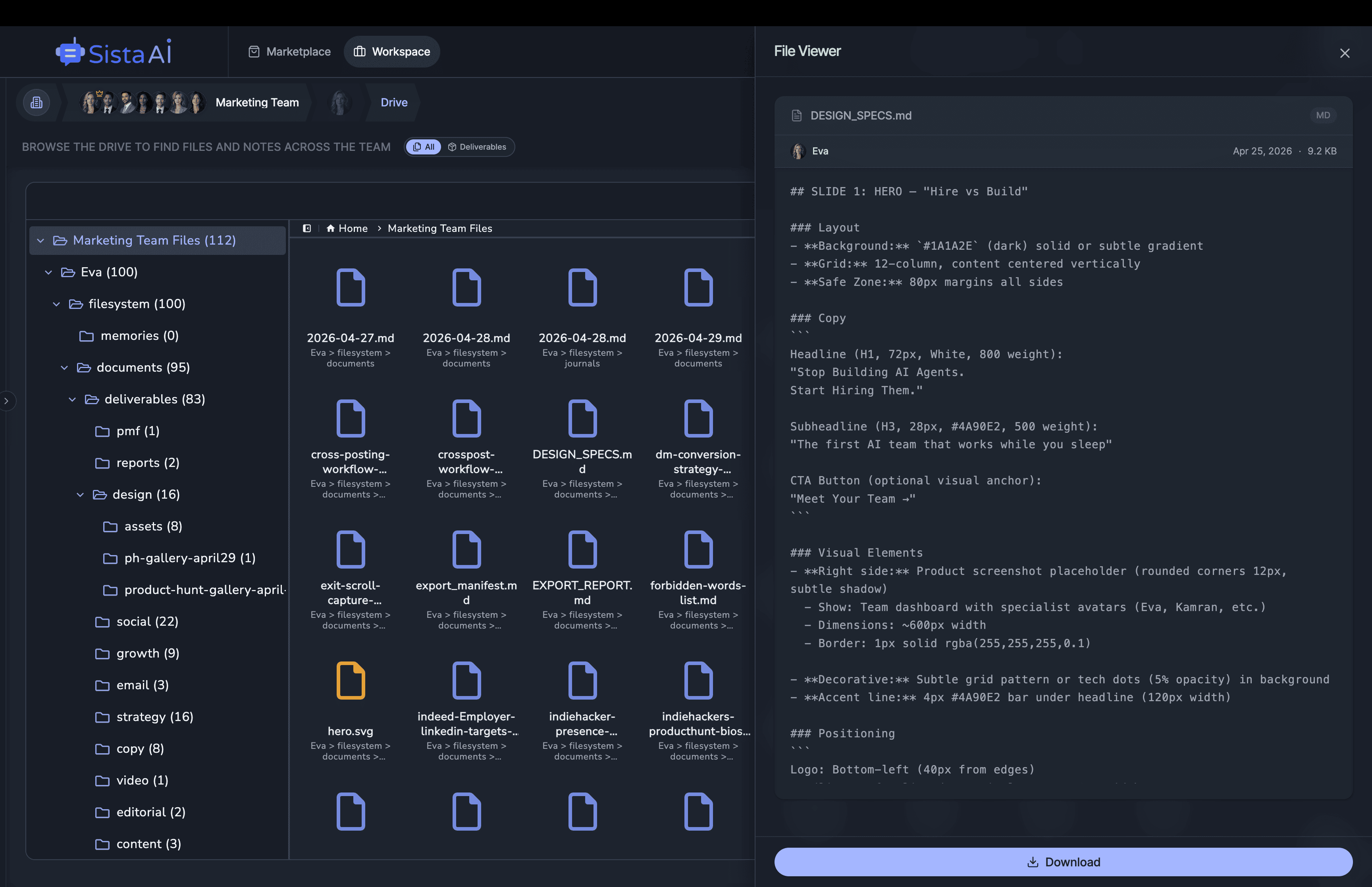
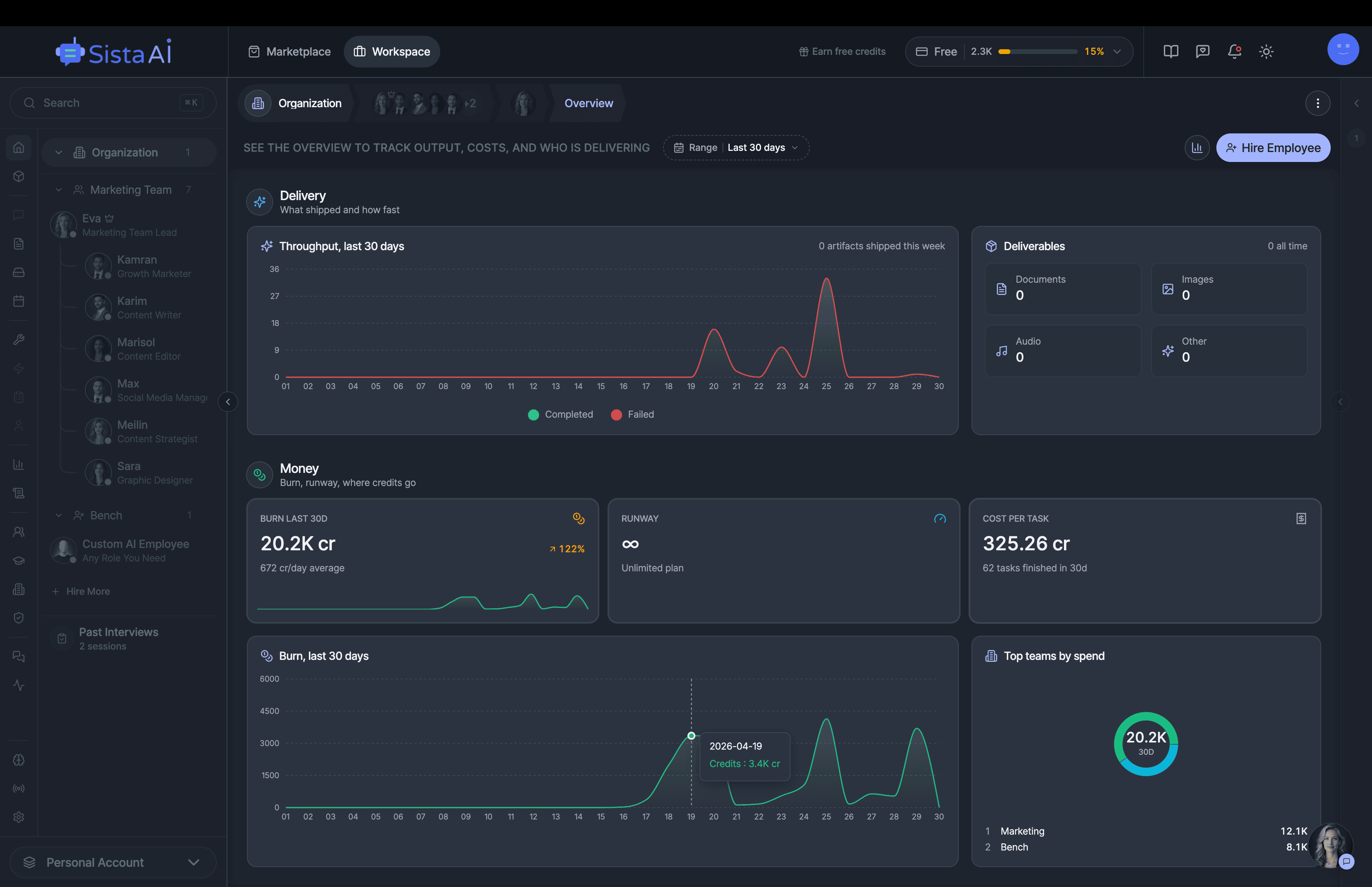

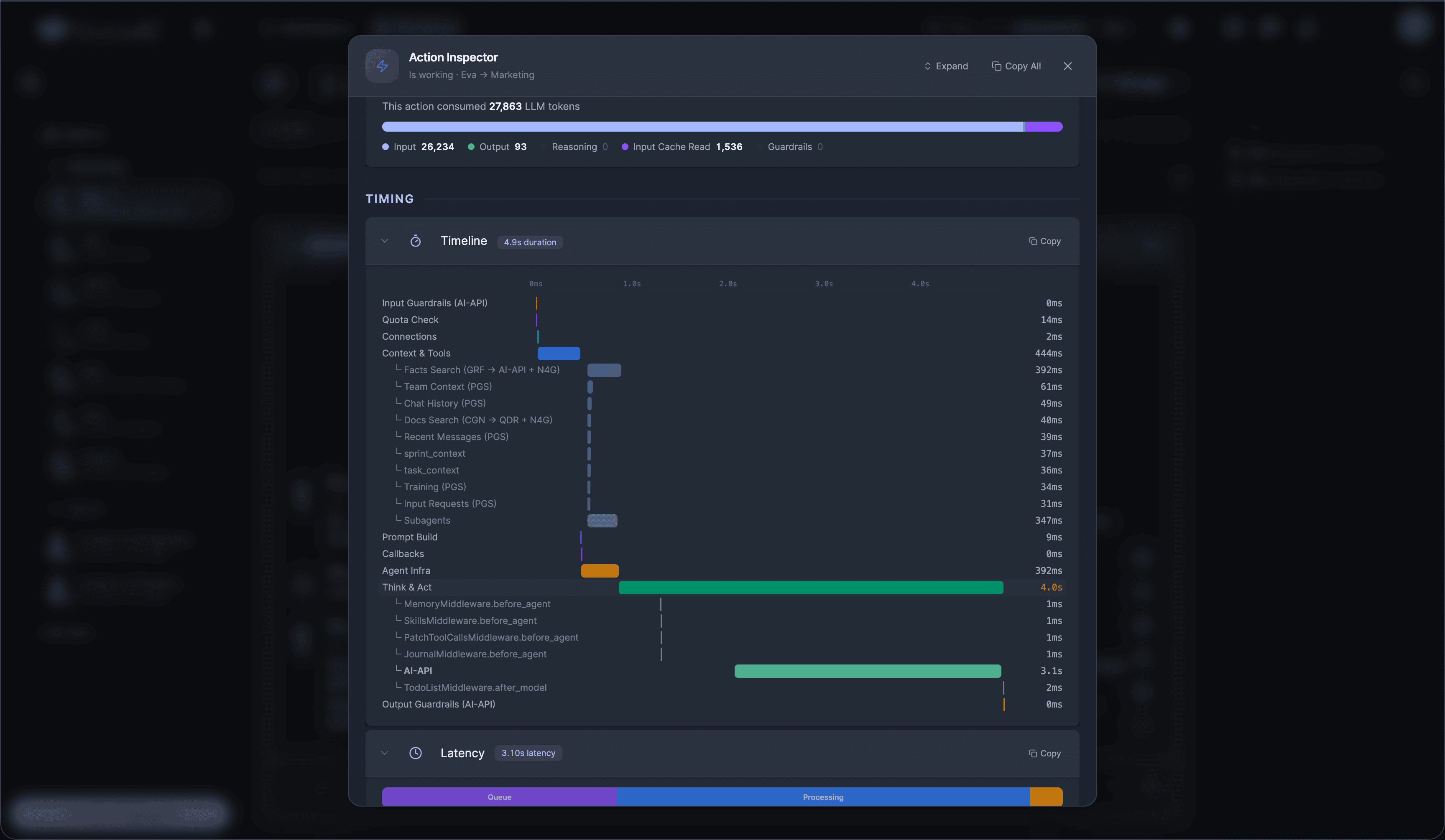
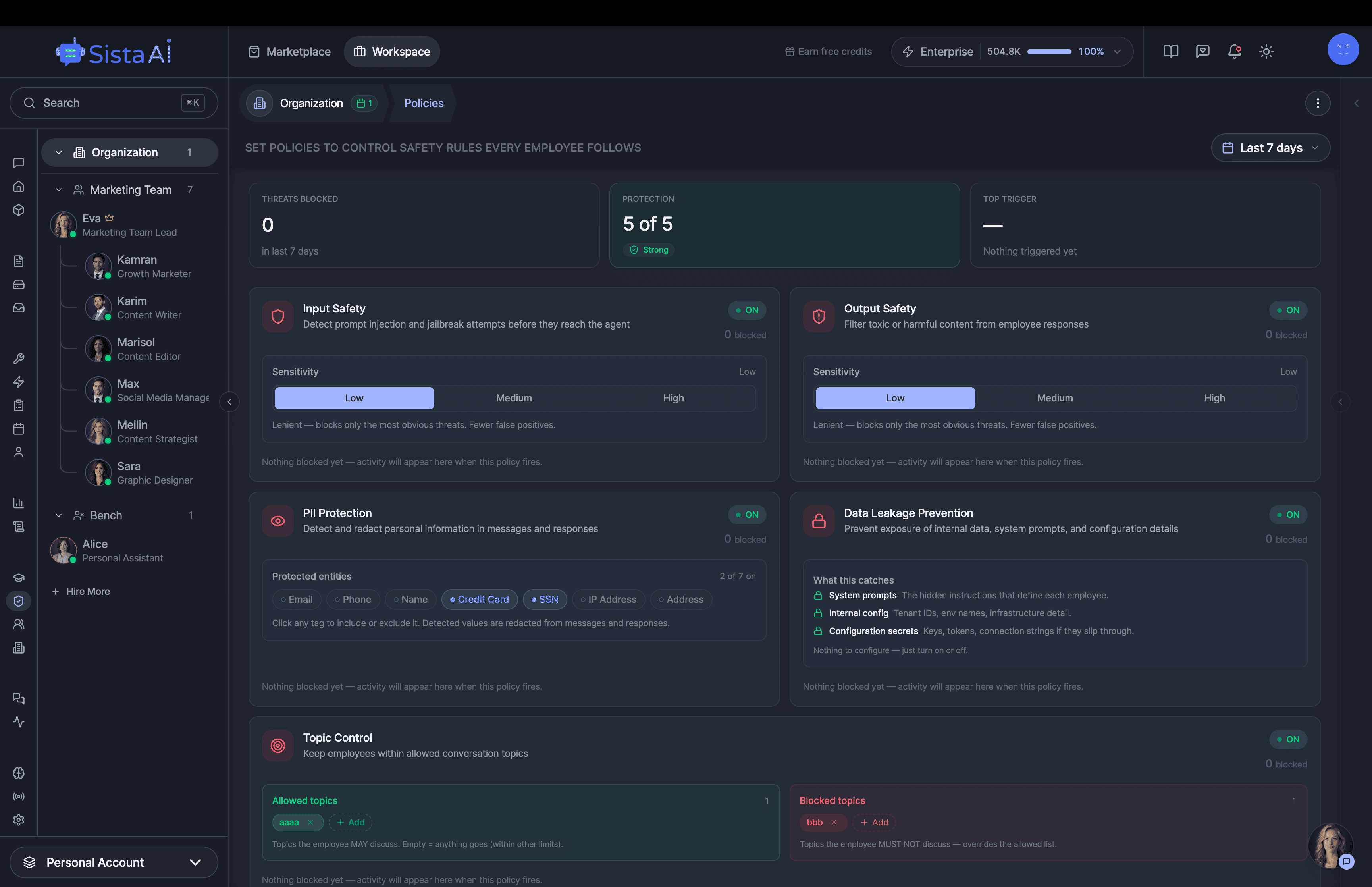
If you're a solo founder looking for AI agents to handle sales, marketing, and ops, check it out, You'll find it valuable. I use it myself to run my business. Your feedback is appreciated.
Building something similar? Let's exchange some knowledge.- Sales outreach
- Persistent memory
- Marketing automation
- MCP integrations
- Browser automation
- RAG knowledge base
- Meeting summaries
- Custom guardrails
- Computer control
- Multi-agent teams
- Ops & admin
- 3D office view
How It Works
Upload an image, paste from clipboard, or drag and drop.
Select the language and click Extract Text to run OCR locally.
Copy the extracted text or download it as a file.
Automated document processing.
OCR, data extraction, classification. Thousands of documents per hour, zero manual work.
Key Features
Privacy & Trust
Use Cases
Limitations
- Accuracy depends on image quality and clarity
- Handwritten text recognition is limited
- Very large images may be slow on older devices
- Complex layouts (tables, multi-column) may not preserve formatting
- Initial language data download may take a few seconds on first use
- Does not support PDF files directly