One of 55 free AI tools built by Zalt, an AI architect and consultant with 16 years of experience.
Free Text to Speech
Type or paste any text and instantly convert it to natural-sounding speech using Kokoro, an open-weight 82-million parameter AI voice model. Choose from 28 English voices across American and British accents with male and female options, and adjust speaking speed from 0.5x to 2x. Everything runs locally in your browser using WebAssembly — no signup, no server, no API calls. Your text never leaves your device.
Loading Text-to-Speech...
Hire AI Employees
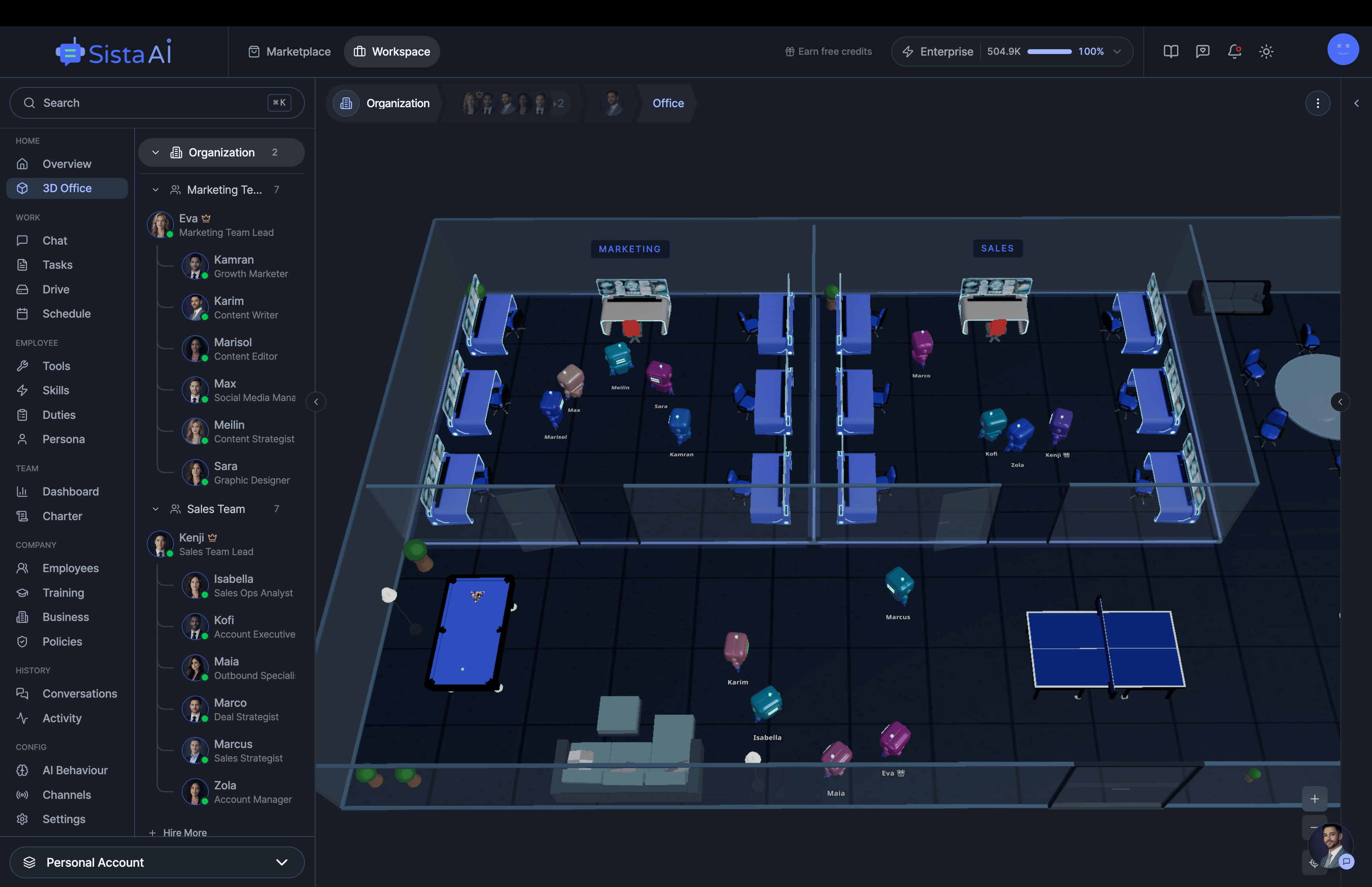
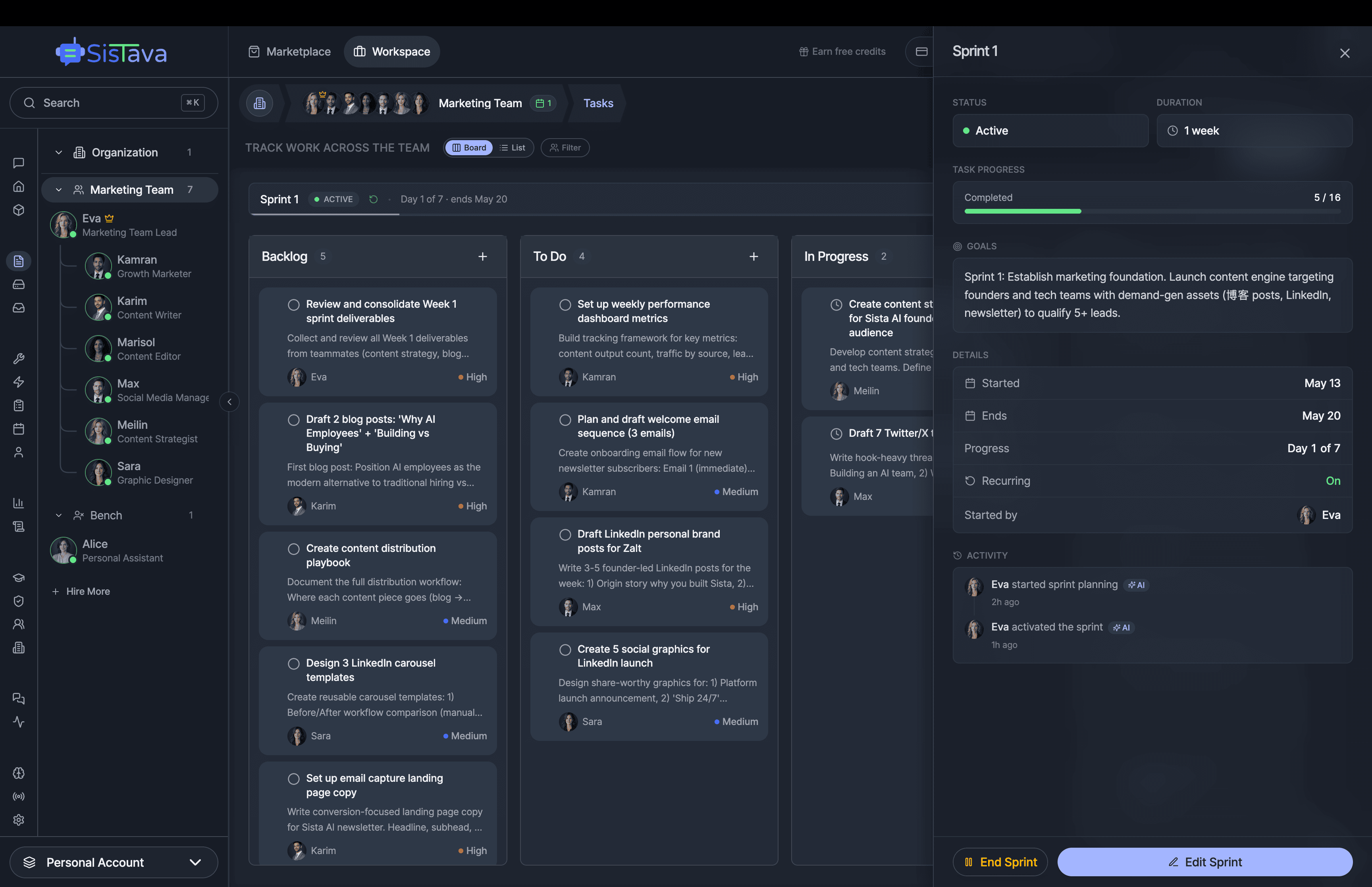
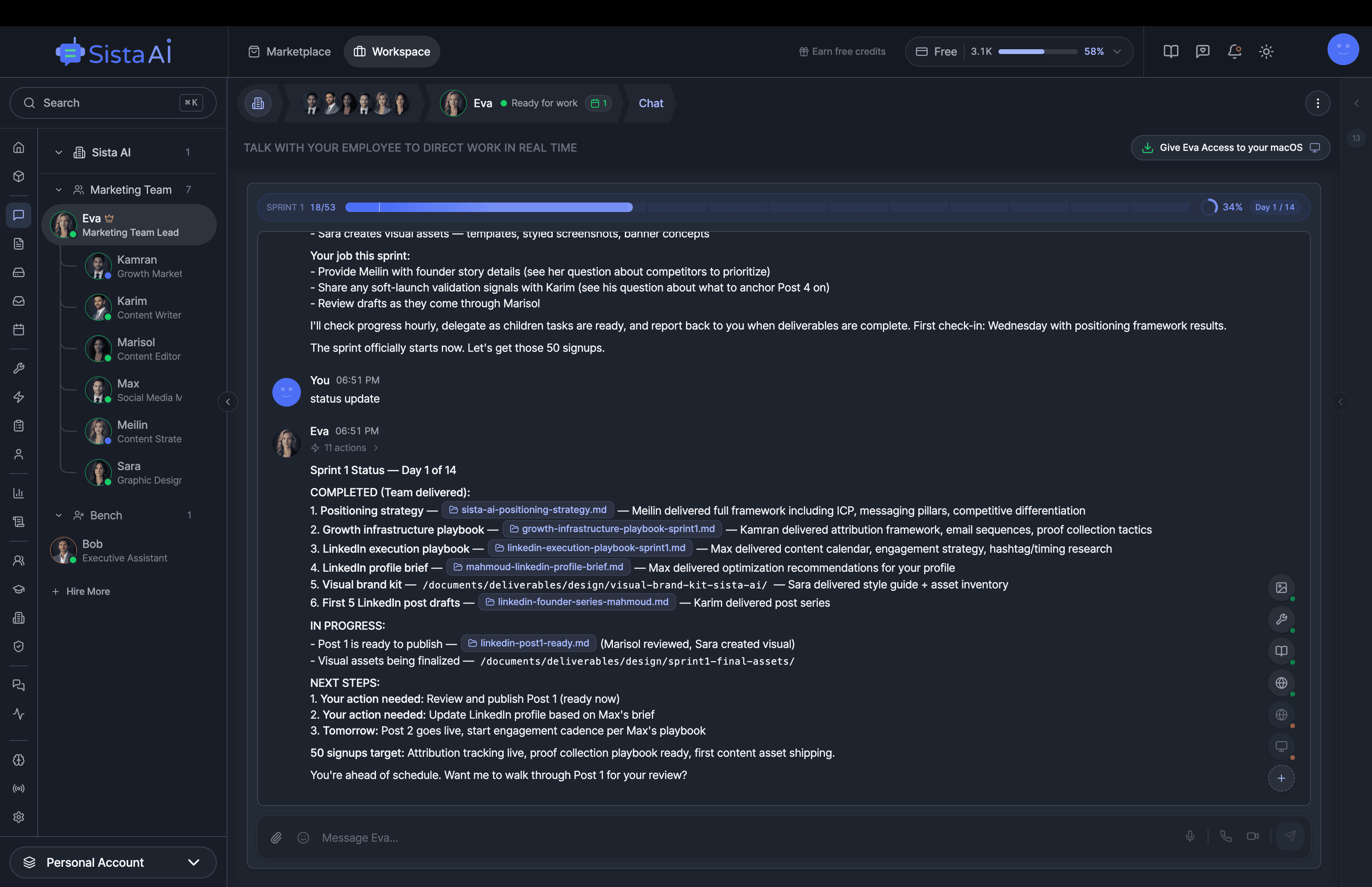
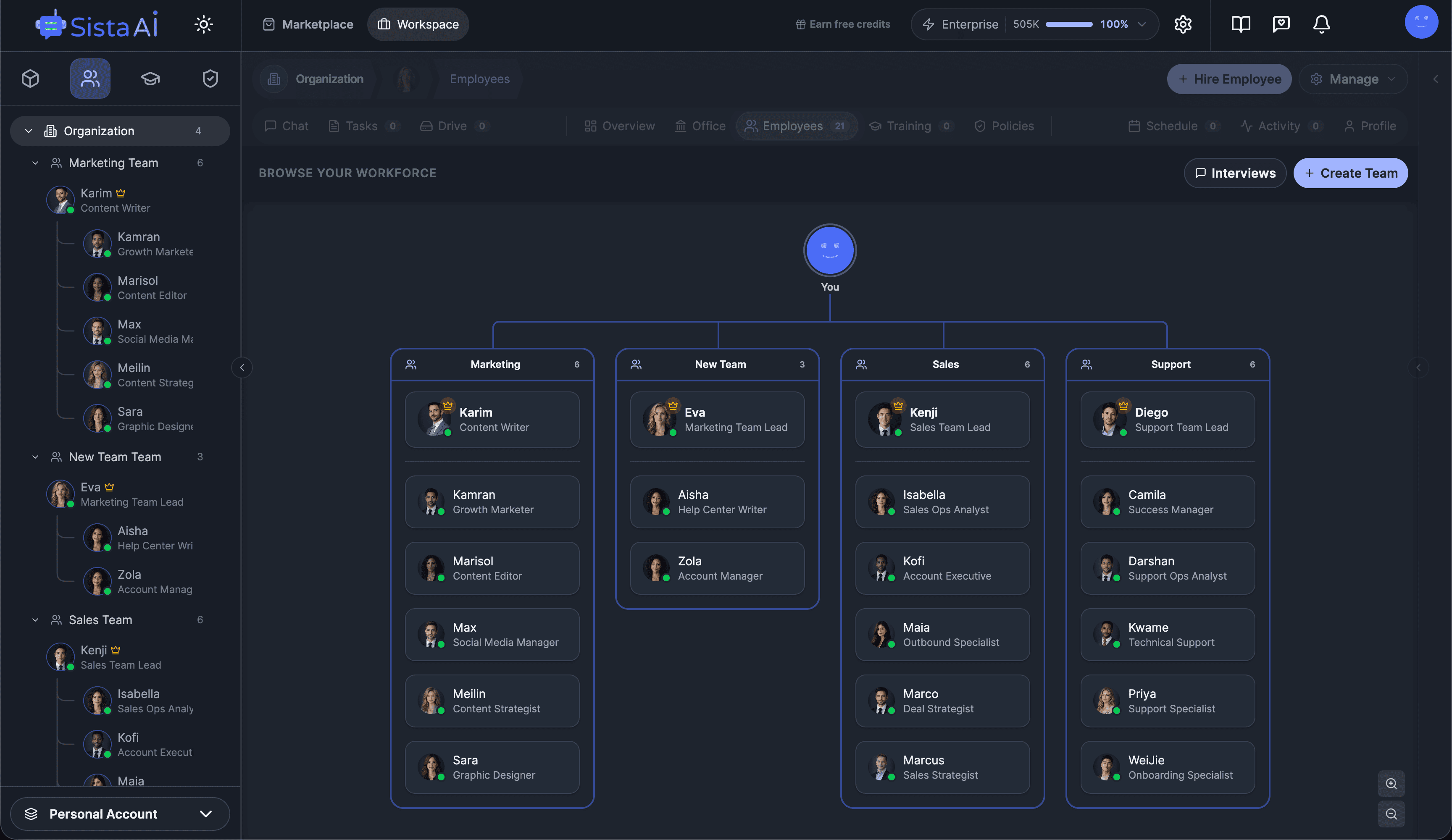
Hire AI Employees that work 24/7. No code.Are you a solo founder still doing sales, marketing, and support by hand? Hire AI Employees to run it all for you. They work 24/7, set up with no code, and go live in minutes.


More Free Tools
More than 20 free AI tools.

Hire AI Expert
Mahmoud Zalt · Freelance AI Engineer
What Is Kokoro TTS and How Does This Text to Speech Tool Work?
This free text-to-speech tool is powered by Kokoro, an open-source 82-million parameter speech synthesis model. Unlike robotic-sounding TTS engines, Kokoro produces natural, expressive speech that rivals commercial services like ElevenLabs, Google Cloud TTS, and Amazon Polly — but runs entirely in your browser with no API keys, no cloud processing, and no data leaving your device.
The model offers 28 distinct English voices — 20 American (11 female, 9 male) and 8 British (4 female, 4 male). Each voice has been trained to sound natural with proper intonation, rhythm, and emphasis. You can preview voices instantly and switch between them to find the perfect match for your content.
All processing happens locally using WebAssembly. Your text is never uploaded to any server, making this tool ideal for converting sensitive documents, personal notes, or confidential content into speech. The model downloads once and is cached in your browser for instant access on return visits.
How Kokoro Generates Natural Speech
Kokoro is an open-source text-to-speech model built on the StyleTTS2 architecture, available on GitHub and Hugging Face. At just 82 million parameters, it is remarkably lightweight compared to commercial TTS models while delivering comparable quality. The model uses phoneme-based synthesis with prosody prediction, producing speech that captures natural pauses, stress patterns, and emotional tone.
For web deployment, Kokoro can be integrated through ONNX Runtime Web or Transformers.js, enabling real-time speech synthesis directly in the browser. Developers building accessibility features, language learning apps, content narration tools, or voice-enabled interfaces will find Kokoro a production-ready alternative to paid TTS APIs. The model's small size and efficient architecture make it practical for edge deployment on mobile devices, embedded systems, and offline applications.
Need expert help with AI?
Looking for a specialist to help integrate, optimize, or consult on AI systems? Book a one-on-one technical consultation with an experienced AI consultant to get tailored advice.
Q&A SESSION
Got a quick technical question?
Skip the back-and-forth. Get a direct answer from an experienced engineer.
AI Agents Orchestration
To Run Your Business on Autopilot
I'm building a modern AI workforce for deploying autonomous AI agents at scale. Live since 15 April 2026 at www.sistava.com.
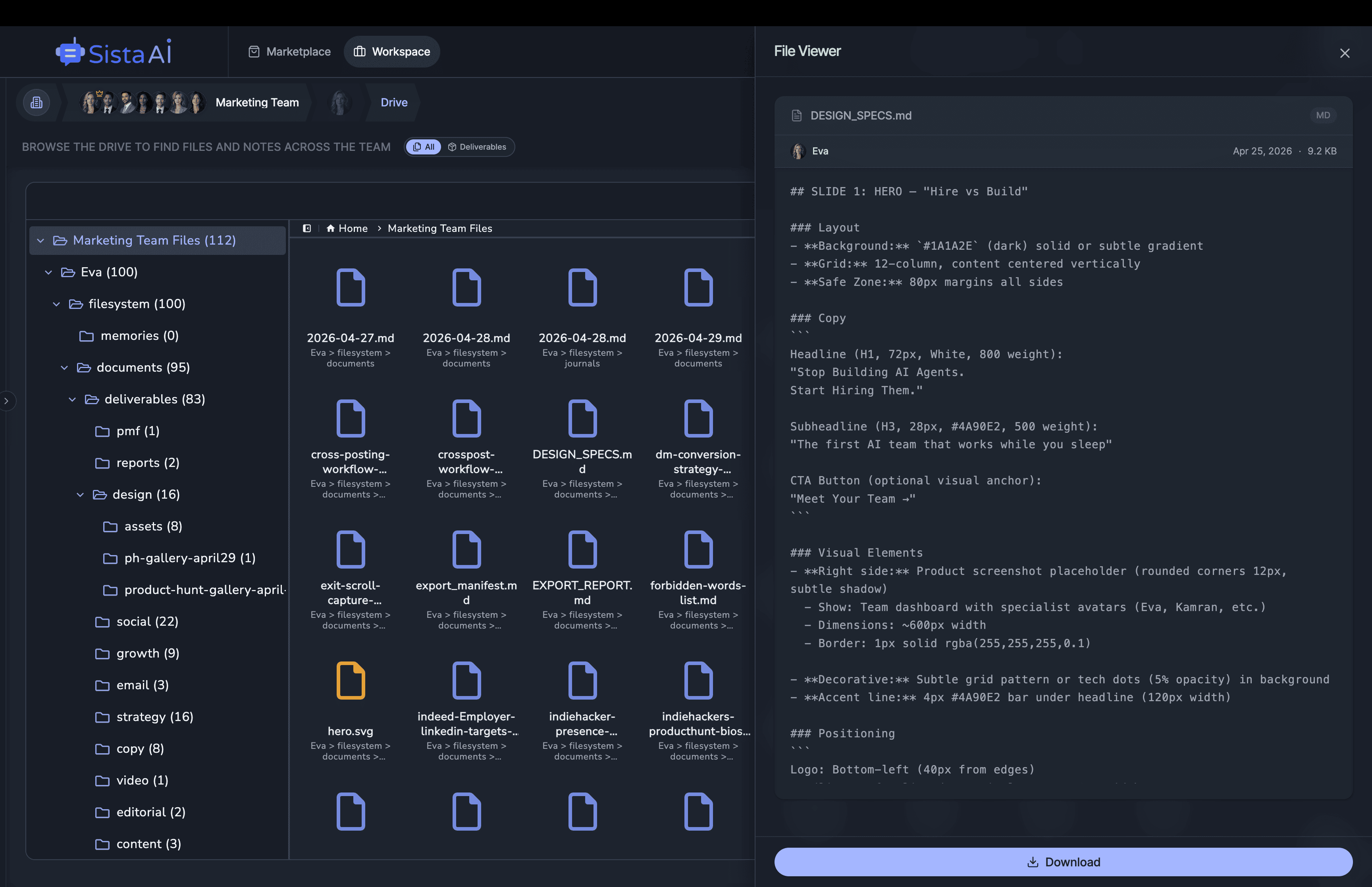
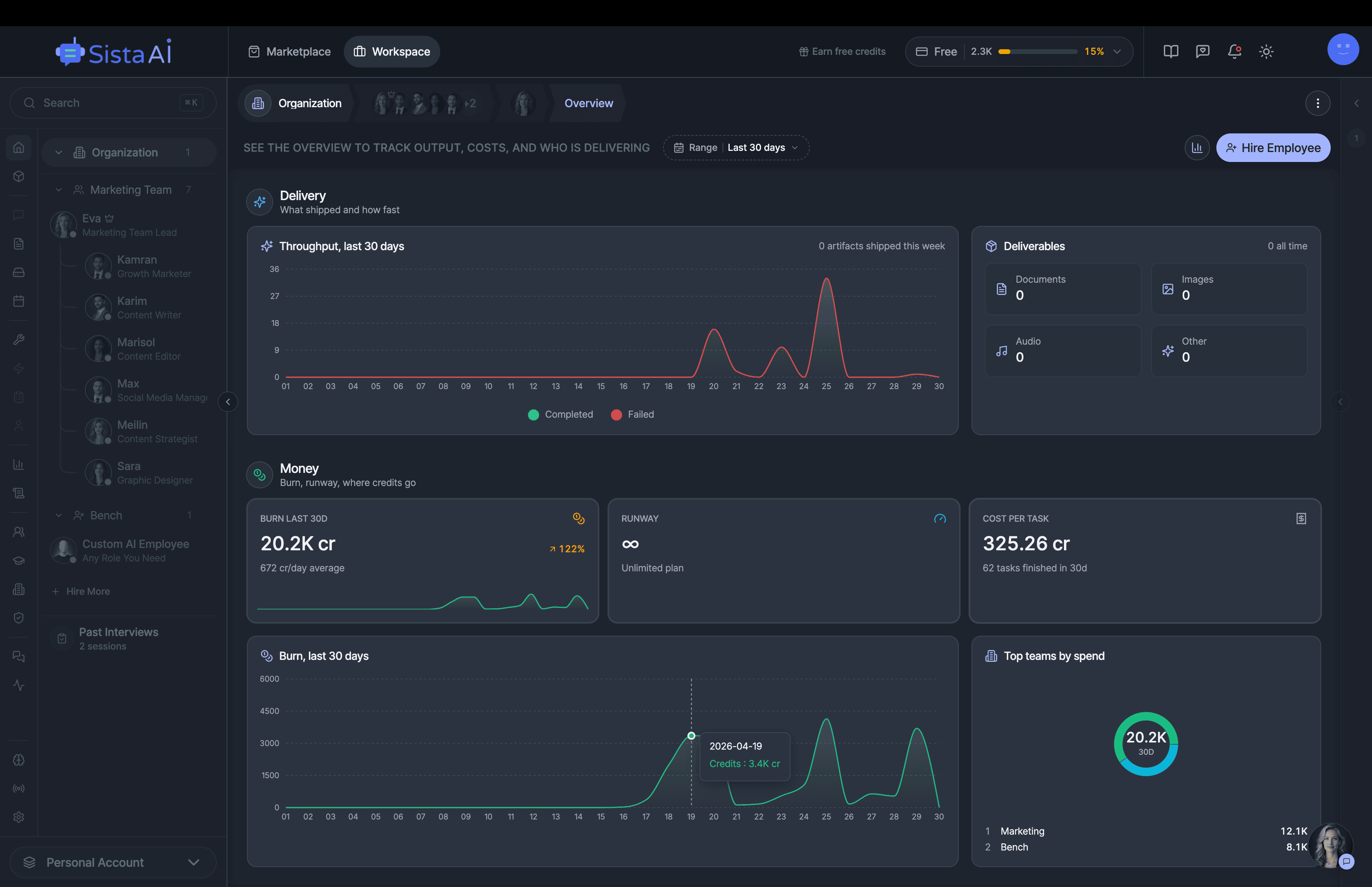

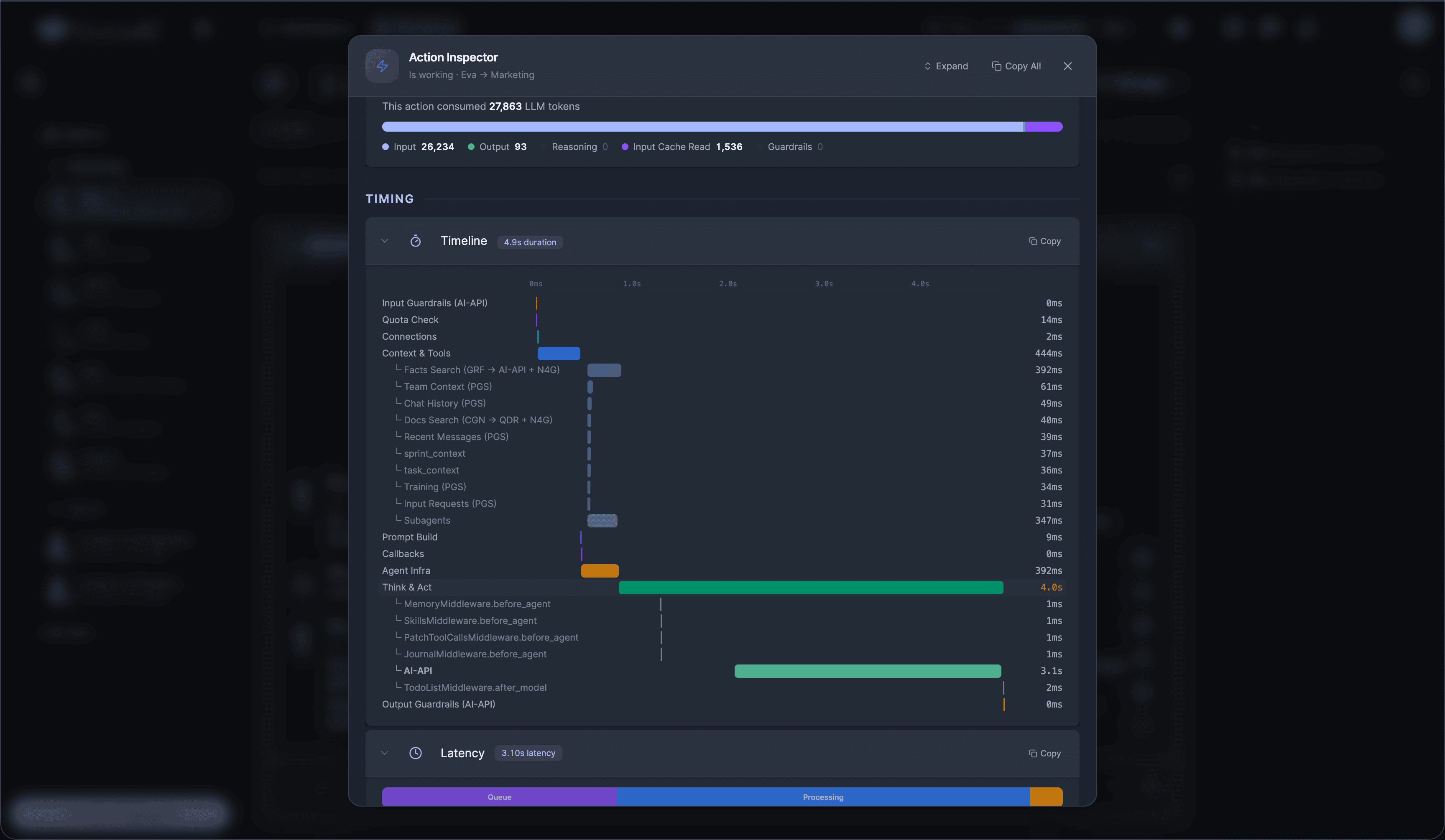
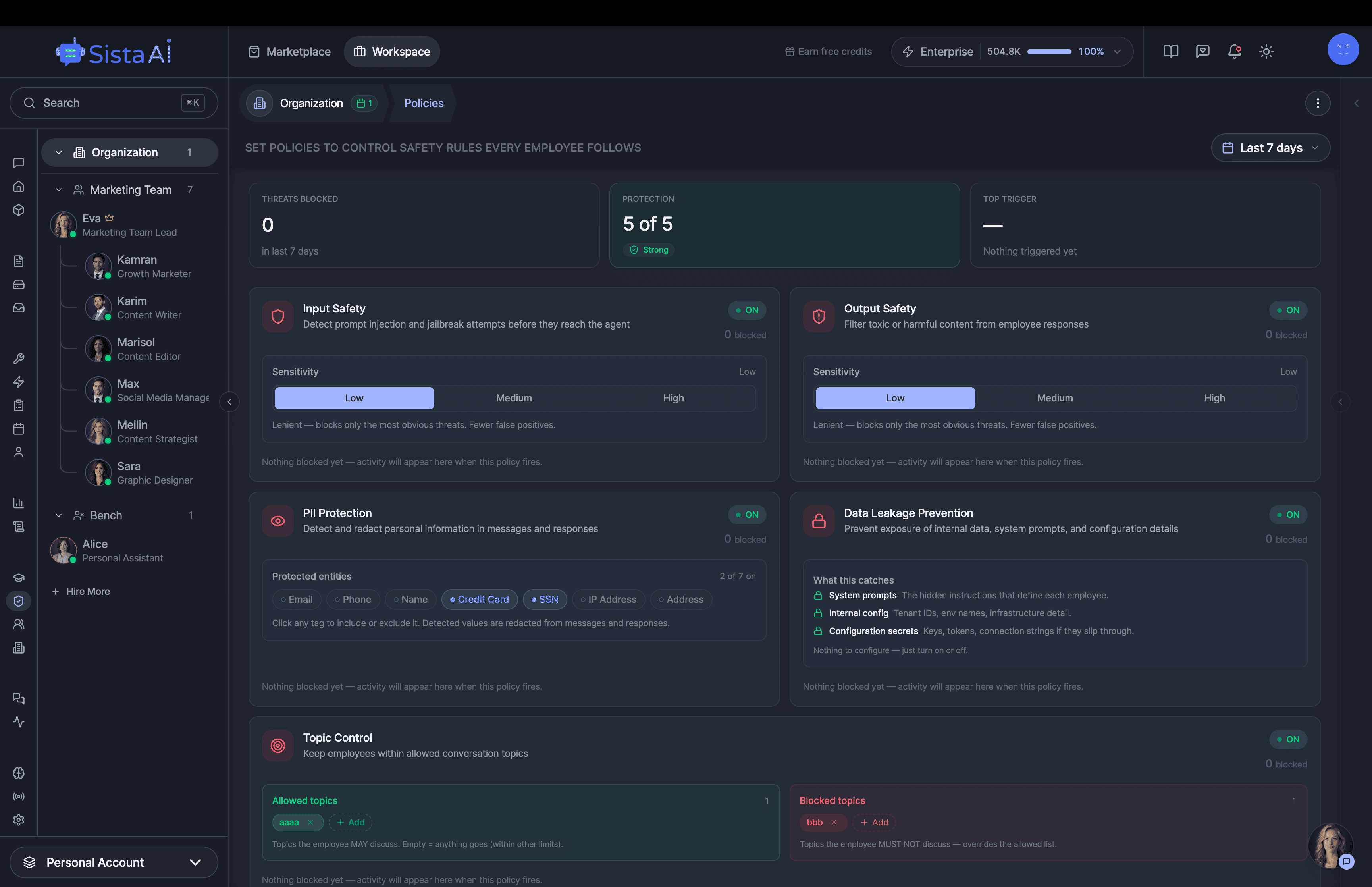
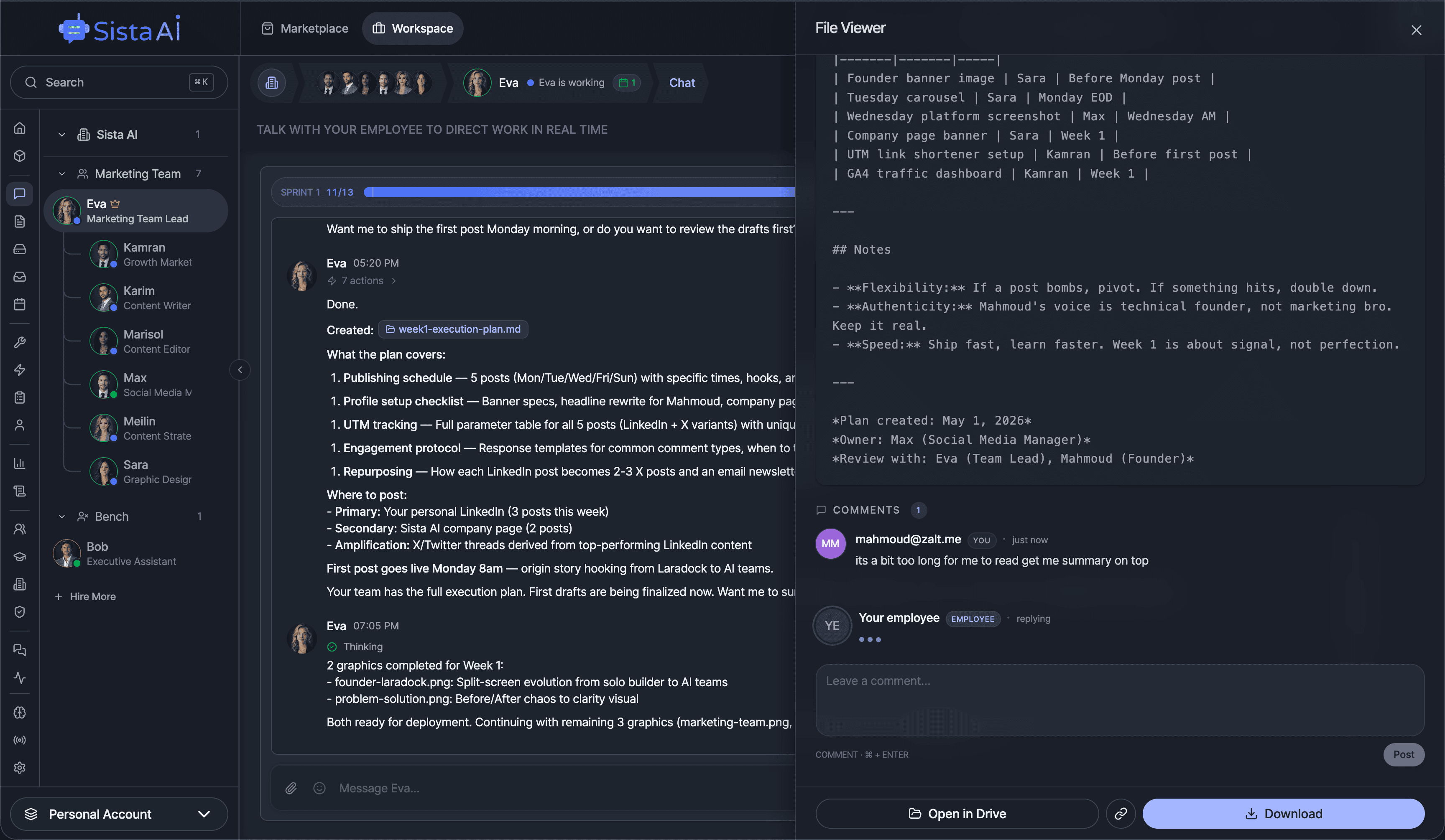
If you're a solo founder looking for AI agents to handle sales, marketing, and ops, check it out, You'll find it valuable. I use it myself to run my business. Your feedback is appreciated.
Building something similar? Let's exchange some knowledge.- Sales outreach
- Persistent memory
- Marketing automation
- MCP integrations
- Browser automation
- RAG knowledge base
- Meeting summaries
- Custom guardrails
- Computer control
- Multi-agent teams
- Ops & admin
- 3D office view
How It Works
Type or paste the text you want spoken aloud.
Choose a voice and speed, then click Generate Speech.
Listen to the AI-generated audio, download it, or try another voice.
Wanna build custom voice experiences?
Real-time streaming, 50+ voices, multi-language. Production TTS that ships.
Key Features
Privacy & Trust
Use Cases
Limitations
- Initial model download is ~92MB on first use
- Generation speed depends on device hardware
- Very long texts may take more time to process
- English only — 28 voices in American and British accents
- Best results with well-punctuated text