100% Private
Runs fully in your browser. Nothing sent to any server. Ever.
No Signup
No account, no API keys. Open and use it instantly.
Free Forever
Permanently free. No trials, no limits, no credit card.
One of 55 free AI tools built by Zalt, an AI architect and software engineer.
Free Regex Tester
Write a regex pattern and instantly see every match highlighted in your test string as you type. The tool displays full match details including numbered and named capture groups, match indices, and the effect of each flag. Supports all modern ECMAScript regex features — lookahead, lookbehind, named groups, Unicode property escapes, and the dotall flag. Six flag controls let you toggle global, case-insensitive, multiline, dotall, Unicode, and sticky modes. All processing runs locally in your browser using the native JavaScript regex engine — no data is sent anywhere, ever.
Hire AI Employees
Hire AI Employees that work 24/7. No code.Are you a solo founder still doing sales, marketing, and support by hand? Hire AI Employees to run it all for you. They work 24/7, set up with no code, and go live in minutes.


More Free Tools
More than 20 free AI tools.

Hire AI Expert
Mahmoud Zalt · Freelance AI Engineer
Why Use a Regex Tester?
Regular expressions are one of the most powerful tools in a developer's toolkit, but they are notoriously difficult to get right. A single misplaced character can change what a pattern matches entirely. A misplaced quantifier can turn a fast pattern into one that freezes your browser with catastrophic backtracking. This regex tester gives you instant visual feedback — every match is highlighted in your test string as you type, so you can iterate on your pattern and immediately see the results without switching between your code editor and a terminal.
The tool uses the JavaScript (ECMAScript) regex engine built into your browser — the same engine used by Node.js, Deno, and all major browsers. It supports modern features including named capture groups (?<name>...), lookahead (?=...) and lookbehind (?<=...) assertions, Unicode property escapes (\p{Letter}, \p{Emoji}), the dotall flag (s), and inline modifier flags added in ECMAScript 2025. Match details show the full match text, numbered and named capture groups, and exact character indices — everything you need to debug and refine your patterns before deploying them in production code.
Common Regex Patterns and How to Build Them
Most regex work falls into a handful of categories: validating input formats (email, phone, IP address), extracting structured data (dates, URLs, log fields), and transforming text (search-and-replace, cleanup). For email validation, a practical pattern like ^[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}$ covers the majority of real-world addresses. For URLs, ^https?:\/\/[\w\-]+(\.[\w\-]+)+[\/\w\-.,@?^=%&:~+#]*$ handles HTTP and HTTPS with paths and query strings. For IPv4 addresses, ^((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)$ precisely validates each octet in the 0-255 range.
The key to building reliable patterns is to start simple and add constraints incrementally. Begin with a broad match, then tighten character classes, add anchors (^ and $), and test against both valid and invalid inputs. Use non-capturing groups (?:...) when you need grouping for alternation or quantifiers but do not need the matched text in your results. Use named capture groups when you need to extract specific fields — they make the pattern self-documenting and the extraction code far more readable than numeric indices.
JavaScript Regex vs Other Engines — What You Need to Know
The JavaScript regex engine (ECMAScript) covers the vast majority of everyday regex needs, but it differs from other popular engines in specific ways. PCRE — used by PHP (preg_ functions), R, and many command-line tools — supports recursive patterns (?R) for matching nested structures like balanced parentheses, conditional expressions (?(id)yes|no), possessive quantifiers (a++) that never backtrack, and atomic groups (?>...) for performance optimization. Python re uses (?P<name>...) syntax for named groups and supports a VERBOSE flag that allows inline comments and whitespace for readability. .NET regex adds balancing groups for matching nested constructs and right-to-left matching mode.
For everyday patterns — character classes, quantifiers, alternation, anchors, lookahead, lookbehind, and capture groups — all major engines behave identically. If your pattern works in this tester and does not rely on engine-specific features, it will work in Python, PHP, Java, Go, Ruby, and C#. When you do need engine-specific features, test in that language directly or use a multi-engine tool. This tester is ideal for the 95% of patterns that are portable across all engines, with the advantage that your data stays completely private on your device.
How It Works
Type your regex pattern and select flags.
Paste or type your test string to see matches highlighted live.
View match details including capture groups and indices.
Need expert help with AI?
Looking for a specialist to help integrate, optimize, or consult on AI systems? Book a one-on-one technical consultation with an experienced AI consultant to get tailored advice.
Key Features
Privacy & Trust
Use Cases
Limitations
- Uses JavaScript regex engine (may differ from PCRE, Python re, or .NET regex)
- Does not support lookbehind in older browsers
- Does not explain what the regex does in plain English
- No regex library or cheat sheet built in
Q&A SESSION
Got a quick technical question?
Skip the back-and-forth. Get a direct answer from an experienced engineer.
Frequently Asked Questions
Is this Regex Tester free?
Yes, it is 100% free with no usage limits, no signup, and no per-use charges. Popular alternatives like regex101.com are also free but send your patterns and test strings to a server for processing. Because this tool runs the regex engine natively in your browser, there are no server costs and no data ever leaves your device. You can use it as much as you want for as long as you want.
Is my text sent to a server or stored anywhere?
No. All regex matching happens entirely inside your browser using the built-in JavaScript regex engine. Your patterns and test strings are never transmitted, logged, or stored — not even temporarily. There are no API calls, no cloud processing, and no analytics on your input. This makes it safe for testing patterns against sensitive data like internal log files, customer records, API keys, or any text you would not want a third party to see. You can verify this by checking the Network tab in DevTools while using the tool.
What is a regular expression (regex)?
A regular expression (regex or regexp) is a sequence of characters that defines a search pattern. It is used to match, find, and manipulate text. For example, the pattern \d{3}-\d{4} matches a 3-digit number, a dash, and a 4-digit number — like a phone number fragment "555-1234". Regular expressions are supported in virtually every programming language (JavaScript, Python, Java, PHP, Go, Ruby, C#) and in tools like grep, sed, and most text editors. They are essential for input validation, data extraction, search-and-replace, log parsing, and web scraping.
Which regex engine does this tool use?
This tool uses the JavaScript (ECMAScript) regex engine built into your browser. It is the same engine used by Node.js, Deno, Bun, and browser-based JavaScript. It supports character classes (\d, \w, \s), quantifiers (+, *, ?, {n,m}), alternation (|), anchors (^, $, \b), lookahead (?=...) and lookbehind (?<=...) assertions, named capture groups (?<name>...), backreferences (\1, \k<name>), Unicode property escapes (\p{Letter}), and the dotall flag (s). As of ECMAScript 2025, inline modifier flags ((?i:...)) are also supported in modern browsers.
What do the regex flags (g, i, m, s, u, y) mean?
Each flag changes how the regex engine processes the pattern. g (global) finds all matches in the string instead of stopping at the first. i (case-insensitive) treats uppercase and lowercase letters as equivalent — /abc/i matches "ABC", "Abc", and "abc". m (multiline) makes ^ and $ match the start and end of each line, not just the start and end of the entire string. s (dotall) makes the dot (.) match newline characters (\n), which it normally skips. u (unicode) enables full Unicode matching, treating surrogate pairs as single code points and enabling \p{...} property escapes for matching categories like letters, numbers, or scripts. y (sticky) forces the match to start at the exact position of lastIndex, useful for tokenizers and parsers that process input sequentially.
What are capture groups and named capture groups?
Capture groups are parts of the regex enclosed in parentheses (). They let you extract specific portions of a match. For example, (\d{4})-(\d{2})-(\d{2}) applied to "2026-04-05" captures "2026" in group 1, "04" in group 2, and "05" in group 3. Named capture groups use the syntax (?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2}), letting you reference captures by name (match.groups.year) instead of by index. Named groups make complex patterns far more readable and maintainable. Non-capturing groups (?:...) group tokens without creating a capture, which is useful when you need grouping for alternation or quantifiers but do not need the matched text.
What are lookahead and lookbehind assertions?
Lookahead and lookbehind are zero-width assertions — they check whether a pattern exists before or after the current position without consuming characters. Positive lookahead (?=...) matches if the pattern ahead exists: \d+(?= dollars) matches "100" in "100 dollars" but not in "100 euros". Negative lookahead (?!...) matches if the pattern ahead does not exist. Positive lookbehind (?<=...) matches if the pattern behind exists: (?<=\$)\d+ matches "50" in "$50". Negative lookbehind (?<!...) matches if the pattern behind does not exist. Lookbehind was added in ECMAScript 2018 and is supported in all modern browsers (Chrome, Firefox, Safari 16.4+, Edge).
What are some common regex patterns for email, URL, phone, and IP address?
Here are practical patterns: Email (basic): ^[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}$ — matches standard email format. URL: ^https?:\/\/[\w\-]+(\.[\w\-]+)+[\/\w\-.,@?^=%&:~+#]*$ — matches HTTP and HTTPS URLs. US phone: ^(\+1[\s.-]?)?\(?\d{3}\)?[\s.-]?\d{3}[\s.-]?\d{4}$ — matches formats like (555) 123-4567 and +1-555-123-4567. IPv4: ^((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)$ — validates each octet is 0-255. Date (YYYY-MM-DD): ^\d{4}-(0[1-9]|1[0-2])-(0[1-9]|[12]\d|3[01])$. These patterns validate format only — they do not verify that an email domain exists or a date is real.
What is catastrophic backtracking and how do I avoid it?
Catastrophic backtracking occurs when a regex engine takes an exponentially long time to determine that a string does not match a pattern. It happens with nested quantifiers like (a+)+ or patterns where many paths must be explored before failing. For example, the pattern (a+)+b against the string "aaaaaaaaaaaaaaaaac" forces the engine to try billions of combinations before concluding there is no match — potentially freezing your browser tab. To avoid it: (1) never nest quantifiers without constraints — use a+ instead of (a+)+, (2) use atomic grouping or possessive quantifiers in engines that support them, (3) make patterns fail fast by anchoring them or using more specific character classes, and (4) test your patterns against long strings that should not match to catch performance issues early.
How does JavaScript regex differ from PCRE (PHP), Python re, and .NET regex?
The most significant differences: PCRE (used by PHP, R, and many tools) supports recursive patterns (?R), conditional expressions (?(id)yes|no), possessive quantifiers (a++), atomic groups (?>...), and variable-length lookbehind — none of which are available in JavaScript. Python re uses (?P<name>...) syntax for named groups instead of JavaScript (?<name>...) and supports the VERBOSE flag for inline comments. .NET regex supports balancing groups for matching nested structures and right-to-left matching. JavaScript lacks all of these but has excellent Unicode support via the u flag and \p{} property escapes. For most everyday patterns — character classes, quantifiers, alternation, lookahead, basic lookbehind, and capture groups — all engines behave identically.
Does JavaScript regex support Unicode and emoji matching?
Yes, with the u (unicode) flag enabled. Without the u flag, JavaScript treats strings as sequences of 16-bit code units, which means characters outside the Basic Multilingual Plane (like emoji) are seen as two separate surrogate code units. With the u flag, surrogate pairs are treated as single code points, and you can use Unicode property escapes: \p{Letter} matches any letter in any script, \p{Emoji} matches emoji, \p{Script=Greek} matches Greek characters, and \p{Number} matches digits in any numeral system. You can also use \u{1F680} to match specific code points. The v flag (unicodeSets), added in ECMAScript 2024, extends this further with set operations for character classes.
How does this compare to regex101.com and regexr.com?
Regex101 is the most feature-rich online regex tester — it supports multiple engines (PCRE, Python, JavaScript, Go, Java, C#, Rust), provides a plain-English explanation of your pattern, generates code snippets, and has a community pattern library. RegExr focuses on learning with a built-in cheat sheet and community patterns. Both tools send your patterns and test strings to a server for processing. This tool is deliberately simpler and prioritizes privacy: all matching happens locally in your browser, your data never touches a server, and there is nothing to sign up for. If you need multi-engine support or pattern explanations, use regex101. If you want a fast, private tester for JavaScript regex, this tool is the better choice.
Can I use this tool to test regex for Python, PHP, Java, or Go?
For basic and intermediate patterns — character classes, quantifiers, alternation, anchors, lookahead, capture groups — JavaScript regex behaves identically to Python re, PCRE (PHP), Java, and Go. You can confidently test these patterns here. However, if your pattern uses engine-specific features like PCRE recursive patterns, Python verbose mode, .NET balancing groups, or Java possessive quantifiers, the behavior will differ. For those cases, test in the target language directly or use a multi-engine tool like regex101.com. As a rule of thumb: if your pattern works here and does not use features specific to another engine, it will work in your target language.
What are backreferences and how do they work?
Backreferences let you match the same text that was previously captured by a group. The syntax \1 refers to the text captured by the first group, \2 to the second, and so on. For example, (\w+)\s+\1 matches a repeated word like "the the" — the \1 must match exactly the same text as the first capture group. With named groups, you can use \k<name> as a backreference: (?<word>\w+)\s+\k<word>. Backreferences are useful for detecting duplicates, matching paired delimiters (like matching an opening and closing HTML tag), and validating symmetric patterns. Note that backreferences make the regex non-regular in the formal computer science sense — they add computational power beyond what a finite automaton can handle.
How can I learn regular expressions from scratch?
Start with literal character matching and build up incrementally. Learn character classes first (\d for digits, \w for word characters, \s for whitespace, . for any character), then quantifiers (+ for one or more, * for zero or more, ? for optional, {n,m} for a range). Next learn anchors (^ for start, $ for end, \b for word boundary) and alternation (|). Practice with real tasks — matching email addresses, extracting dates from text, or finding URLs in a log file. Once comfortable, learn groups and backreferences, then lookahead and lookbehind. This tool is ideal for learning because you see results instantly — every change to your pattern updates the highlighted matches in real time. Recommended resources include regular-expressions.info for comprehensive reference and javascript.info/regular-expressions for JavaScript-specific tutorials.
What is the difference between greedy and lazy quantifiers?
By default, quantifiers in regex are greedy — they match as much text as possible. The pattern <.+> applied to "<b>bold</b>" matches the entire string "<b>bold</b>" because .+ consumes everything and only backtracks enough to find the last >. Adding a ? makes the quantifier lazy (also called reluctant) — it matches as little text as possible. The pattern <.+?> matches "<b>" and "</b>" separately because .+? stops at the first >. Lazy quantifiers are essential when extracting content between delimiters. The same ? modifier works on all quantifiers: *? (lazy star), +? (lazy plus), ?? (lazy optional), and {n,m}? (lazy range). Understanding greedy vs. lazy behavior is one of the most important regex concepts for avoiding unexpected matches.
AI Agents Orchestration
To Run Your Business on Autopilot
I'm building a modern AI workforce for deploying autonomous AI agents at scale. Live since 15 April 2026 at www.sistava.com.
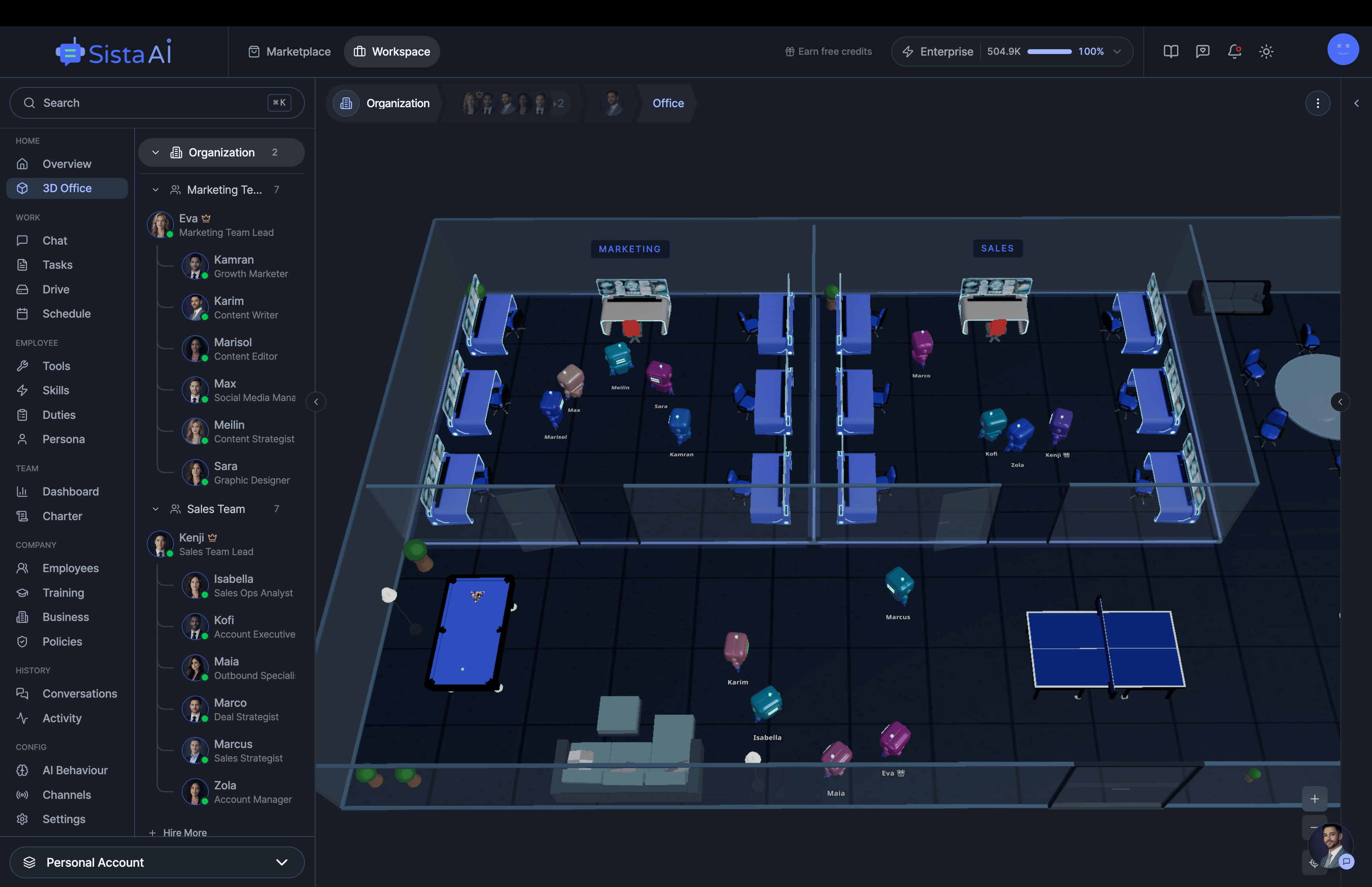
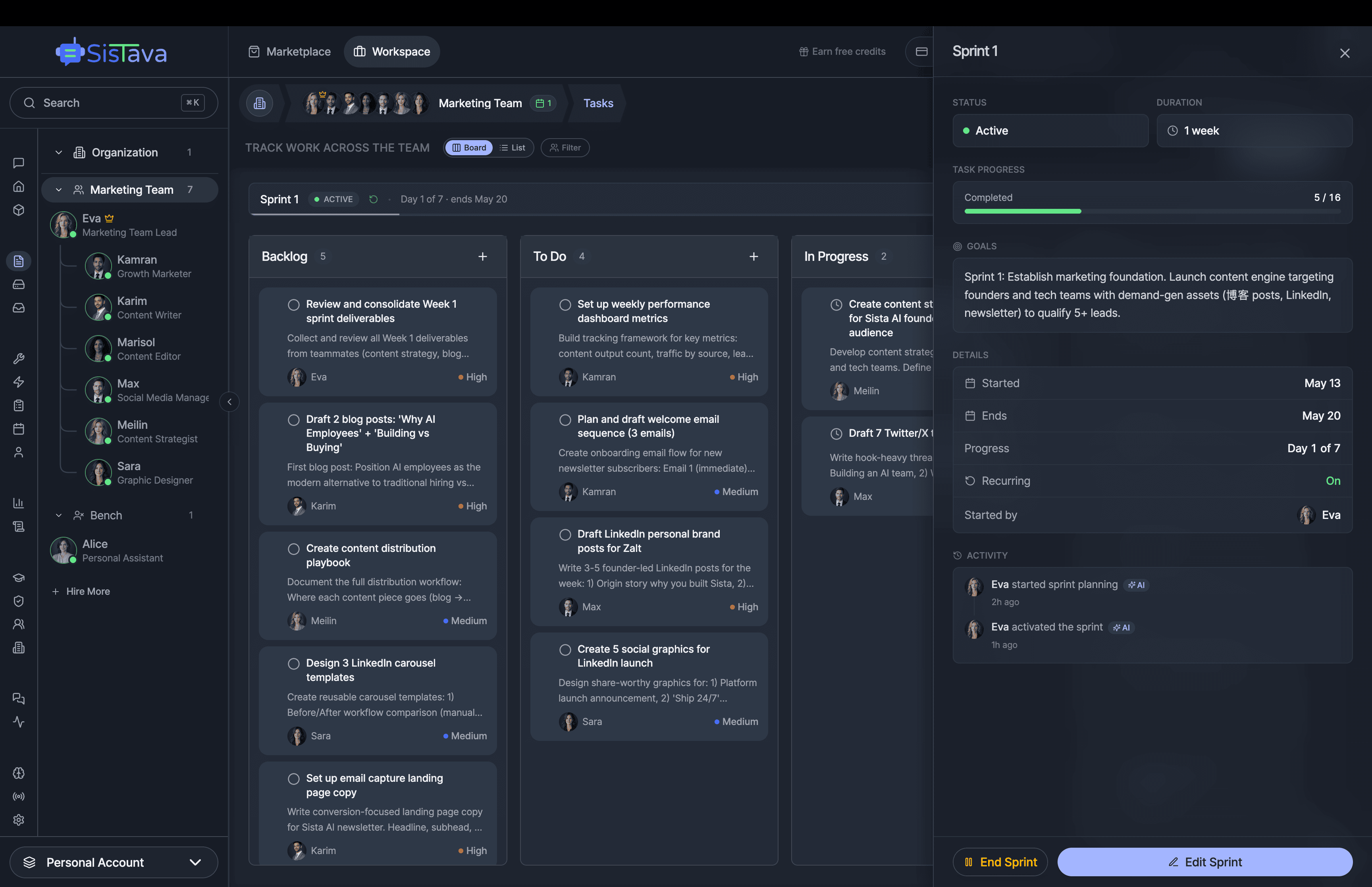
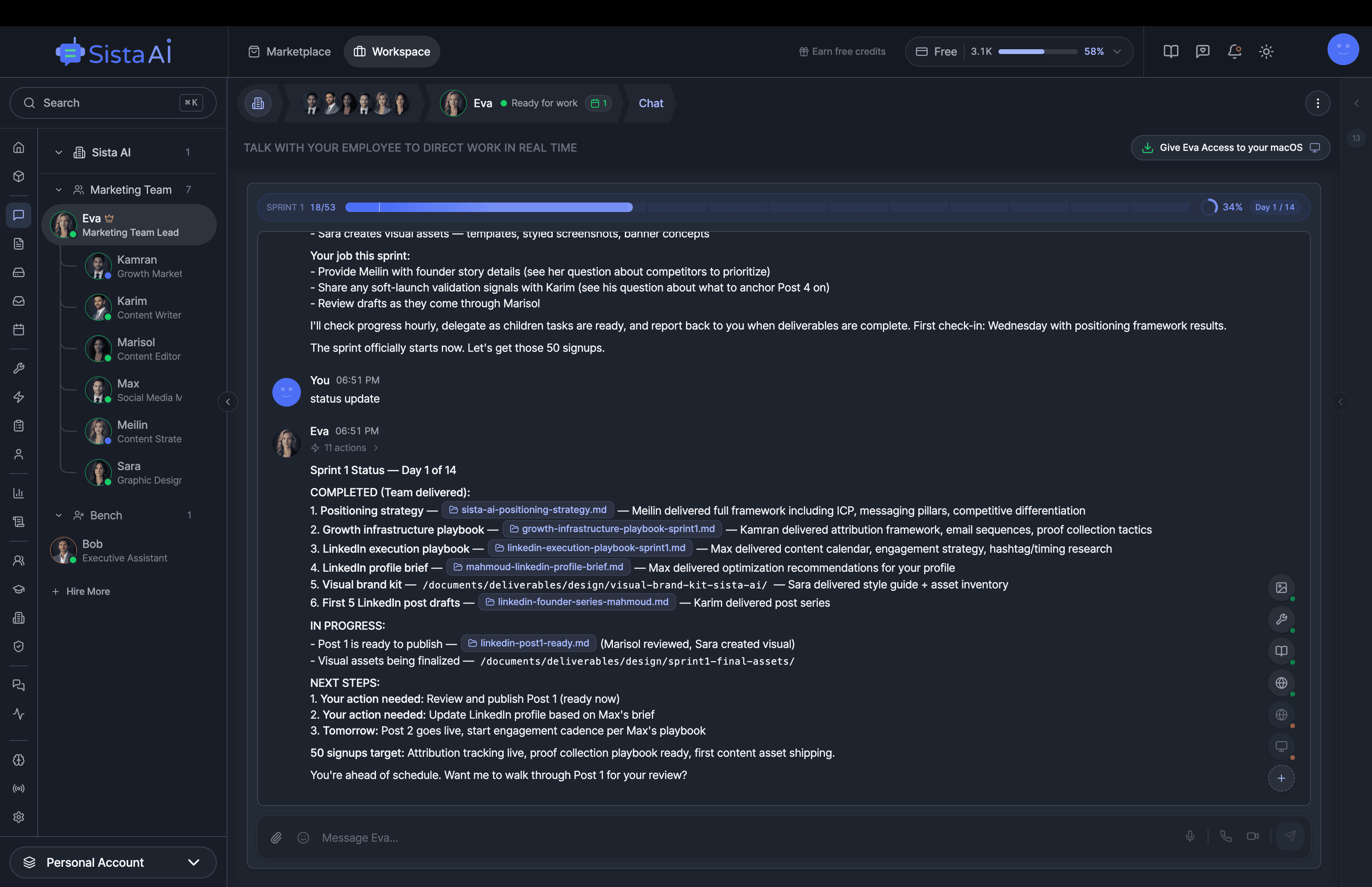
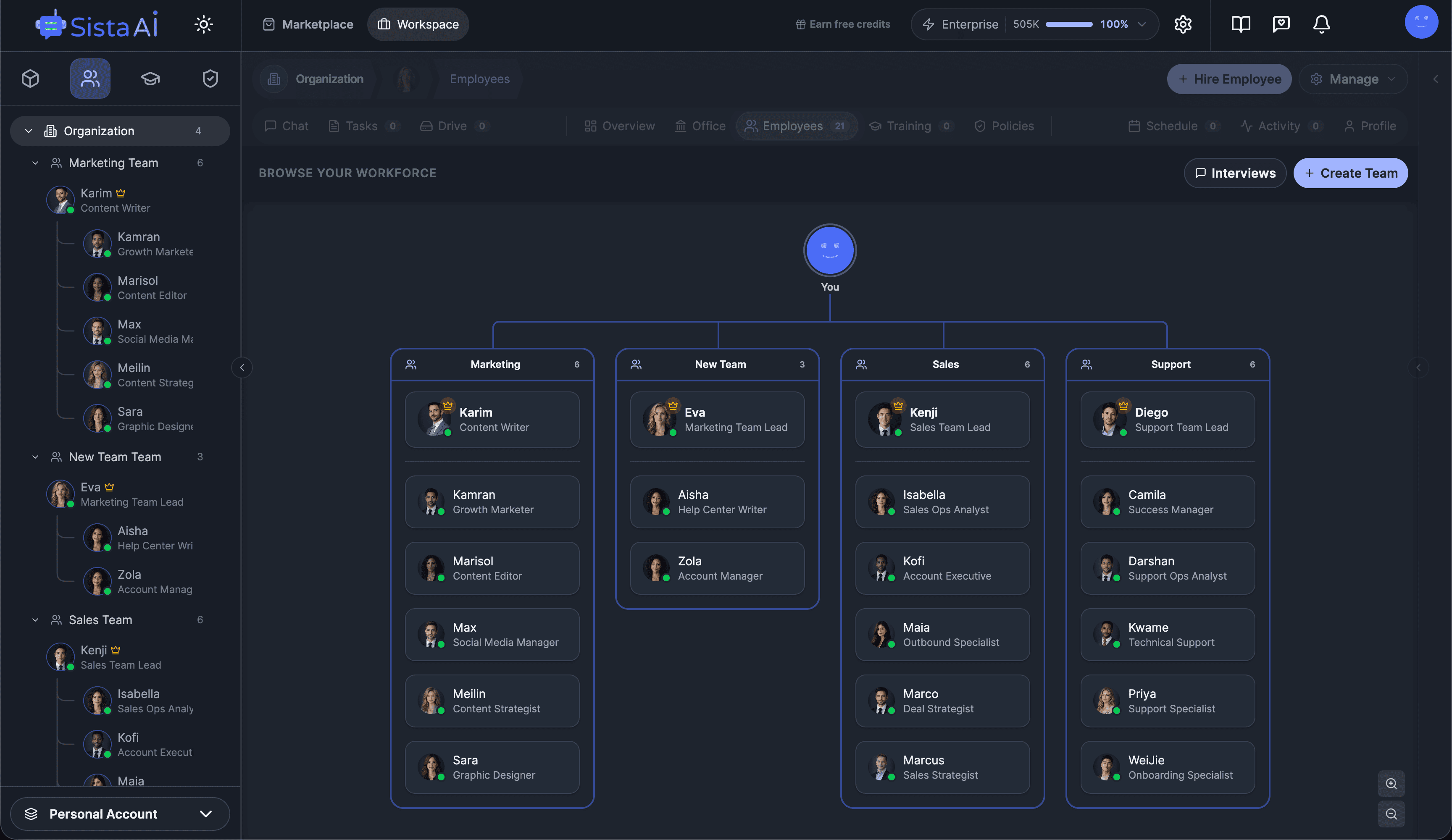
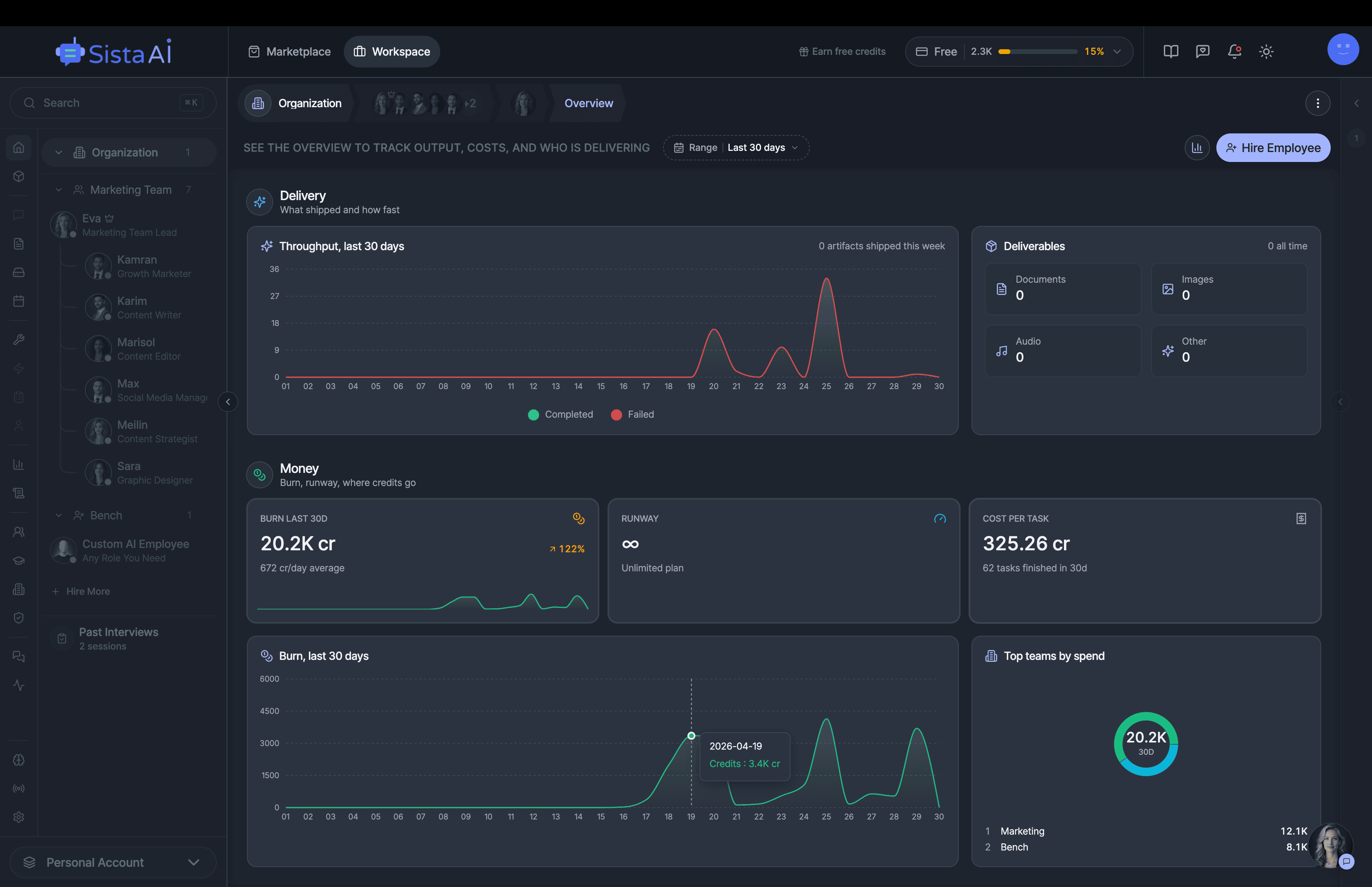

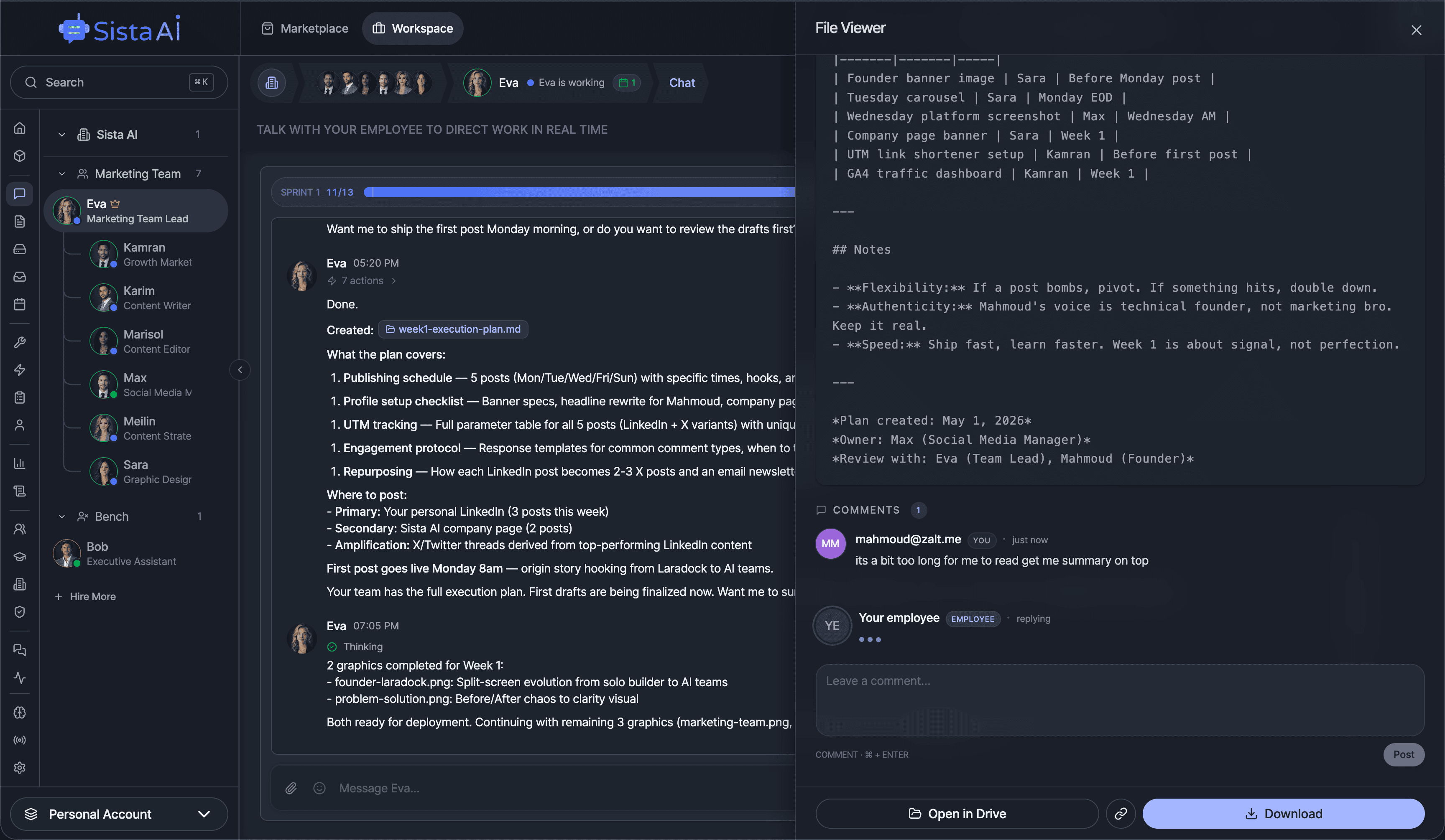
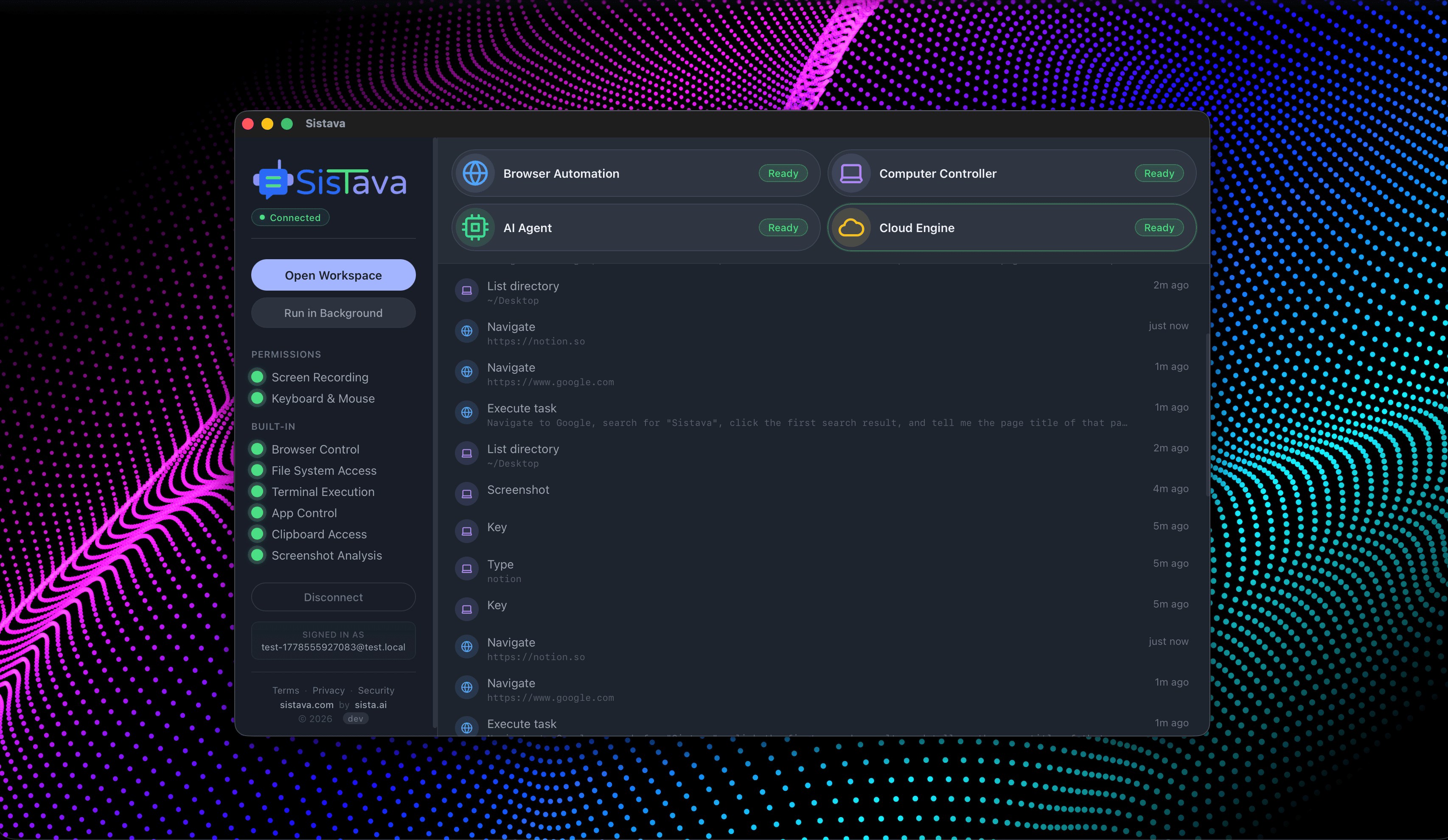
If you're a solo founder looking for AI agents to handle sales, marketing, and ops, check it out, You'll find it valuable. I use it myself to run my business. Your feedback is appreciated.
Building something similar? Let's exchange some knowledge.- Sales outreach
- Persistent memory
- Marketing automation
- MCP integrations
- Browser automation
- RAG knowledge base
- Meeting summaries
- Custom guardrails
- Computer control
- Multi-agent teams
- Ops & admin
- 3D office view