One of 55 free AI tools built by Zalt, an AI architect and consultant with 16 years of experience.
Free Speech to Text
Transcribe audio to text for free using OpenAI's Whisper speech recognition model running entirely in your browser. Record from your microphone or upload MP3, WAV, M4A, or other audio files and get accurate transcriptions in seconds. Supports 99 languages with automatic language detection, segment and word-level timestamps, and translation to English. No signup, no server, no API calls — all processing happens locally via WebAssembly using Hugging Face Transformers.js, so your audio never leaves your device.
Loading Speech-to-Text...
Hire AI Employees
Hire AI Employees that work 24/7. No code.Are you a solo founder still doing sales, marketing, and support by hand? Hire AI Employees to run it all for you. They work 24/7, set up with no code, and go live in minutes.


More Free Tools
More than 20 free AI tools.

Hire AI Expert
Mahmoud Zalt · Freelance AI Engineer
What Is Whisper and How Does This Speech to Text Tool Work?
This free speech-to-text tool is powered by OpenAI Whisper, the most widely used open-source automatic speech recognition model available. Whisper was trained on 680,000 hours of multilingual audio data, making it capable of transcribing speech in 99 languages with near-professional accuracy. The model runs entirely in your browser — your audio is never uploaded to any server.
The browser-based implementation uses Hugging Face Transformers.js, a JavaScript library that brings state-of-the-art machine learning models to the web. Transformers.js converts Whisper model weights to ONNX format and executes them via ONNX Runtime compiled to WebAssembly, allowing the full Whisper pipeline to run in a browser tab without any server, plugin, or extension. The models are quantized to 8-bit integers for smaller downloads and faster inference while maintaining high transcription accuracy.
You can record directly from your microphone or upload audio files in MP3, WAV, M4A, WebM, OGG, or FLAC format. Choose from three model sizes — Tiny for fast results on any device, Base for balanced accuracy and speed, or Small for the highest quality. Enable segment or word-level timestamps for subtitle creation, select a specific language to improve accuracy, or translate foreign-language audio to English. The model files are downloaded once and cached in your browser, so repeat visits load almost instantly.
How Whisper Speech Recognition Works in the Browser
This tool is built on Hugging Face Transformers.js, the JavaScript counterpart to the widely-used Python transformers library. Transformers.js provides a pipeline API that mirrors the Python version — creating an automatic speech recognition pipeline is a single function call. Under the hood, it uses ONNX Runtime for inference with WebAssembly (WASM) as the default execution provider and optional WebGPU support for GPU acceleration in supported browsers. Models are loaded as quantized ONNX files from Hugging Face Hub and cached in the browser using the Cache API.
The automatic-speech-recognition pipeline supports several Whisper-specific parameters: return_timestamps (boolean or "word" for word-level precision), language (ISO code to hint the spoken language), task ("transcribe" or "translate" for English translation), chunk_length_s and stride_length_s for processing long audio in overlapping windows, and standard generation config options. Transformers.js supports Whisper Tiny, Base, Small, Medium, and Large model variants, as well as distilled and quantized checkpoints from the ONNX Community on Hugging Face Hub. The library runs in any modern browser, Node.js, Deno, and Bun — making it one of the most versatile options for deploying speech recognition in JavaScript applications.
Need expert help with AI?
Looking for a specialist to help integrate, optimize, or consult on AI systems? Book a one-on-one technical consultation with an experienced AI consultant to get tailored advice.
Q&A SESSION
Got a quick technical question?
Skip the back-and-forth. Get a direct answer from an experienced engineer.
AI Agents Orchestration
To Run Your Business on Autopilot
I'm building a modern AI workforce for deploying autonomous AI agents at scale. Live since 15 April 2026 at www.sistava.com.
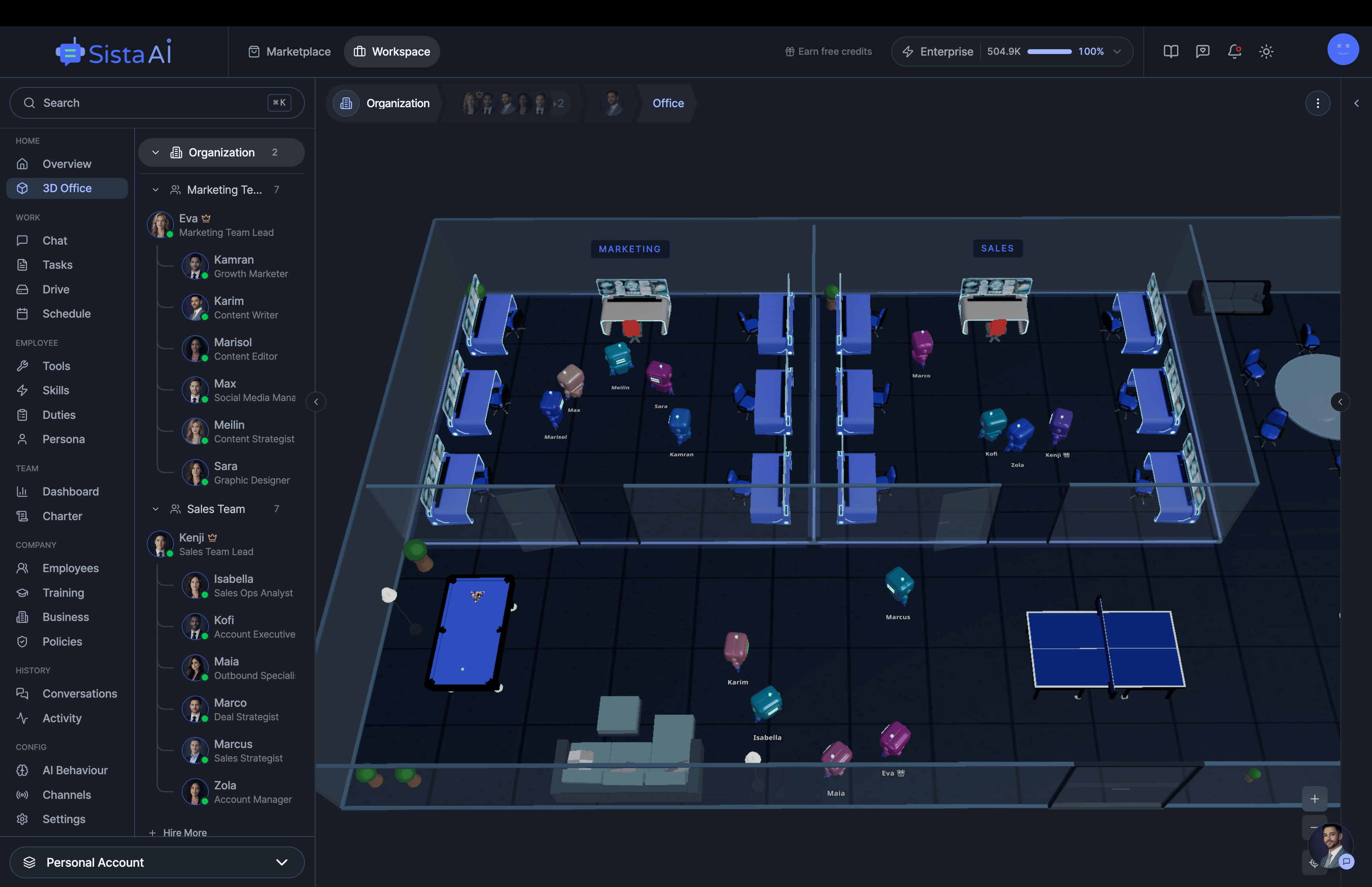
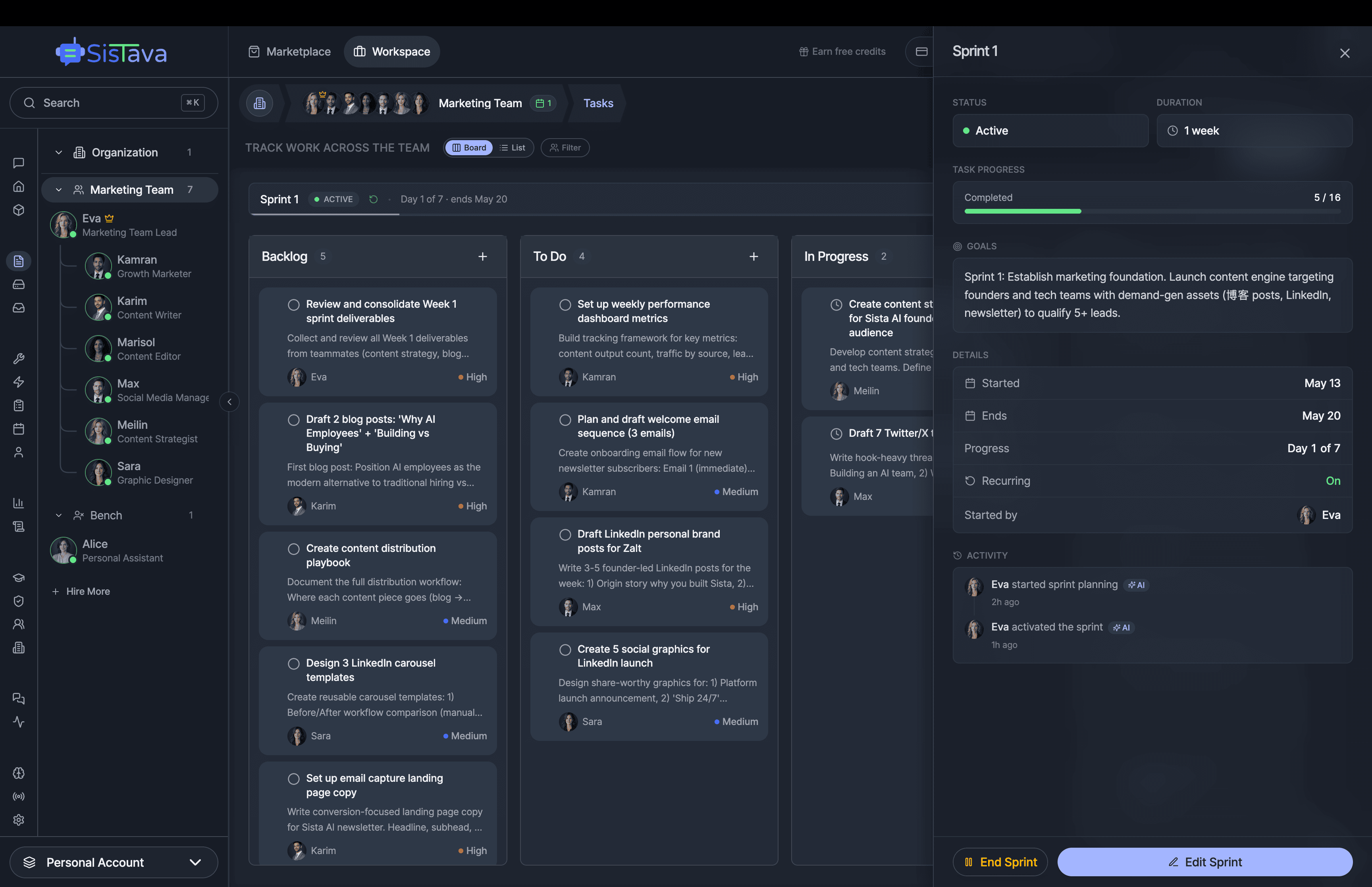
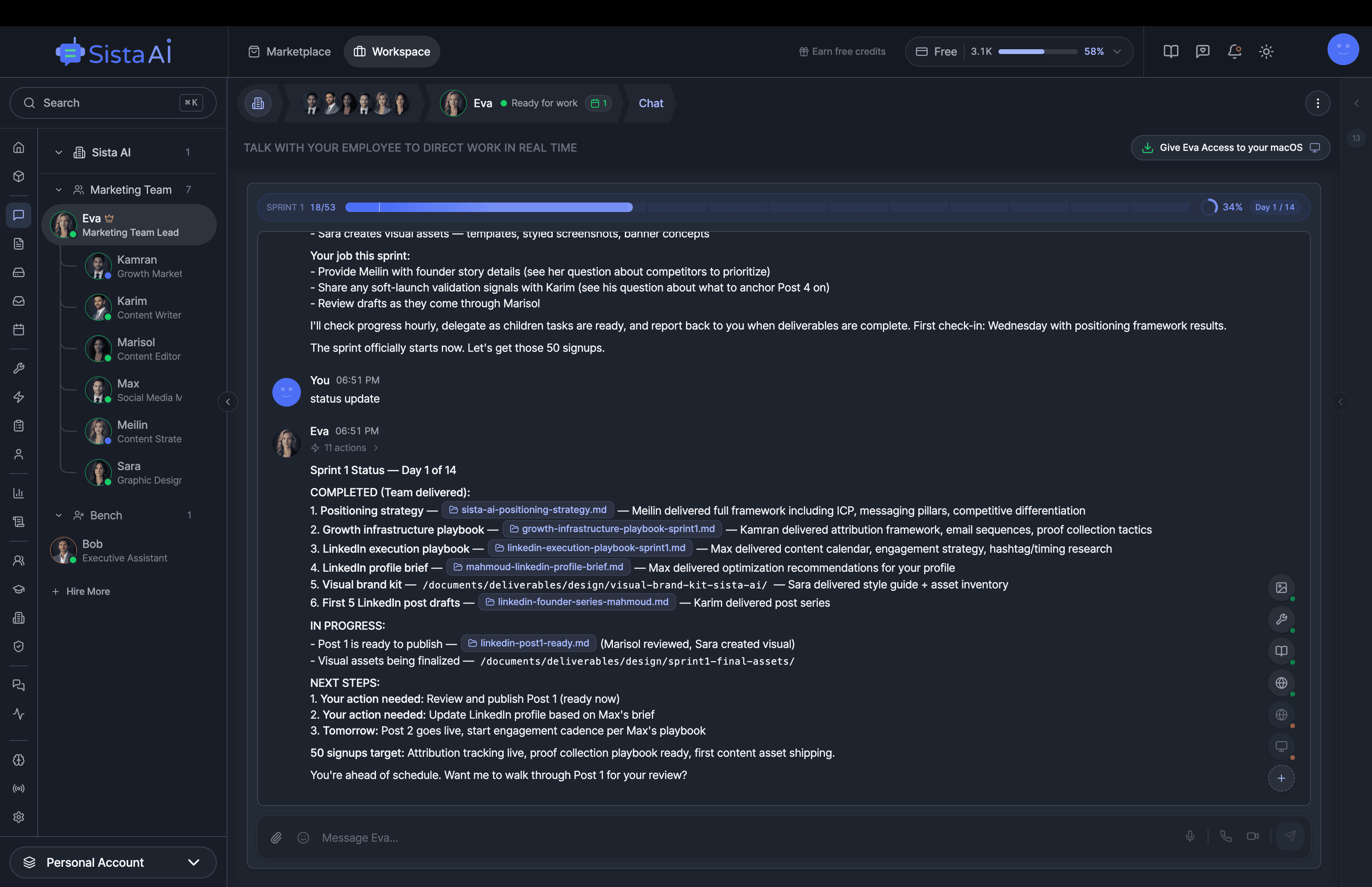
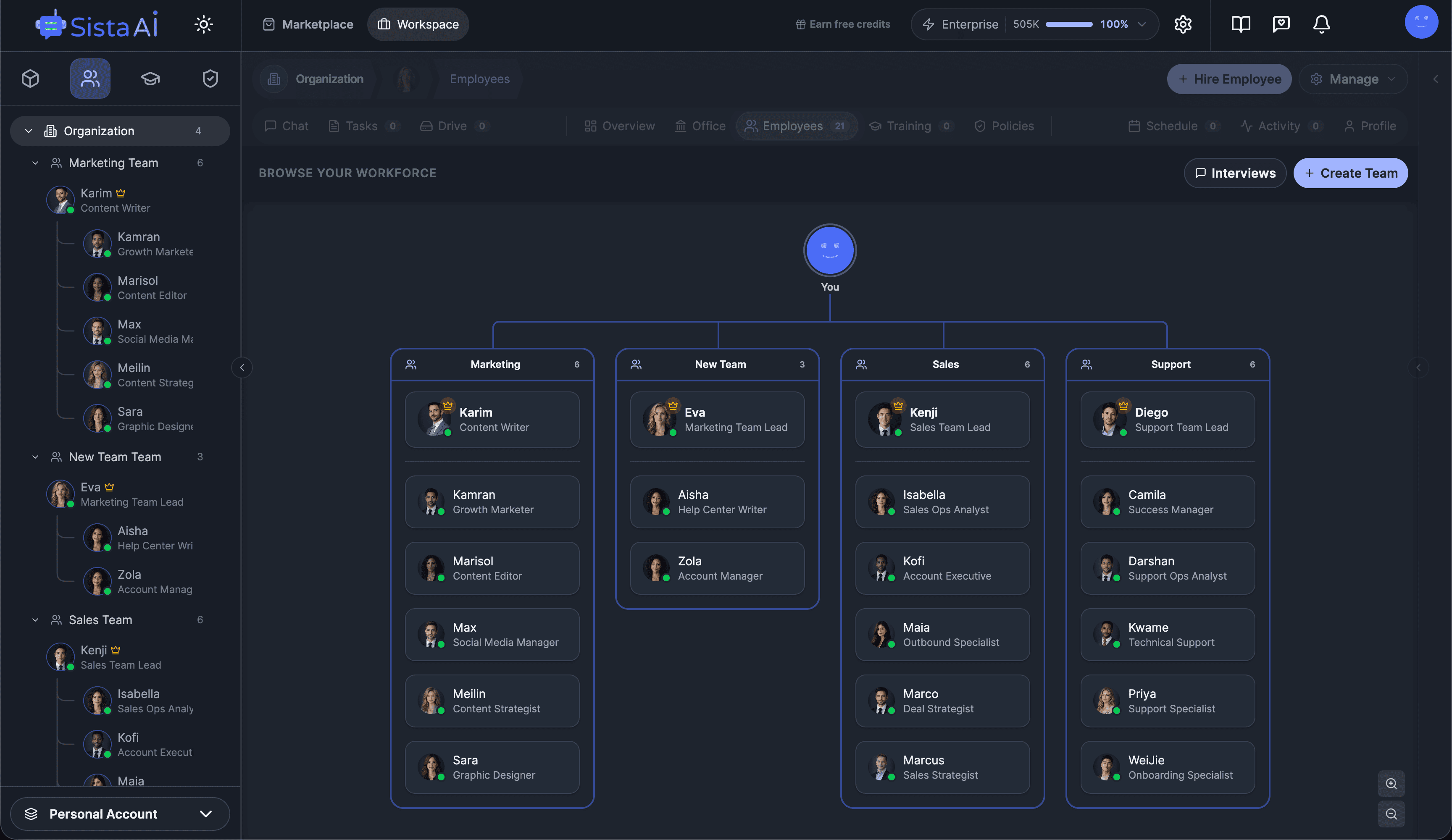
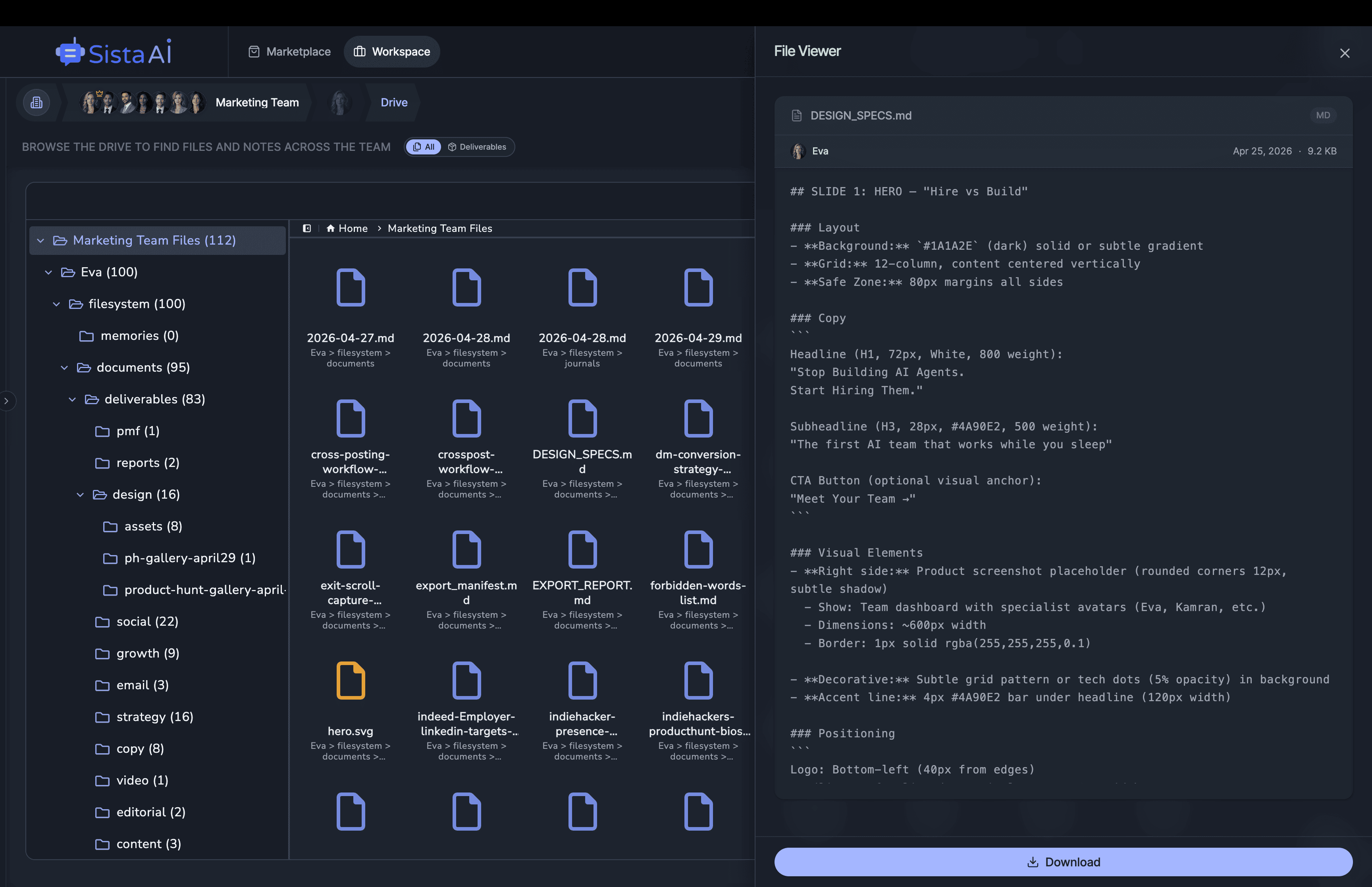
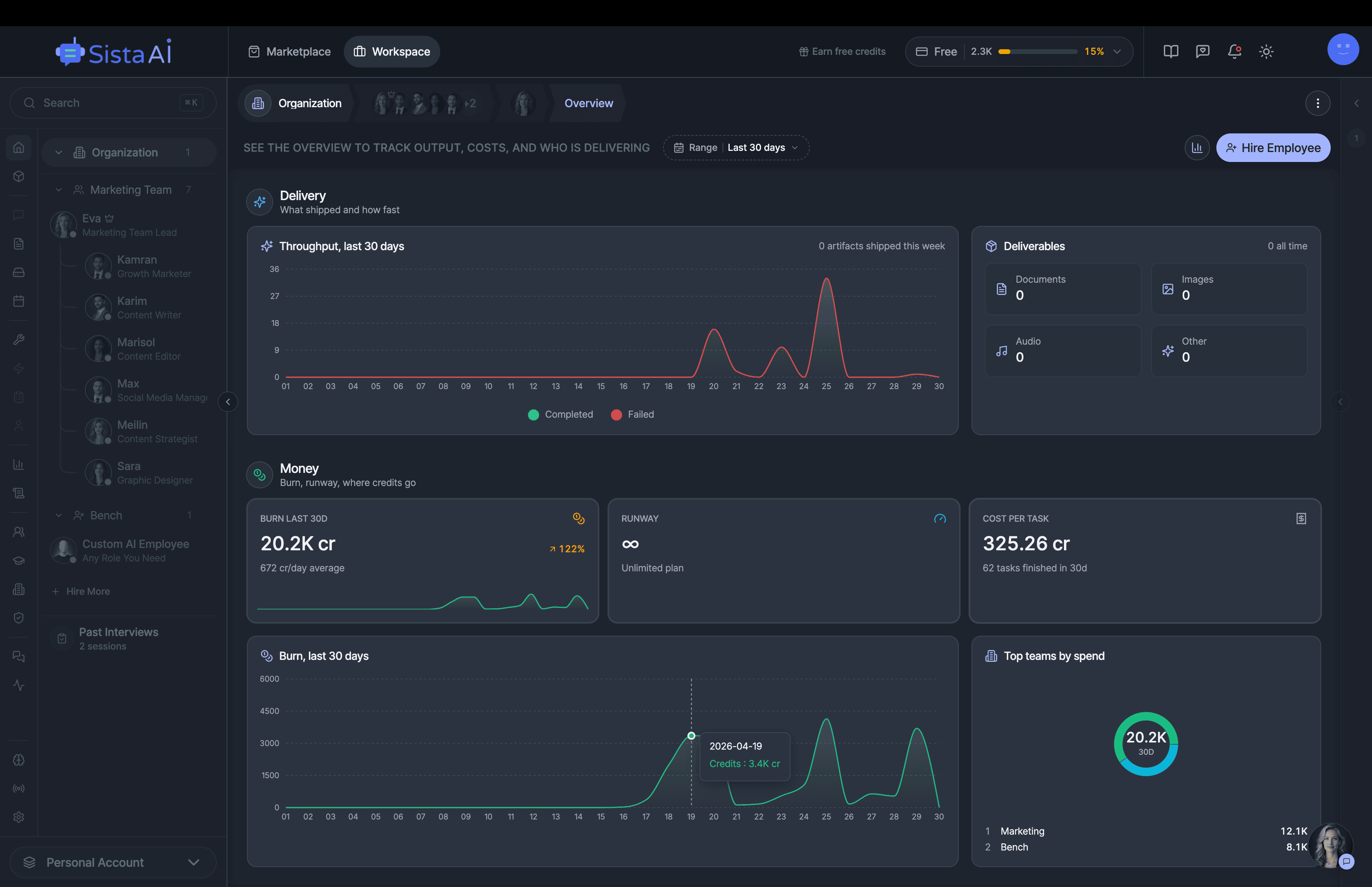

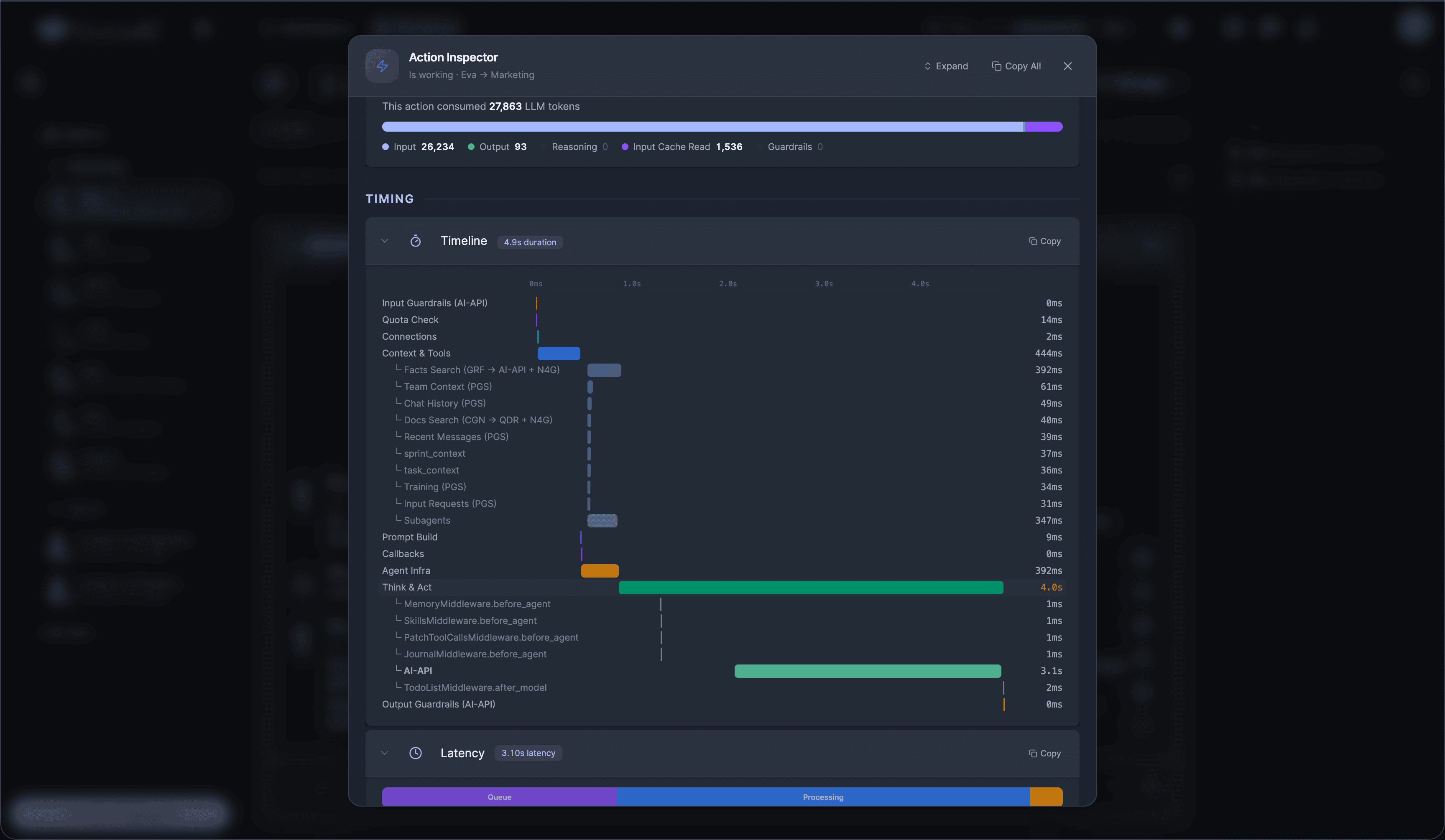
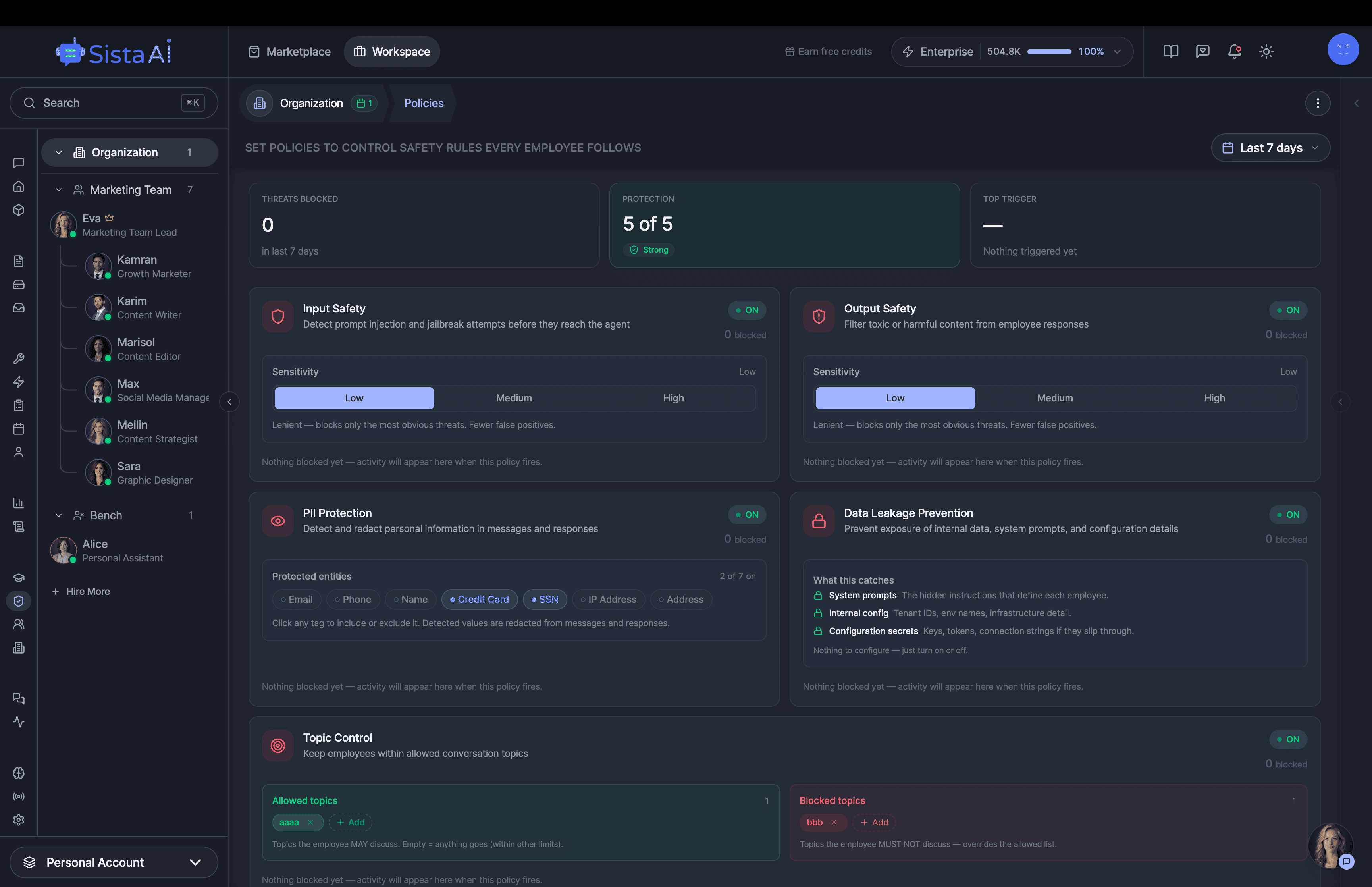
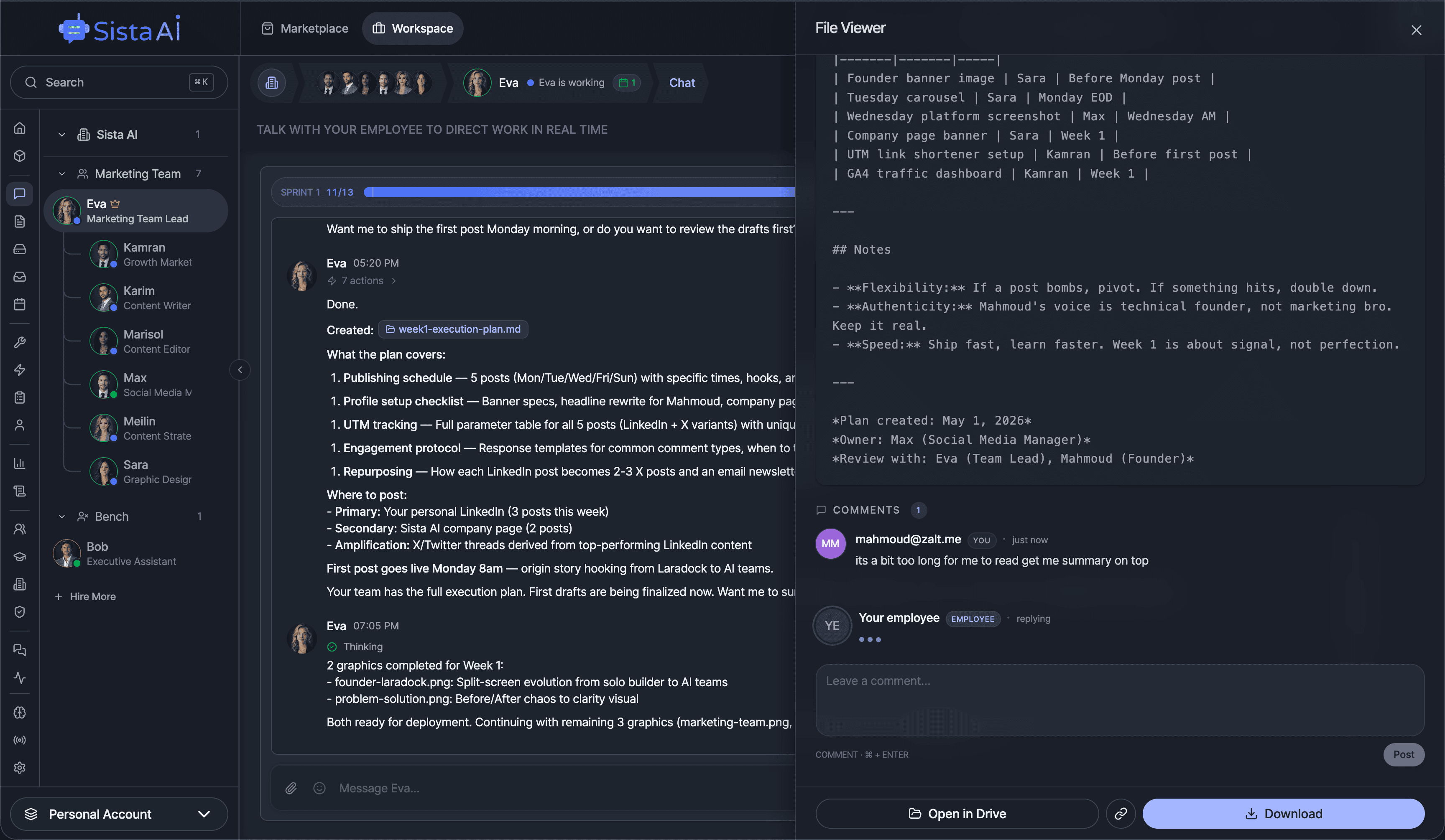
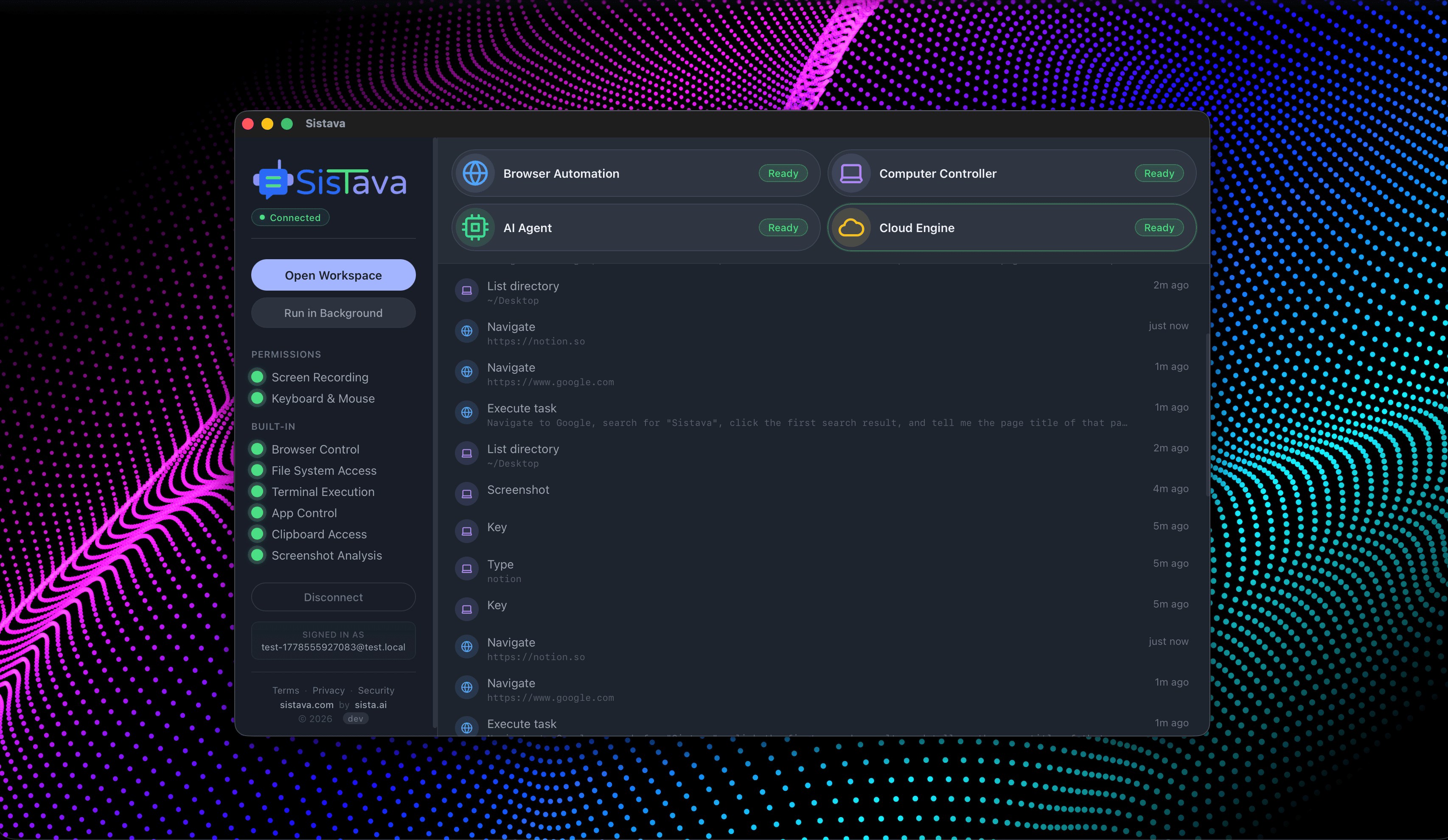
If you're a solo founder looking for AI agents to handle sales, marketing, and ops, check it out, You'll find it valuable. I use it myself to run my business. Your feedback is appreciated.
Building something similar? Let's exchange some knowledge.- Sales outreach
- Persistent memory
- Marketing automation
- MCP integrations
- Browser automation
- RAG knowledge base
- Meeting summaries
- Custom guardrails
- Computer control
- Multi-agent teams
- Ops & admin
- 3D office view
How It Works
Choose a model, language, and timestamp mode, then record or upload audio.
The AI transcribes your speech to text instantly on your device — with optional timestamps.
Copy the transcription or download it as a text file.
Production voice transcription.
Real-time streaming, multi-language, speaker detection. Built into your product, not a browser tab.
Key Features
Privacy & Trust
Use Cases
Limitations
- Initial model download may take 1-2 minutes on first use (cached for future visits)
- Transcription speed depends on your device hardware
- Best results with clear audio and minimal background noise
- Maximum audio length depends on available device memory
- Larger models require more RAM and take longer to load
- Overlapping speakers may reduce transcription accuracy
- Word-level timestamps may be less precise than segment-level timestamps