100% Private
Runs fully in your browser. Nothing sent to any server. Ever.
No Signup
No account, no API keys. Open and use it instantly.
Free Forever
Permanently free. No trials, no limits, no credit card.
One of 55 free AI tools built by Zalt, an AI architect and software engineer.
Free LLM Cost Calculator
Compare AI model pricing across every major provider — OpenAI, Anthropic, Google, Meta, Mistral, DeepSeek, xAI, and more. Pricing is fetched live from the OpenRouter API so numbers are always current with zero maintenance. Enter your expected input and output token counts, set your number of requests, filter by provider, and instantly see what each model would cost for your workload.
Loading...
Hire AI Employees
Hire AI Employees that work 24/7. No code.Are you a solo founder still doing sales, marketing, and support by hand? Hire AI Employees to run it all for you. They work 24/7, set up with no code, and go live in minutes.


More Free Tools
More than 20 free AI tools.

Hire AI Expert
Mahmoud Zalt · Freelance AI Engineer
Understanding AI Model Pricing
AI model pricing is based on tokens — small chunks of text that are roughly 3-4 characters or about 0.75 words each. Every API call incurs two separate costs: input tokens (your prompt, system instructions, and any context you send) and output tokens (the model's generated response). Output tokens are typically 3-5x more expensive than input tokens because generating text requires sequential computation — the model must predict each token one at a time — while processing input tokens can be done in parallel. Understanding this distinction is essential for accurately estimating your AI costs.
Pricing varies dramatically across providers and models. At the premium end, OpenAI's o1 reasoning model costs $15/$60 per million tokens (input/output), while at the budget end, DeepSeek V3 costs roughly $0.14/$0.28 and Mistral Nemo can be as low as $0.02/$0.04 per million tokens. Between these extremes, the most popular models cluster around $1-3 per million input tokens: GPT-4o at $2.50/$10, Claude Sonnet 4 at $3/$15, and Gemini 2.5 Pro at $1.25/$10. This calculator fetches live pricing from the OpenRouter API so you can compare all 300+ models side by side without checking each provider's pricing page individually.
Context window size is another critical factor in cost planning. The context window determines how much text a model can process in a single request — from 8K tokens for basic models up to 1 million tokens for Gemini 2.5 Pro and Claude Opus. Larger context windows let you send more data per request (long documents, full codebases, extended conversation histories), but more input tokens means higher per-request costs. Some providers charge higher rates when you exceed certain context thresholds — for example, Anthropic increases pricing for Claude Sonnet requests exceeding 200K input tokens.
How to Choose the Right AI Model for Your Budget
Choosing the right AI model is a balance between capability, speed, and cost. Premium models from OpenAI and Anthropic deliver the highest quality reasoning and coding, but at 10-50x the cost of mid-tier options. For most production applications — chatbots, content generation, summarization, and data extraction — mid-tier models like GPT-4o, Claude Sonnet, or Gemini Pro provide excellent quality at a fraction of the price. Budget models from Google, DeepSeek, and Mistral are ideal for high-volume tasks where cost per request matters more than maximum capability.
Open-source models like Meta Llama and Mistral offer a different cost equation. While the models are free to download and self-host, running them requires GPU infrastructure. Providers like Together AI, Groq, and Fireworks host these models at extremely competitive rates. This calculator shows pricing from multiple hosting providers for the same open-source model, so you can find the cheapest option.
For AI startups and production applications, the smartest approach is model routing — using different models for different tasks based on complexity. Simple tasks go to a cheap model, complex reasoning goes to a premium model. This can reduce your average cost per request by 5-10x. Use this calculator to model costs for each tier and build an accurate budget before you scale.
Cost Optimization Strategies for AI Applications
The biggest lever for reducing AI costs is prompt engineering. Shorter, more focused prompts mean fewer input tokens billed per request. Remove redundant instructions, trim unnecessary context, and use concise system prompts. Setting a max_tokens limit on output prevents the model from generating longer responses than you need. For applications that process documents or conversation histories, implement smart context management — summarize older messages rather than sending the full history, and only include the portions of a document that are relevant to the current query.
Provider-level optimizations can cut costs by 50-90%. Anthropic's prompt caching stores frequently-used system prompts and context, reducing the cost of cached tokens by 90% on subsequent requests — a massive saving for applications that send the same system prompt with every call. Both OpenAI and Anthropic offer batch APIs that process requests asynchronously at a 50% discount, ideal for non-real-time workloads like nightly data processing, bulk content generation, or evaluation pipelines. Google offers cache reads at 10% of the base input price. Combining caching with batch processing can reduce costs by up to 95% for eligible workloads.
Finally, monitor your actual token usage in production — many teams overestimate or underestimate their costs until they see real data. Track average input and output tokens per request type, identify which endpoints consume the most tokens, and look for opportunities to switch specific use cases to cheaper models. This calculator is a starting point for cost estimation, but production monitoring tools from your provider (OpenAI Usage Dashboard, Anthropic Console, Google Cloud Billing) give you the granular data you need to optimize continuously.
How It Works
Enter your expected input tokens, output tokens, and number of requests.
Browse 300+ models with live pricing — filter by provider or search by name.
Compare estimated costs across all models to find the best value.
Need expert help with AI?
Looking for a specialist to help integrate, optimize, or consult on AI systems? Book a one-on-one technical consultation with an experienced AI consultant to get tailored advice.
Key Features
Privacy & Trust
Use Cases
Limitations
- Pricing reflects OpenRouter rates which may differ slightly from direct provider pricing
- Does not include fine-tuning, embedding, or image generation costs
- Batch pricing and volume discounts are not reflected
- Pricing updates depend on OpenRouter API availability
Q&A SESSION
Got a quick technical question?
Skip the back-and-forth. Get a direct answer from an experienced engineer.
Frequently Asked Questions
What is a token and how many words is 1,000 tokens?
A token is the smallest unit of text that an AI model processes. Tokens are not exactly words — they are chunks of text typically 3-4 characters long, created by a tokenizer that splits text into subword pieces. A single word might be one token ("hello") or multiple tokens ("unbelievable" becomes "un" + "believ" + "able"). As a rule of thumb, 1,000 tokens equals roughly 750 English words, or conversely, 1,000 words is about 1,333 tokens. This ratio varies by language — Chinese, Japanese, and Korean text uses more tokens per word than English because each character is often its own token.
Why do input and output tokens have different prices?
Output tokens cost more because generating text is computationally harder than reading it. When processing input tokens, the model reads all tokens in parallel in a single forward pass. When generating output tokens, the model must predict one token at a time sequentially — each new token requires a full inference step that considers every token generated before it. This autoregressive generation process uses significantly more GPU time and memory. The typical output-to-input price ratio is about 3-5x across most providers. For example, GPT-4o charges $2.50 per million input tokens but $10 per million output tokens — a 4x ratio.
What is OpenRouter and is the pricing data accurate?
OpenRouter is a unified API gateway that provides access to 300+ AI models from every major provider — OpenAI, Anthropic, Google, Meta, Mistral, DeepSeek, xAI, and more — through a single OpenAI-compatible API. Instead of managing separate API keys and billing for each provider, developers use one API key and one credit balance. OpenRouter passes through the pricing of the underlying providers with no markup on inference rates, though they charge a small fee when purchasing credits. The pricing shown in this calculator reflects what you would pay through OpenRouter, which closely mirrors direct provider pricing and is reliable for comparison and budgeting purposes.
How do I compare GPT-4o, Claude, and Gemini pricing?
Enter your expected token usage in the calculator above and all three providers appear side by side with live pricing. Each provider offers multiple tiers — a flagship model for best quality, a mid-range model for balance, and a budget model for cost efficiency. Prices change frequently, which is why this tool fetches live data from the OpenRouter API instead of showing static numbers that go stale.
What are the cheapest AI models available?
Open-source models like Meta Llama and Mistral served through providers like Together AI, Groq, or Fireworks are typically the cheapest options. DeepSeek and Google Gemini Flash also offer very competitive pricing. Use the provider filter above to compare budget-friendly options. OpenRouter also lists some free models with rate limits.
What is a context window and why does it matter for cost?
The context window is the maximum number of tokens a model can process in a single request — including both your input prompt and the generated output. For example, GPT-4o has a 128K token context window (roughly 96,000 words), while Gemini 2.5 Pro supports up to 1 million tokens. Context window size matters for cost because larger prompts mean more input tokens billed per request. If you need to process long documents, analyze codebases, or maintain lengthy conversation histories, you need a model with a large context window — and those longer inputs cost more. Some providers like Google and Anthropic charge higher per-token rates when you exceed certain context thresholds.
How do I reduce my AI API costs?
There are several proven strategies to reduce AI API costs. First, choose the right model — use cheaper models like GPT-4o-mini or Gemini Flash for simple tasks and reserve expensive models for complex reasoning. Second, minimize tokens by writing concise prompts, trimming unnecessary context, and setting max_tokens to limit output length. Third, use prompt caching (available from Anthropic and Google) to avoid re-processing repeated system prompts — this can save up to 90% on cached tokens. Fourth, use batch APIs when you do not need real-time responses — both OpenAI and Anthropic offer 50% discounts for batch processing. Fifth, implement response streaming and early stopping to avoid generating tokens you do not need. This calculator helps you model these scenarios by adjusting token counts and comparing models.
Is this calculator free? Why?
Yes, this calculator is completely free with no signup, no account, no usage limits, and no ads. It costs nothing to run because all calculations happen locally in your browser — the only external call is to the public OpenRouter API to fetch current pricing data, which is also free. There are no server costs, no database, and no infrastructure to maintain. Similar tools from other sites often require accounts, show ads, or gate features behind paywalls. This tool is offered as a free utility for the developer community.
Does this calculator include fine-tuning costs?
No. This calculator covers inference costs only — the per-token price of sending prompts and receiving responses from pre-trained models. Fine-tuning costs are separate and vary significantly by provider. For example, OpenAI charges $25 per million training tokens for fine-tuning GPT-4o-mini. Fine-tuning also involves additional costs for hosting the fine-tuned model. If you are considering fine-tuning, check the provider's documentation directly. For most use cases, prompt engineering with a base model is more cost-effective than fine-tuning.
How often is the pricing updated?
Pricing is fetched live from the OpenRouter API every time you open the calculator. There is no cached or stale data — you always see the most current prices available. When providers announce price changes (which happens frequently as competition drives costs down), the OpenRouter API typically reflects those updates within hours to days. For the most recent price announcements, you can also check each provider's official pricing page directly.
What is the difference between pay-per-token and a subscription like ChatGPT Plus?
Pay-per-token (API pricing) charges you only for the tokens you actually use — you pay per request based on input and output token counts. A subscription like ChatGPT Plus ($20/month) or Claude Pro ($20/month) gives you access to the chat interface with usage caps but no per-token billing. API pricing is better for developers building applications, running automated workflows, or processing large volumes of requests. Subscriptions are better for individual users who want a chat interface. For heavy API usage, the per-token model is almost always cheaper than trying to use a chat subscription programmatically (which violates terms of service anyway).
Can I use this calculator to budget for my AI startup?
Yes, and that is one of its primary use cases. Enter your expected average input and output token counts per request, then set the number of requests to match your projected daily, weekly, or monthly volume. The calculator will show you the cost per model at that scale. For a more accurate budget, calculate separately for different use cases — for example, a customer support chatbot might use 2,000 input tokens and 500 output tokens per message, while a document analysis feature might use 50,000 input tokens and 2,000 output tokens. Multiply by your expected user volume and you have a realistic cost projection to include in your financial model.
Why do some models show $0.00 pricing?
Models showing $0.00 are free-tier models offered through OpenRouter. These are typically open-source models like certain Llama or Mistral variants that OpenRouter hosts at no charge to users. Free models come with rate limits — usually around 20 requests per minute and 200 requests per day — so they are suitable for experimentation and light usage but not for production applications that need reliable throughput. If you need consistent performance without rate limits, paid models are the better choice even if a free option exists for the same architecture.
AI Agents Orchestration
To Run Your Business on Autopilot
I'm building a modern AI workforce for deploying autonomous AI agents at scale. Live since 15 April 2026 at www.sistava.com.
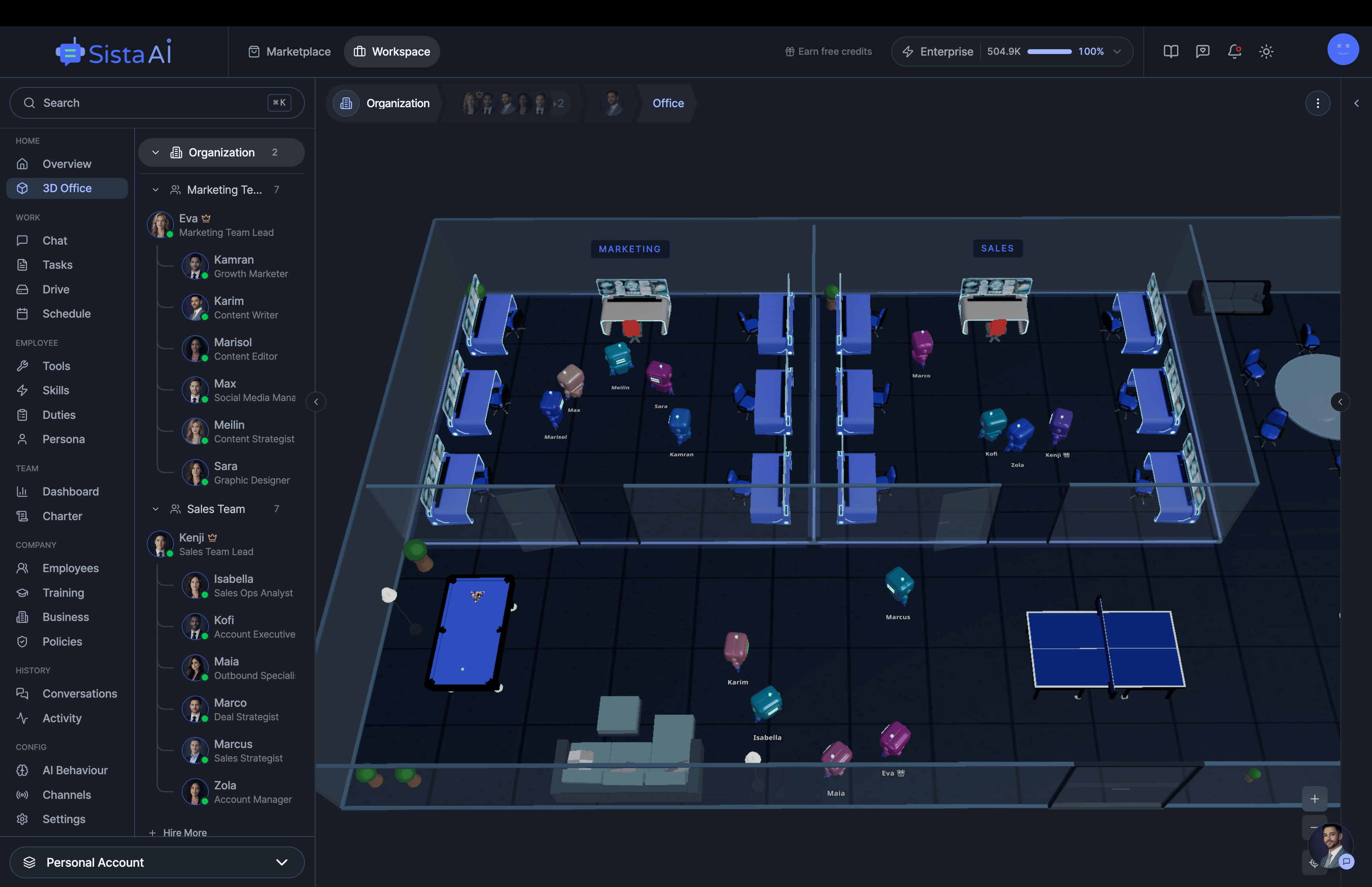
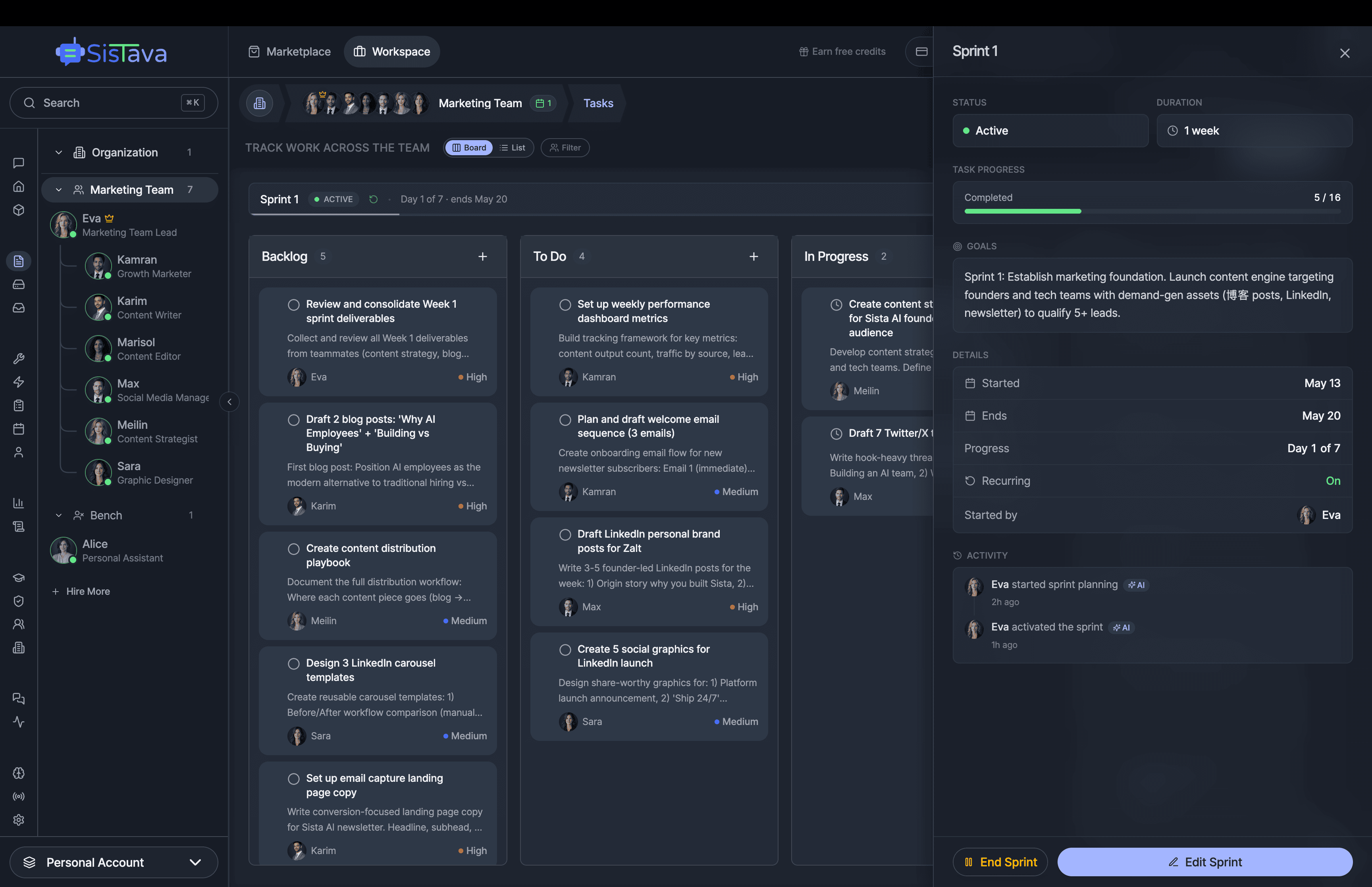
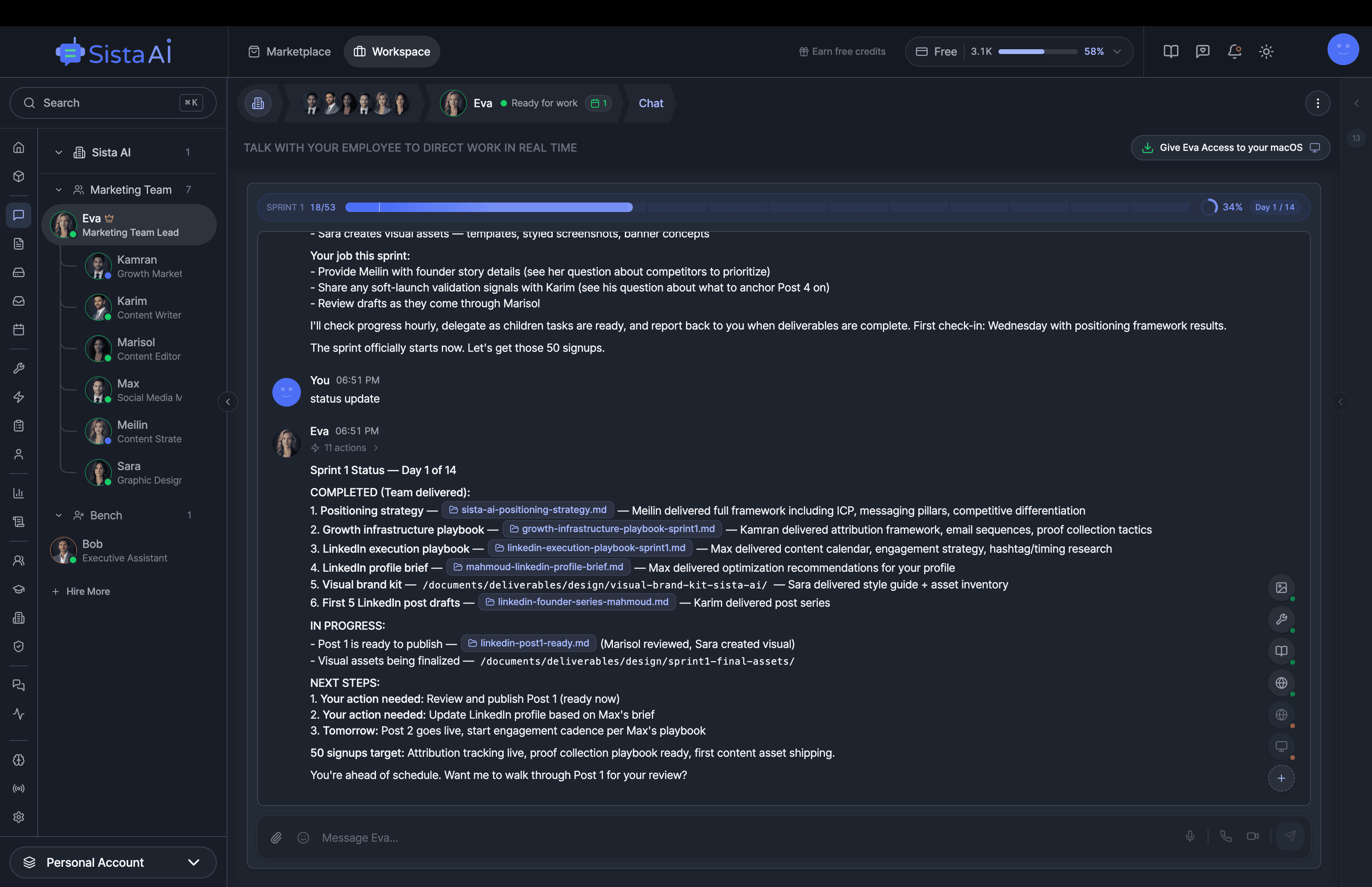
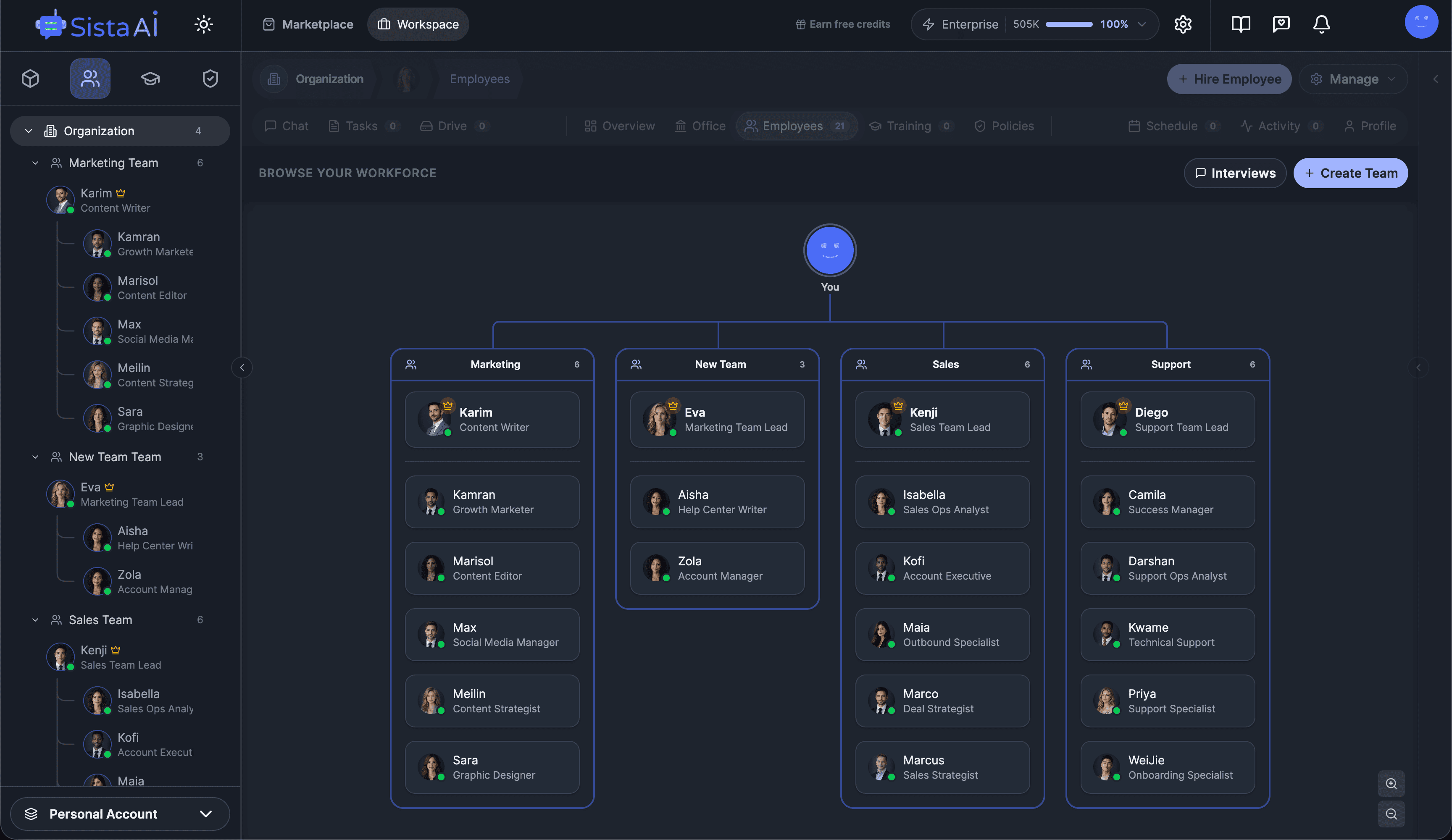
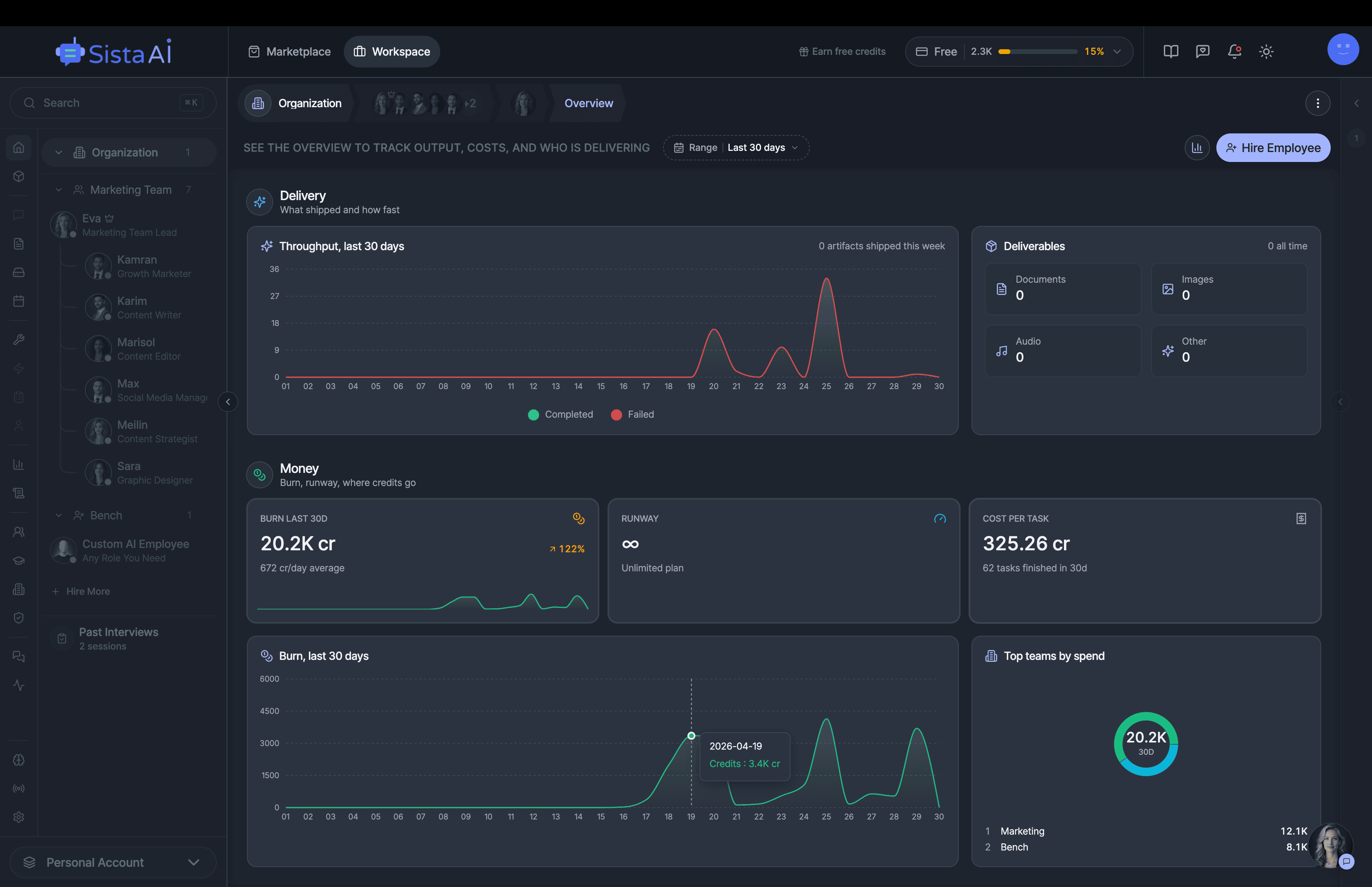

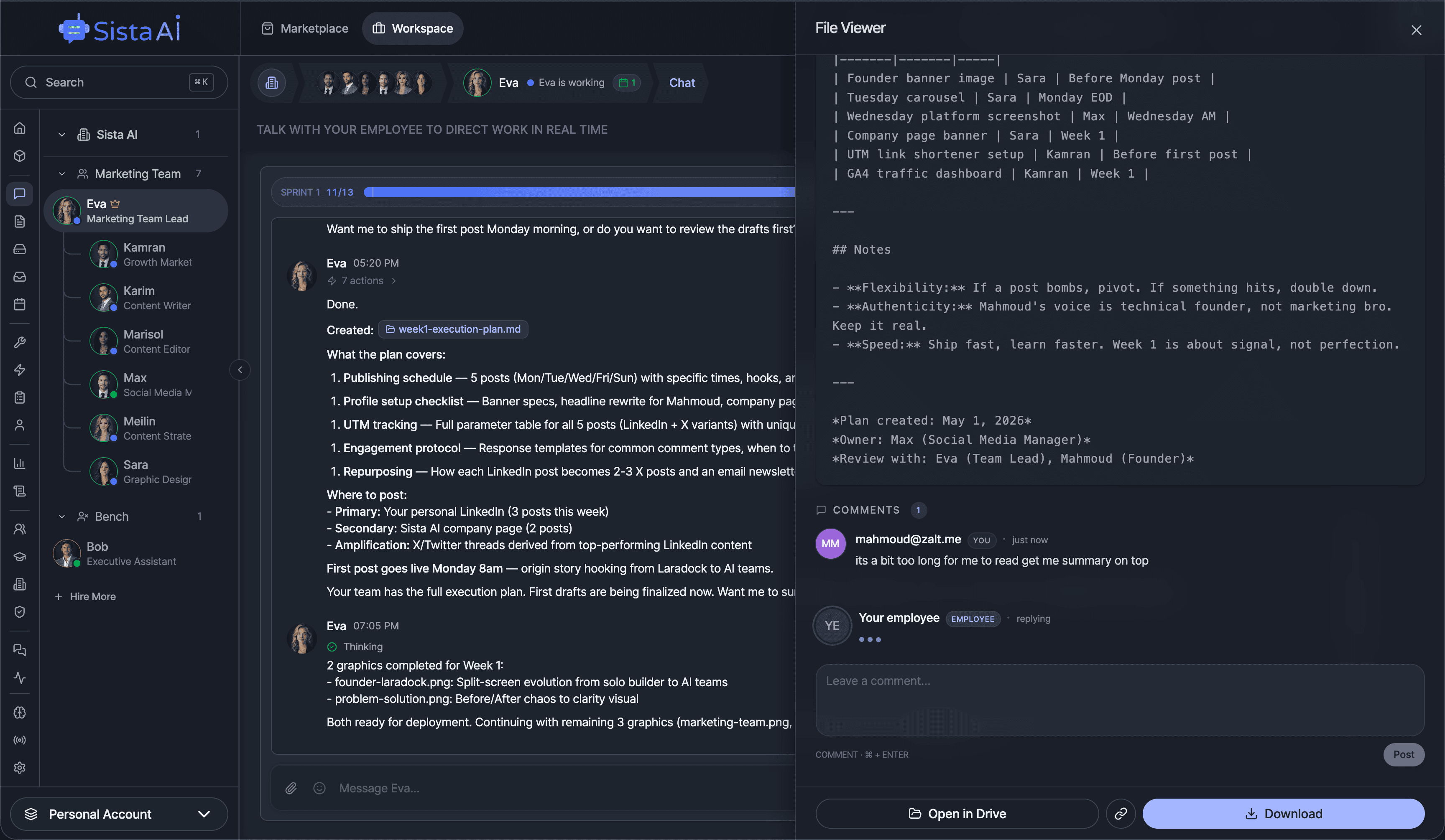
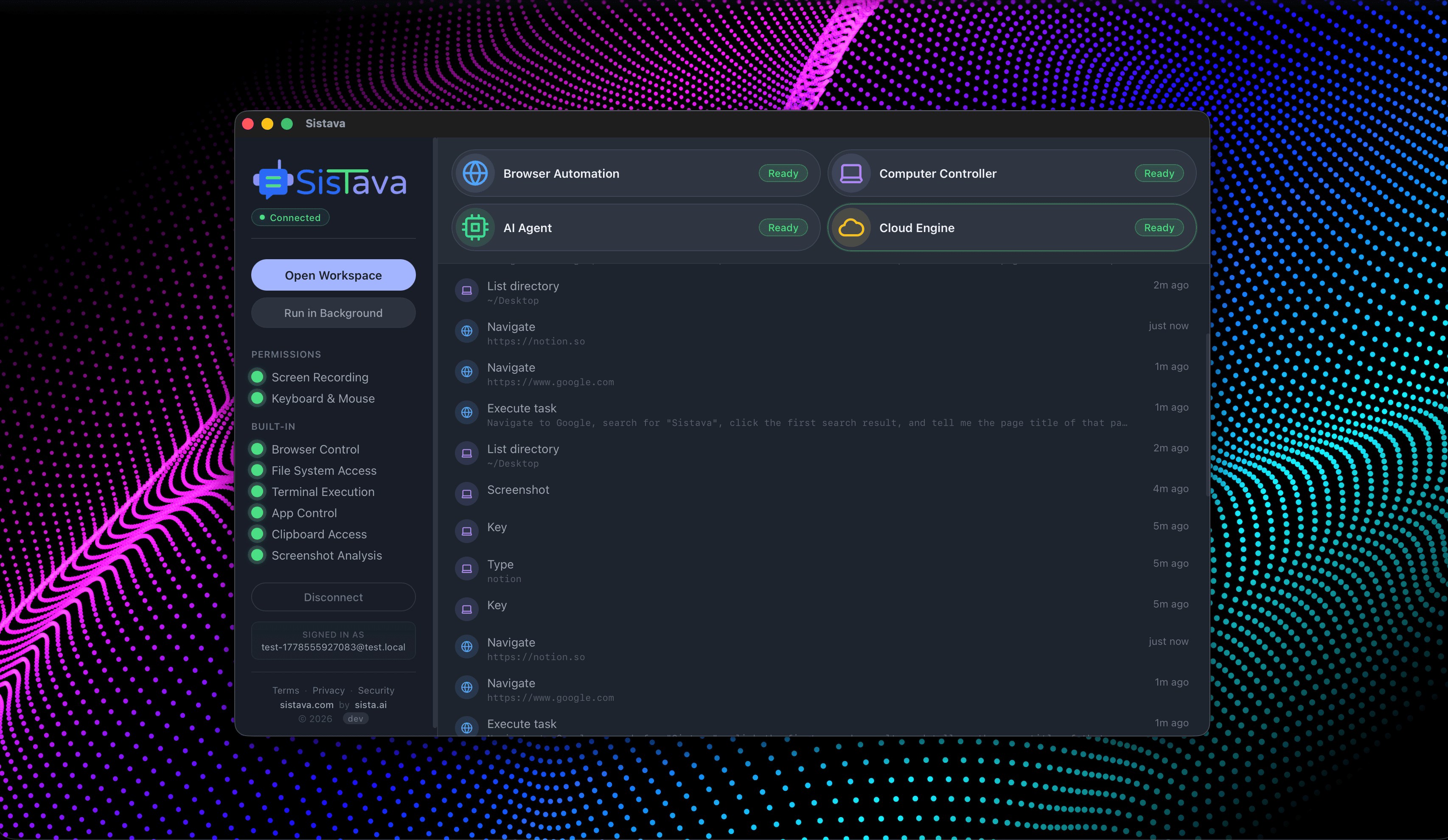
If you're a solo founder looking for AI agents to handle sales, marketing, and ops, check it out, You'll find it valuable. I use it myself to run my business. Your feedback is appreciated.
Building something similar? Let's exchange some knowledge.- Sales outreach
- Persistent memory
- Marketing automation
- MCP integrations
- Browser automation
- RAG knowledge base
- Meeting summaries
- Custom guardrails
- Computer control
- Multi-agent teams
- Ops & admin
- 3D office view