100% Private
Runs fully in your browser. Nothing sent to any server. Ever.
No Signup
No account, no API keys. Open and use it instantly.
Free Forever
Permanently free. No trials, no limits, no credit card.
One of 55 free AI tools built by Zalt, an AI architect and software engineer.
Free Fake Data Generator
Generate realistic fake data for development, testing, and prototyping. Choose from 7 data types — person, company, address, product, user account, transaction, and blog post — and generate 1 to 100 records as JSON. Powered by @faker-js/faker, the most widely used fake data library in the JavaScript ecosystem with over 70 locale options. Faker.js provides modules for person, location, company, finance, internet, commerce, lorem, date, and many more data categories, producing output that looks convincingly real while containing zero actual personal information. All generation happens locally in your browser — no server calls, no API keys, no data leaving your device.
Loading...
Hire AI Employees
Hire AI Employees that work 24/7. No code.Are you a solo founder still doing sales, marketing, and support by hand? Hire AI Employees to run it all for you. They work 24/7, set up with no code, and go live in minutes.


More Free Tools
More than 20 free AI tools.

Hire AI Expert
Mahmoud Zalt · Freelance AI Engineer
Why Fake Data Matters for Modern Software Development
Every software project needs test data, and most teams handle it poorly. Developers copy slices of production databases into staging environments, testers reuse the same handful of hardcoded records across every test suite, and demo environments sit empty or filled with obviously fake entries like "Test User" and "123 Street." Each of these shortcuts creates real problems — production data copies risk violating GDPR, CCPA, and HIPAA regulations; stale test fixtures miss bugs that only surface with varied input; and empty demos fail to sell the product.
Synthetic test data solves all three problems. A tool like this generates records that look convincingly real — proper name distributions, plausible addresses, realistic transaction amounts, and correctly formatted emails and phone numbers — without containing a single byte of actual personal information. The data is safe to use in any environment, from a developer laptop to a shared CI/CD pipeline, because it was never real in the first place. Unlike data masking or anonymization, which transform production records and carry residual re-identification risk, synthetic generation creates data from scratch with zero privacy liability.
This tool uses Faker.js, the most widely adopted fake data library in the JavaScript ecosystem. Faker.js provides over 20 modules — person, location, company, finance, internet, commerce, lorem, date, phone, image, vehicle, airline, science, food, music, color, and more — each producing output that follows the patterns and distributions of real-world data. The result is test data that exercises the same code paths, edge cases, and rendering logic as production data would, making your tests genuinely meaningful rather than ceremonial.
What Faker.js Can Generate and How It Works
Faker.js (@faker-js/faker) is an open-source library that generates massive amounts of fake but realistic data for Node.js, Deno, Bun, and the browser. Its API is organized into topic-specific modules: the person module produces first names, last names, full names, job titles, job areas, and gender-aware variants; the location module generates street addresses, cities, states, zip codes, countries, latitude, longitude, and time zones; the company module creates company names, catch phrases, buzz phrases, and industry descriptors; the finance module produces account numbers, routing numbers, credit card numbers, currency codes, transaction amounts, and Bitcoin addresses; the internet module generates email addresses, usernames, passwords, domain names, IP addresses, MAC addresses, URLs, and user agents; the commerce module creates product names, descriptions, prices, departments, and materials; the date module produces past dates, future dates, recent dates, birthdates, and dates between specific ranges; and the lorem module generates words, sentences, paragraphs, and longer text blocks.
Beyond the core modules, Faker.js includes generators for phone numbers, images (placeholder URLs), colors (hex, RGB, HSL, human-readable names), vehicles (manufacturer, model, VIN, fuel type), airlines (airline name, airport code, flight number), science (chemical elements, units), food (dish, ingredient, description), music (genre, song name), and more. The library supports over 70 locales — including English, Spanish, French, German, Portuguese, Japanese, Chinese, Korean, Arabic, Hindi, Russian, Italian, Dutch, Polish, Swedish, and Turkish — so generated names and addresses look authentic for different regions. Not every locale covers every module, and English is used as a fallback for missing entries.
This online tool wraps Faker.js in a simple interface with 7 pre-built data types that cover the most common testing needs. You select a type, choose how many records to generate (1 to 100), and get valid JSON output instantly. The JSON is formatted and ready to paste into your code, import into a database, or use as a mock API response. For developers who need more control — custom schemas, specific locales, reproducible seeds, or millions of records — the Faker.js library can be installed directly with npm install @faker-js/faker and used programmatically in any JavaScript or TypeScript project.
Testing Best Practices: How to Use Fake Data Effectively
Generating fake data is only the first step — using it effectively requires discipline. Match your test data to your production schema: if your users table has a VARCHAR(50) first_name column, make sure your test names include entries near the character limit, not just short names like "Bob." Faker.js naturally produces varied-length output, which is one of its advantages over hand-written fixtures. Respect unique constraints and foreign keys — generate IDs, emails, and usernames that are unique within each batch, and use consistent references when you need relational data across tables.
Rotate your test data regularly. Many teams generate a seed file once and commit it to the repository forever. Over months, the codebase evolves but the test data does not, so new features, validation rules, and edge cases go untested. A better approach is to generate fresh data in your CI/CD pipeline on every run, optionally using a fixed seed for reproducibility so that test failures can be exactly replicated. The Faker.js seed function (faker.seed()) makes this straightforward — the same seed always produces the same sequence of values.
Finally, keep fake data out of production. It sounds obvious, but synthetic records have a way of leaking into live databases through migration scripts, seeder files that run in the wrong environment, or staging databases that get promoted. Tag synthetic records with a clear marker (a specific email domain like @example.com, a flag column, or a metadata field) and add guardrails in your deployment process to prevent test data from reaching production. If your organization is subject to GDPR, CCPA, or HIPAA, document your test data generation process — auditors want to see that no real personal data is used outside production, and synthetic generation is the cleanest way to demonstrate compliance.
How It Works
Choose a data type and number of records.
Click Generate to create realistic fake data.
Copy the JSON or download it as a file.
Need expert help with AI?
Looking for a specialist to help integrate, optimize, or consult on AI systems? Book a one-on-one technical consultation with an experienced AI consultant to get tailored advice.
Key Features
Privacy & Trust
Use Cases
Limitations
- Data is random — not based on real people or companies
- Does not generate images or files (text data only)
- Does not support custom data schemas
- English locale only in this version
Q&A SESSION
Got a quick technical question?
Skip the back-and-forth. Get a direct answer from an experienced engineer.
Frequently Asked Questions
Is this Fake Data Generator completely free?
Yes, it is 100% free with no usage limits, no signup, and no per-record charges. Online data generation services like Mockaroo offer free tiers but cap rows or require accounts for larger exports. Because this tool runs Faker.js locally in your browser, there are no server costs, so you can generate as many records as you need — indefinitely and without restrictions.
Is my generated data sent to a server or stored anywhere?
No. All data generation happens entirely inside your browser using Faker.js compiled into the page bundle. There are no API calls, no cloud processing, and no analytics on what you generate. This makes the tool safe for generating test data that mimics sensitive categories — financial transactions, user accounts, personal addresses — because the output exists only on your device until you choose to copy or download it. Verify this by checking the Network tab in DevTools while generating.
Is the generated data real? Could it match a real person?
No. All data is randomly assembled from Faker.js dictionaries of first names, last names, street names, cities, domains, and other components. The combinations are random, so while individual parts (like "John" or "Main Street") exist in reality, the full records do not correspond to real people, companies, or addresses. Faker.js is explicitly designed to produce plausible but fictitious data, which is why it is the standard choice for test environments where using real customer data would violate GDPR, CCPA, HIPAA, or internal data policies.
What is Faker.js and why is it the standard for test data?
Faker.js (@faker-js/faker) is the most widely used JavaScript library for generating fake but realistic data. It provides over 20 modules — person, location, company, finance, internet, commerce, lorem, date, phone, image, color, vehicle, music, science, food, airline, and more — each containing dozens of methods. The library supports over 70 locales so generated names and addresses look authentic for different countries. Faker.js is used by millions of developers worldwide for testing, prototyping, database seeding, and demo environments. It runs in Node.js, Deno, Bun, and the browser.
What data types can I generate with this tool?
This tool offers 7 pre-built data types that cover the most common testing needs. Person generates full name, email, phone, birthdate, job title, and avatar URL. Company generates company name, industry, catch phrase, address, phone, and website. Address generates street, city, state, zip code, country, and coordinates. Product generates product name, description, price, category, SKU, and rating. User generates username, email, password hash, role, signup date, and status. Transaction generates transaction ID, amount, currency, merchant, card type, and timestamp. Blog post generates title, author, content, tags, published date, and slug.
Can I use this data to seed my database?
Yes. The output is valid JSON that you can import directly into MongoDB, PostgreSQL, MySQL, SQLite, or any database that accepts JSON input. Each record contains realistic field names and properly typed values — strings for names, numbers for prices, ISO dates for timestamps, and so on. For relational databases, you can generate multiple data types separately and join them by adding foreign key references after download. Many developers use this tool to quickly generate seed files during early development before writing more sophisticated data factories.
How is fake data different from data masking or anonymization?
Data masking takes real production data and obscures sensitive fields — replacing real names with scrambled versions while preserving statistical properties and relationships. Fake data generation (synthetic data) creates entirely new records from scratch that never originated from real people. The advantage of synthetic data is that there is zero risk of re-identification because the data never existed in the first place. Data masking preserves real data distributions, which can be important for analytics testing, but carries residual privacy risk if the masking is reversed. For most development and testing scenarios, fully synthetic data from a tool like this is the safer and simpler choice.
Can I generate custom fields or schemas?
This tool provides 7 pre-built data types optimized for the most common use cases. For fully custom schemas, you can use the @faker-js/faker library directly in your code — install it with npm install @faker-js/faker and call any of its 20+ modules to build exactly the record structure you need. Alternatively, download the JSON from this tool and reshape it with a script or use it as a starting template. Tools like Mockaroo offer GUI-based custom schema builders, but they require an account and process data on their servers.
Is this tool useful for GDPR and privacy compliance?
Yes, indirectly. GDPR, CCPA, and HIPAA all restrict the use of real personal data in non-production environments. Many compliance frameworks explicitly recommend using synthetic test data instead of copies of production databases. By generating entirely fictional records with this tool, you avoid the legal and security risks of copying real customer data into development, staging, QA, or CI/CD environments. The generated data looks realistic enough for thorough testing without containing any actual PII. This is especially important for distributed teams where developers and testers may not have the same data access clearances.
How does this compare to Mockaroo and other online generators?
Mockaroo is a popular cloud-based data generator that supports over 100 data types, custom schemas, SQL and CSV output, and formula-based fields. It is more flexible for complex schemas but processes your data on its servers, requires an account, and limits free users to 1,000 rows per download. This tool runs entirely in your browser with no account, no row limits, and no data leaving your device. For quick JSON generation of common data types — people, companies, products, transactions — this tool is faster and more private. For highly customized schemas or non-JSON output formats, Mockaroo or using the Faker.js library directly in code may be a better fit.
What formats does the output support?
The tool outputs formatted JSON, which is the most versatile format for developers. JSON can be directly used as mock API responses, imported into document databases like MongoDB or CouchDB, parsed by any programming language, or converted to CSV, SQL INSERT statements, or YAML with simple scripts. If you need CSV or SQL output directly, you can pipe the JSON through a converter like json2csv or write a quick script, or use the Faker.js library in a Node.js script that writes directly to your preferred format.
Can I use the generated data for load testing and performance testing?
Yes. Generating 100 records at a time gives you enough data for small-scale tests directly. For larger datasets, generate multiple batches and concatenate the JSON arrays, or use the Faker.js library in a script to produce thousands or millions of records. Realistic fake data is essential for meaningful load tests because it exercises the same code paths as production data — varied string lengths, different date ranges, realistic price distributions, and diverse name formats. Homogeneous test data (like "Test User 1", "Test User 2") often misses bugs that only surface with realistic variety.
Does Faker.js support languages other than English?
Yes. The @faker-js/faker library supports over 70 locales including Spanish, French, German, Portuguese, Japanese, Chinese, Korean, Arabic, Hindi, Russian, Italian, Dutch, Polish, Swedish, Turkish, and many more. Each locale provides culturally appropriate names, addresses, phone number formats, and other data. This online tool currently uses the English locale, but if you need localized data, you can use the library directly in your code by importing a locale-specific instance — for example, import { fakerDE } from "@faker-js/faker" for German data.
Is the generated data deterministic or random on every run?
Each click of the Generate button produces a new random set of records. Faker.js uses a pseudorandom number generator internally, and this tool does not expose a seed option, so every generation is different. If you need reproducible data for automated tests — where the same seed always produces the same records — use Faker.js directly in your code with faker.seed(12345). Reproducible seeds are particularly valuable in CI/CD pipelines where test failures need to be exactly reproducible.
How many records can I generate at once?
This tool lets you generate 1 to 100 records per batch. For most development and prototyping tasks, 10 to 50 records is sufficient to populate a UI, test pagination, or verify data rendering. If you need thousands or millions of records for database seeding or load testing, use the @faker-js/faker library in a Node.js script — it can generate millions of records in seconds because the generation is pure computation with no I/O overhead.
What are the most common use cases for fake data in software development?
The most common use cases are: database seeding during early development when you need data to build against before real users exist; mock API responses so frontend teams can develop independently of backend progress; test fixtures for unit and integration tests that need consistent, realistic input data; demo and sales environments that need to look populated with realistic content; QA testing where testers need varied data to exercise different code paths and edge cases; documentation and tutorials where sample data helps illustrate features; and CI/CD pipelines that need fresh, disposable test data on every run without depending on a shared test database.
AI Agents Orchestration
To Run Your Business on Autopilot
I'm building a modern AI workforce for deploying autonomous AI agents at scale. Live since 15 April 2026 at www.sistava.com.
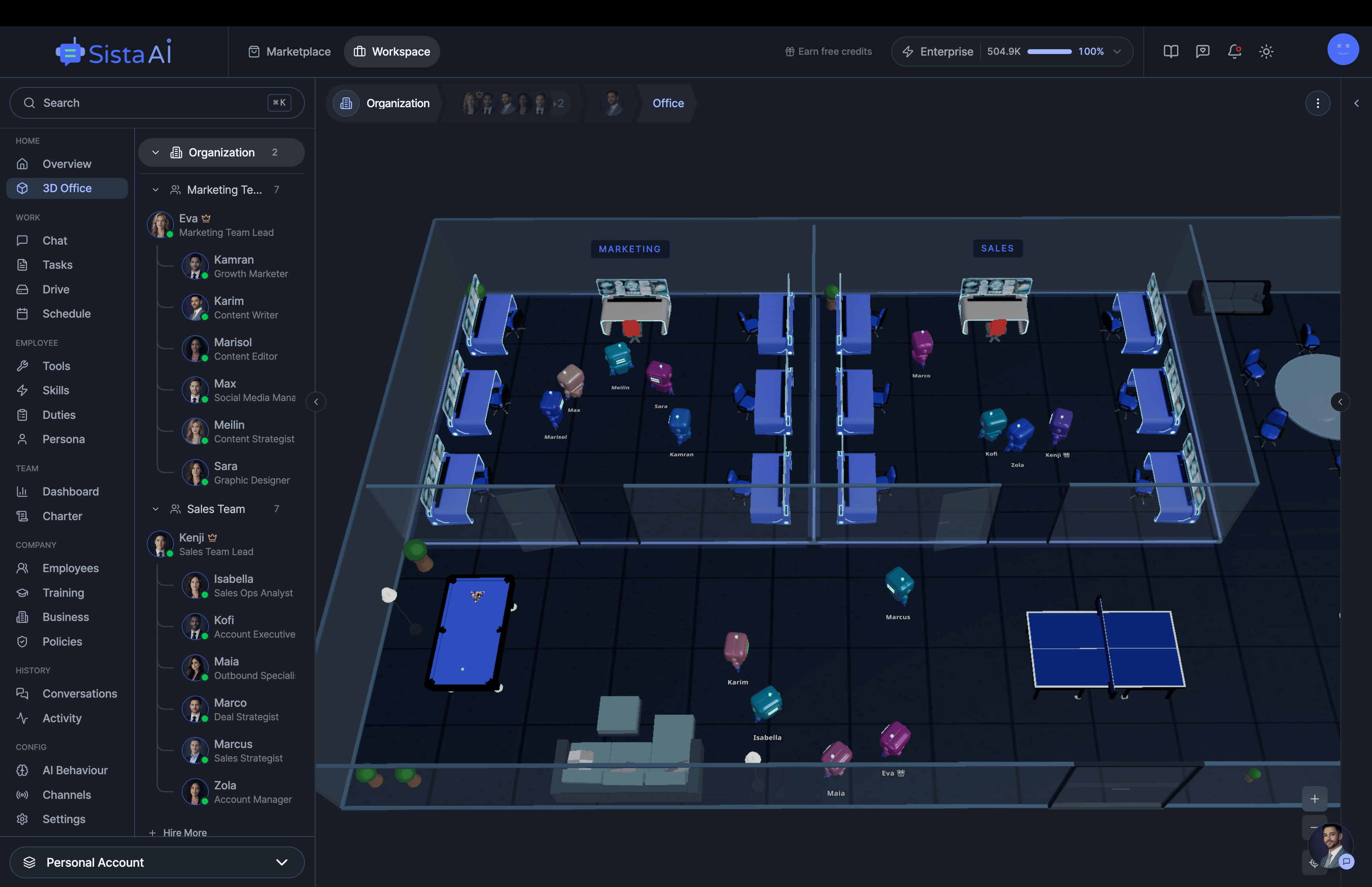
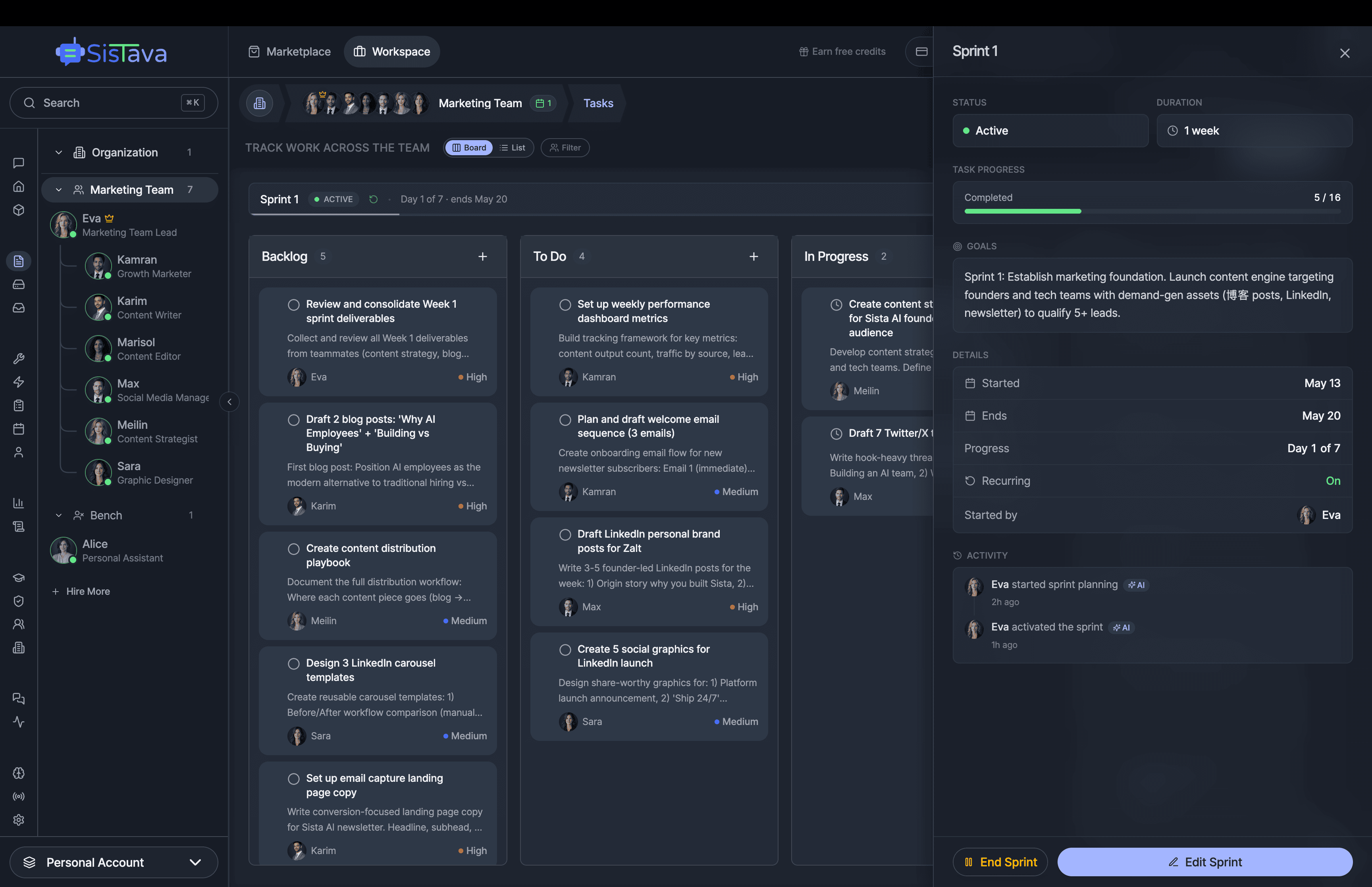
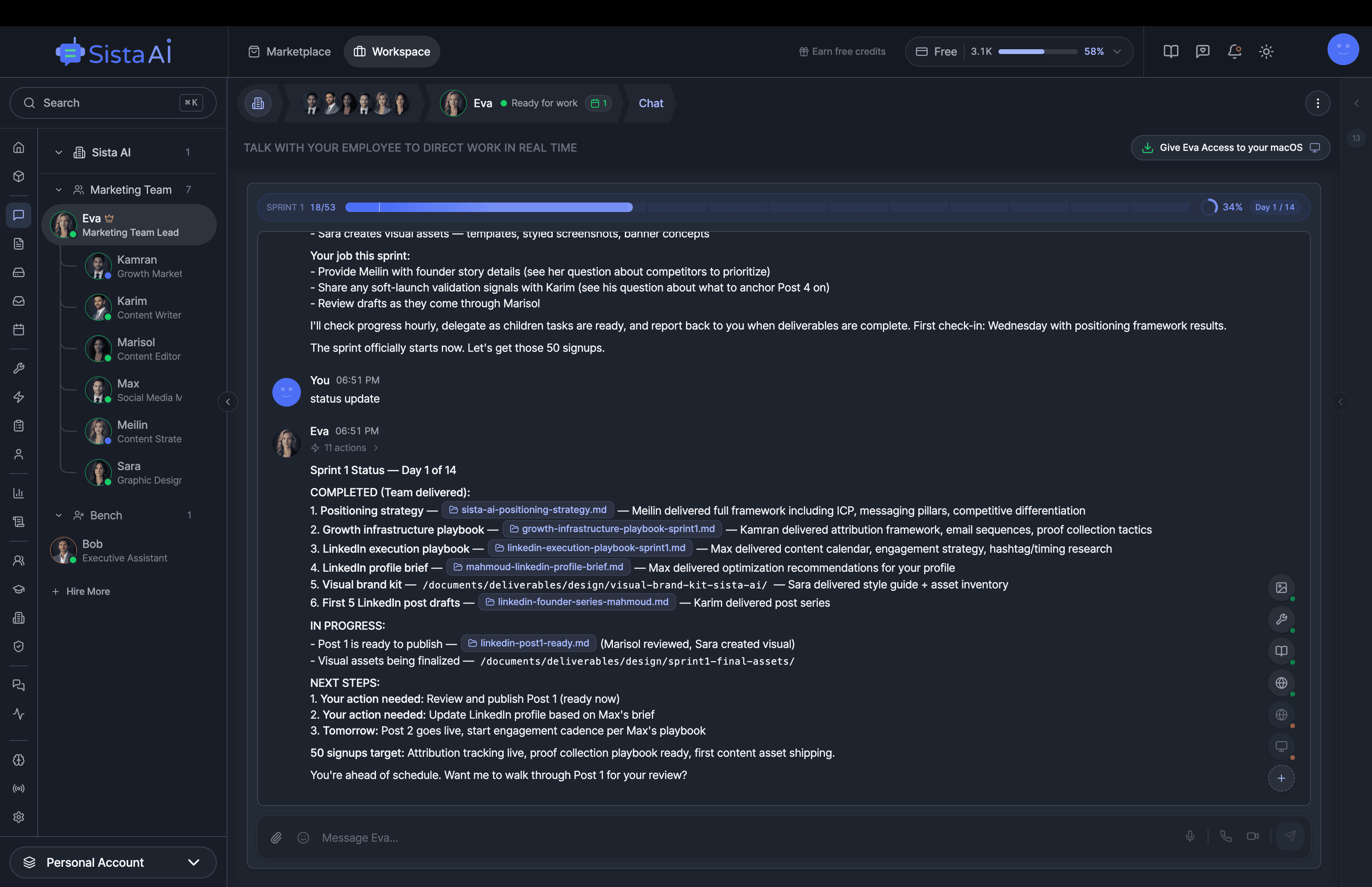
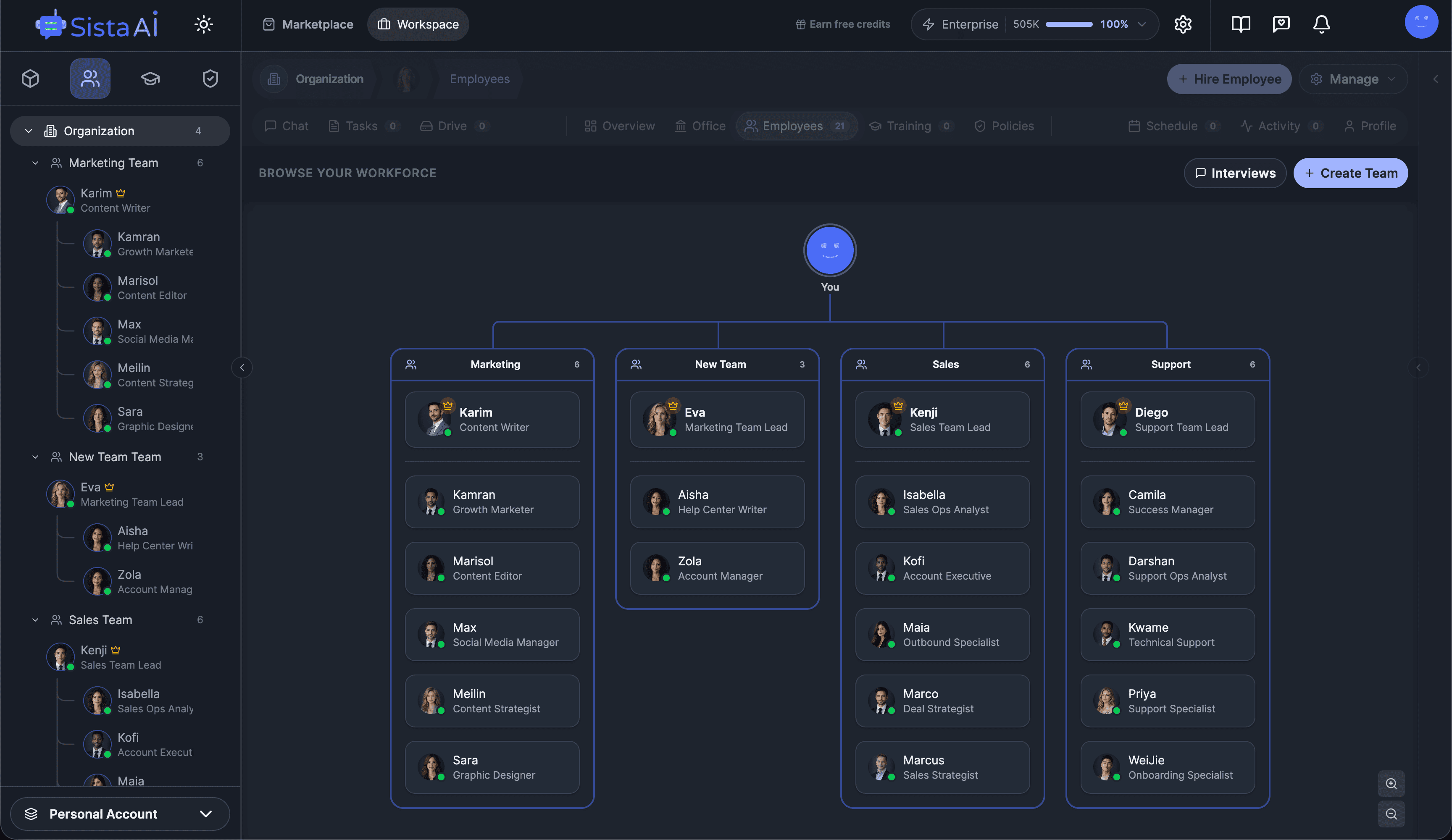
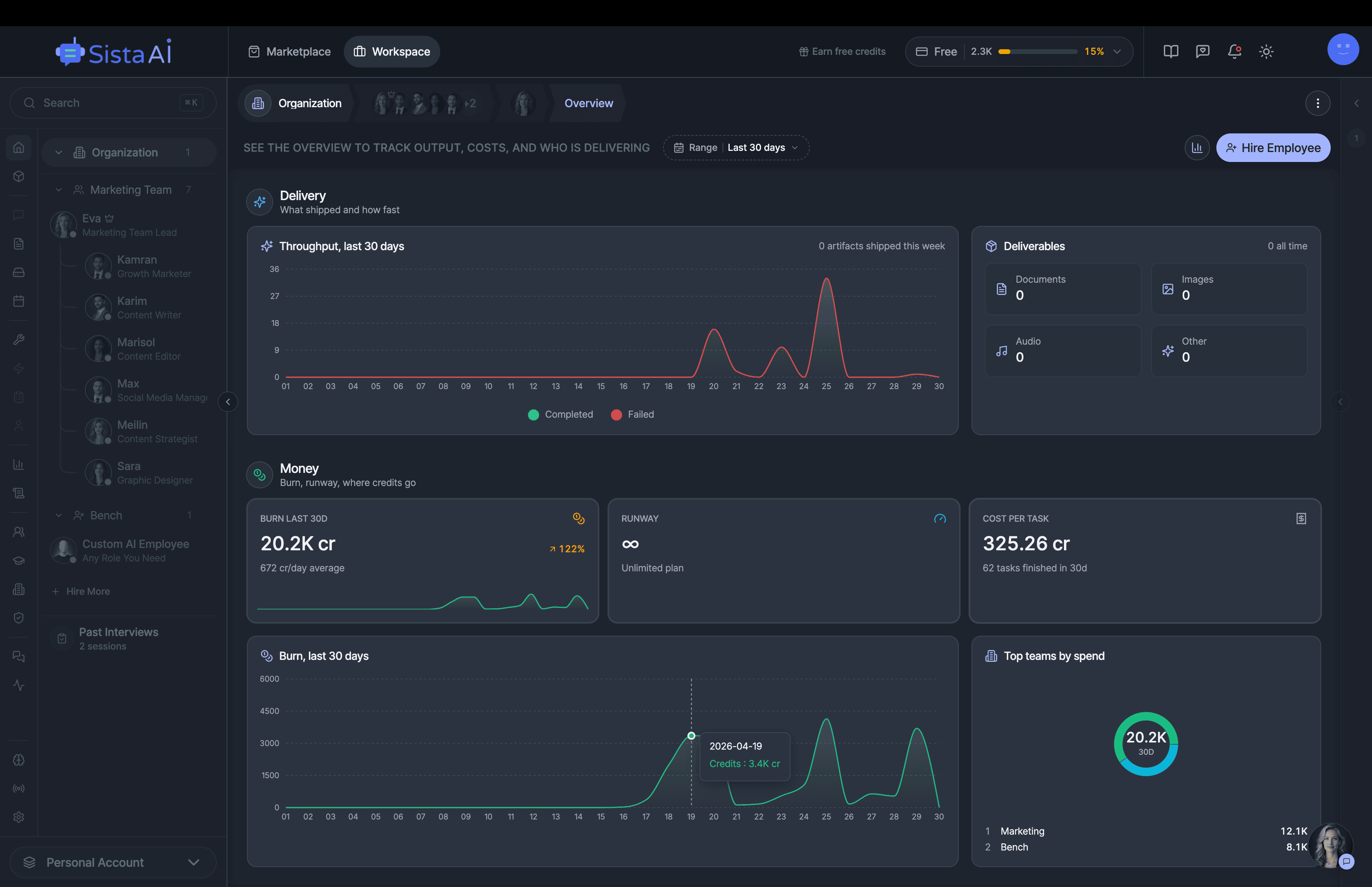

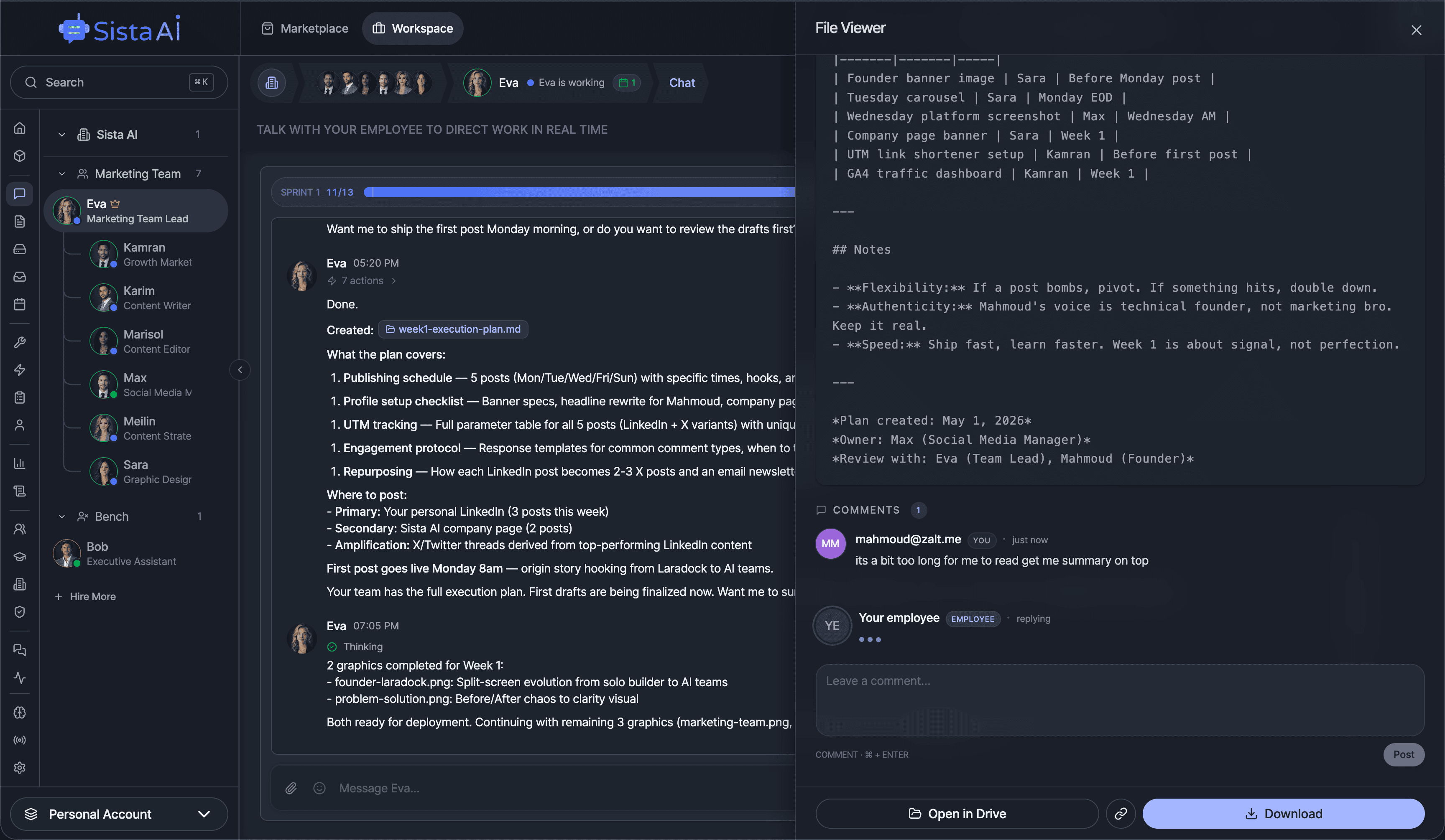
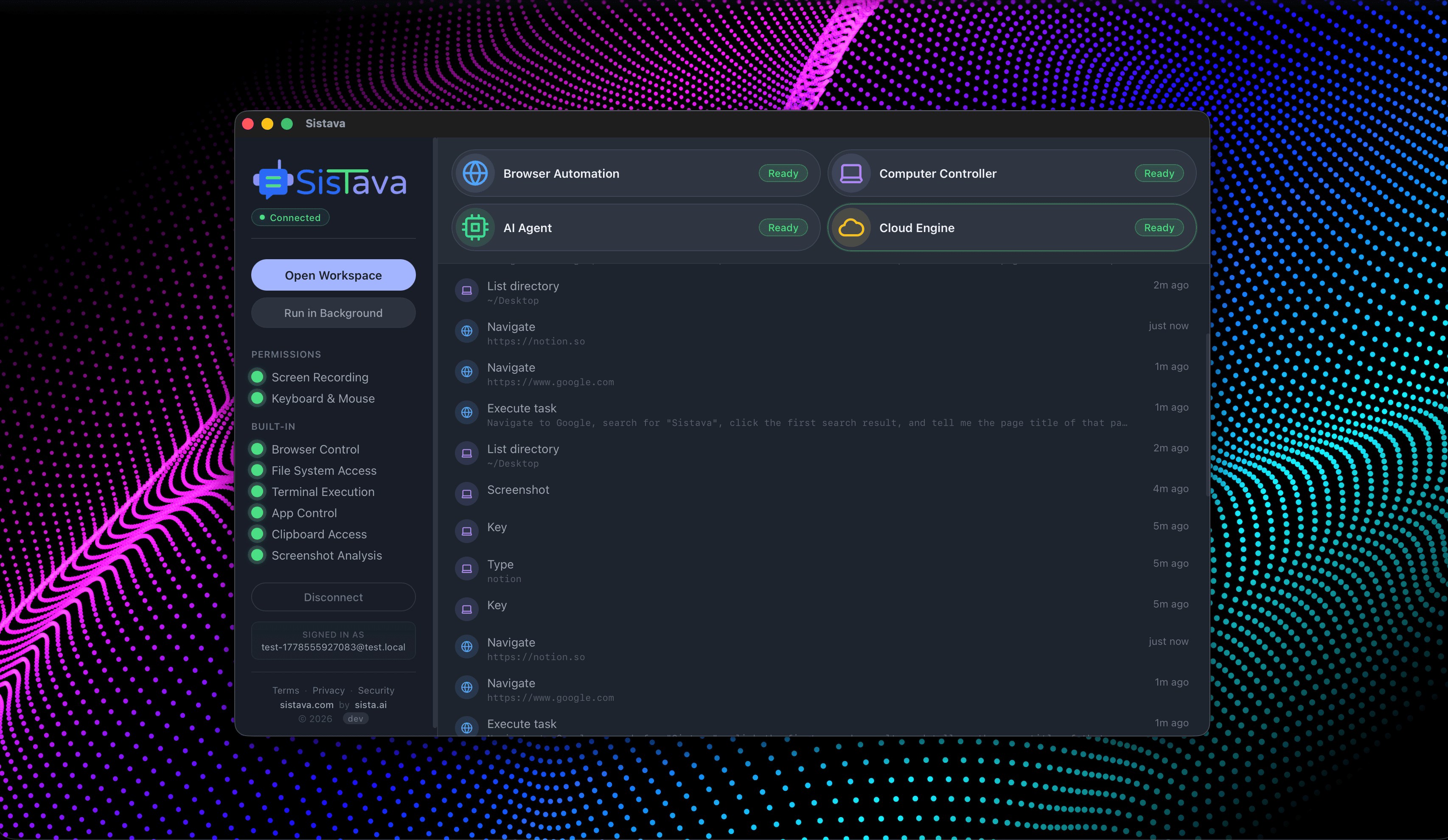
If you're a solo founder looking for AI agents to handle sales, marketing, and ops, check it out, You'll find it valuable. I use it myself to run my business. Your feedback is appreciated.
Building something similar? Let's exchange some knowledge.- Sales outreach
- Persistent memory
- Marketing automation
- MCP integrations
- Browser automation
- RAG knowledge base
- Meeting summaries
- Custom guardrails
- Computer control
- Multi-agent teams
- Ops & admin
- 3D office view