#01AIAI Utility
AI Knowledge Studio
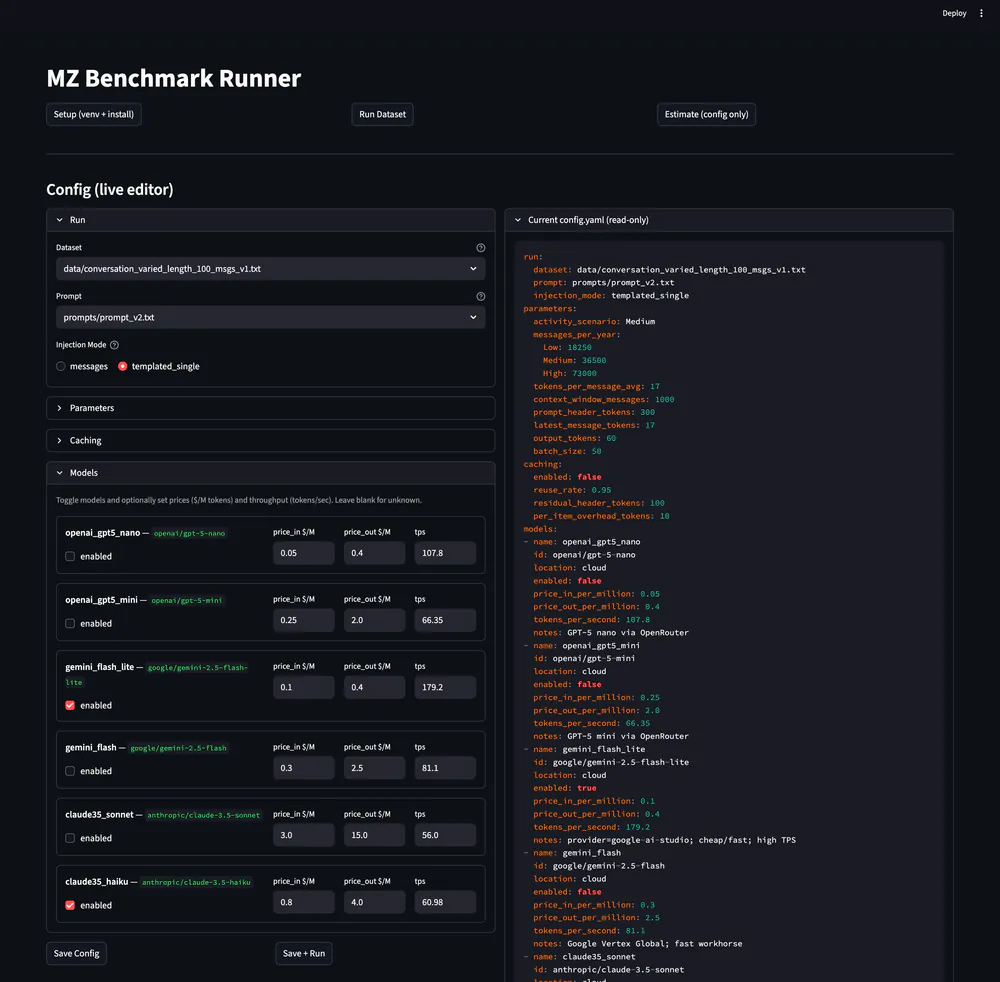
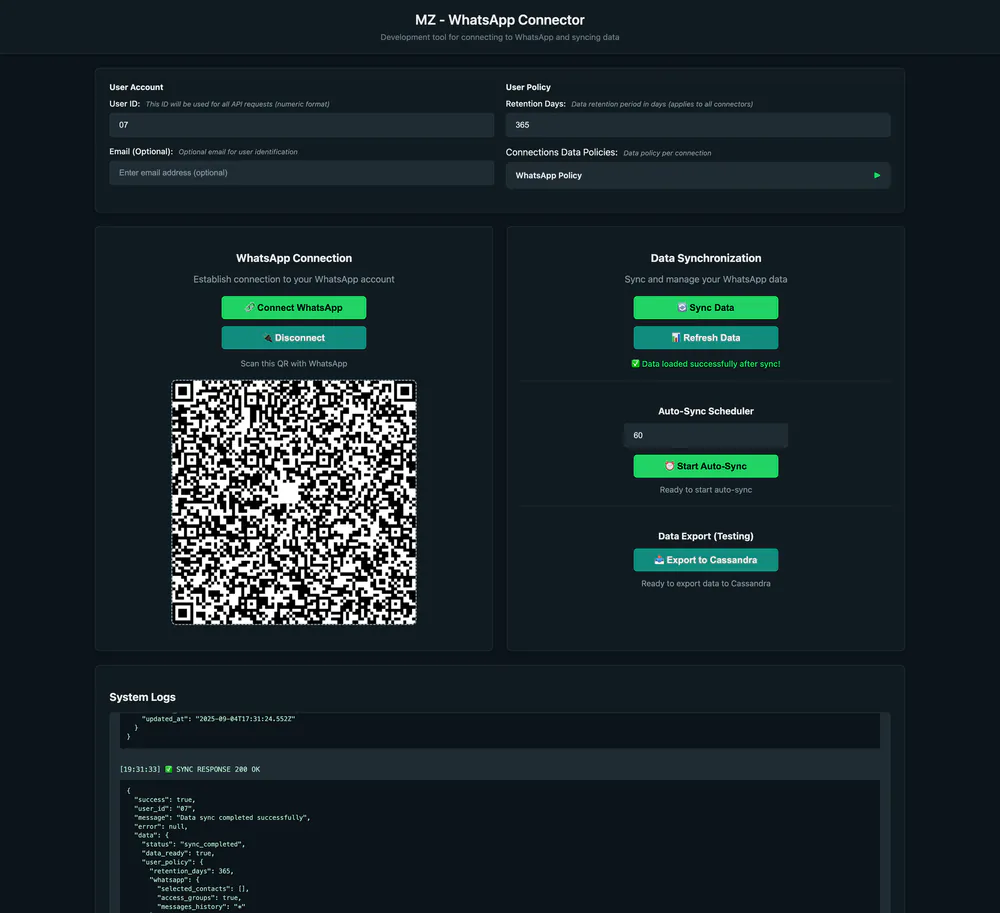
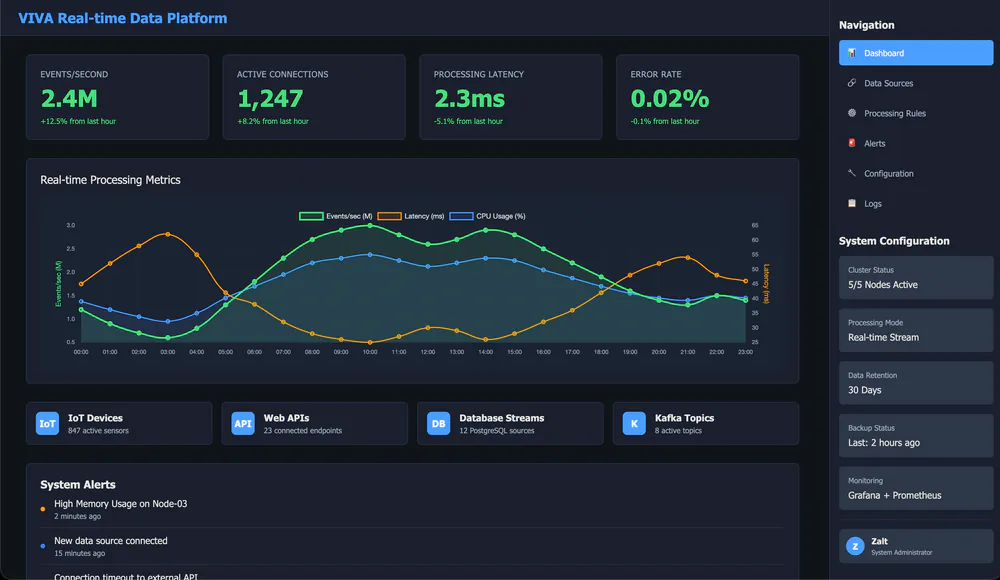
Built a chat-first analytics assistant that answers natural-language questions over real-time metrics while keeping data and inference inside private infrastructure.
6-10 secMedian response time
90-95%Query success rate
<2 minData freshness
5-8B eventsData scale
70B paramsModel size
Problem
Teams were exporting telemetry and KPI data into ad-hoc spreadsheets. Answers were slow, inconsistent, and security requirements ruled out sending data to external LLM APIs.
Solution
A lightweight chat UI backed by a query service that routes questions to the appropriate data source, executes safe queries, and returns summaries with computed results, all within private infrastructure.
Goals
- 1Answer common analytics questions in under 10 seconds end to end.
- 2Support averages, rankings, and grouped comparisons across billions of events.
- 3Keep data fresh with sub-2 minute lag from ingestion to query.
- 4Provide explainable results with the exact query used.
- 5Keep data and inference inside private infrastructure (no external data egress).
- 6Capture traces and feedback to improve accuracy over time.
Approach
- Used a natural-language query engine to generate SQL over both real-time event streams and relational metadata without duplicating data.
- Separated high-cardinality real-time metrics from reference data and access control into dedicated storage layers.
- Deployed all data stores inside a private cloud VPC with strict network boundaries.
- Self-hosted inference with a fine-tuned 70B-parameter model on dedicated GPU servers to control cost and latency.
- Built an observability pipeline to log prompts, generated queries, and outcomes for evaluation and continuous tuning.
Outcomes
- Delivered near real-time analytics without a separate warehouse or external LLM APIs.
- Reduced analysis time from hours of exports to minutes of Q&A.
- Improved trust by exposing the exact query and result context.
Challenges
- Preventing unsafe or expensive queries from untrusted prompts.
- Handling ambiguous questions across two data sources.
- Balancing explainability with concise answers in a chat UI.
Built with:MindsDBLangfuseLLaMAvLLMOllamaClickHousePostgreSQLKafka+7 more
View Project Details