One of 55 free AI tools built by Zalt, an AI architect and consultant with 16 years of experience.
Free Speech to Text
Transcribe audio to text for free using OpenAI's Whisper speech recognition model running entirely in your browser. Record from your microphone or upload MP3, WAV, M4A, or other audio files and get accurate transcriptions in seconds. Supports 99 languages with automatic language detection, segment and word-level timestamps, and translation to English. No signup, no server, no API calls — all processing happens locally via WebAssembly using Hugging Face Transformers.js, so your audio never leaves your device.
Preparing speech-to-text interface...
Hire AI Employees
Hire AI Employees that work 24/7. No code.Are you a solo founder still doing sales, marketing, and support by hand? Hire AI Employees to run it all for you. They work 24/7, set up with no code, and go live in minutes.


More Free Tools
More than 20 free AI tools.

Hire AI Expert
Mahmoud Zalt · Freelance AI Engineer
What Is Whisper and How Does This Speech to Text Tool Work?
This free speech-to-text tool is powered by OpenAI Whisper, the most widely used open-source automatic speech recognition model available. Whisper was trained on 680,000 hours of multilingual audio data, making it capable of transcribing speech in 99 languages with near-professional accuracy. The model runs entirely in your browser — your audio is never uploaded to any server.
The browser-based implementation uses Hugging Face Transformers.js, a JavaScript library that brings state-of-the-art machine learning models to the web. Transformers.js converts Whisper model weights to ONNX format and executes them via ONNX Runtime compiled to WebAssembly, allowing the full Whisper pipeline to run in a browser tab without any server, plugin, or extension. The models are quantized to 8-bit integers for smaller downloads and faster inference while maintaining high transcription accuracy.
You can record directly from your microphone or upload audio files in MP3, WAV, M4A, WebM, OGG, or FLAC format. Choose from three model sizes — Tiny for fast results on any device, Base for balanced accuracy and speed, or Small for the highest quality. Enable segment or word-level timestamps for subtitle creation, select a specific language to improve accuracy, or translate foreign-language audio to English. The model files are downloaded once and cached in your browser, so repeat visits load almost instantly.
How Whisper Speech Recognition Works in the Browser
This tool is built on Hugging Face Transformers.js, the JavaScript counterpart to the widely-used Python transformers library. Transformers.js provides a pipeline API that mirrors the Python version — creating an automatic speech recognition pipeline is a single function call. Under the hood, it uses ONNX Runtime for inference with WebAssembly (WASM) as the default execution provider and optional WebGPU support for GPU acceleration in supported browsers. Models are loaded as quantized ONNX files from Hugging Face Hub and cached in the browser using the Cache API.
The automatic-speech-recognition pipeline supports several Whisper-specific parameters: return_timestamps (boolean or "word" for word-level precision), language (ISO code to hint the spoken language), task ("transcribe" or "translate" for English translation), chunk_length_s and stride_length_s for processing long audio in overlapping windows, and standard generation config options. Transformers.js supports Whisper Tiny, Base, Small, Medium, and Large model variants, as well as distilled and quantized checkpoints from the ONNX Community on Hugging Face Hub. The library runs in any modern browser, Node.js, Deno, and Bun — making it one of the most versatile options for deploying speech recognition in JavaScript applications.
How It Works
Choose a model, language, and timestamp mode, then record or upload audio.
The AI transcribes your speech to text instantly on your device — with optional timestamps.
Copy the transcription or download it as a text file.
Production voice transcription.
Real-time streaming, multi-language, speaker detection. Built into your product, not a browser tab.
Key Features
Privacy & Trust
Use Cases
Limitations
- Initial model download may take 1-2 minutes on first use (cached for future visits)
- Transcription speed depends on your device hardware
- Best results with clear audio and minimal background noise
- Maximum audio length depends on available device memory
- Larger models require more RAM and take longer to load
- Overlapping speakers may reduce transcription accuracy
- Word-level timestamps may be less precise than segment-level timestamps
Q&A SESSION
Got a question about voice AI?
Which provider, how to handle accents, real-time vs batch — bring your question.
Frequently Asked Questions
Is this speech-to-text tool completely free?
Yes, it is 100% free with no usage limits, no signup, and no per-minute charges. Cloud transcription services like Otter.ai, Rev, and Descript charge $8-25/month or per minute of audio. Because this tool runs OpenAI Whisper locally in your browser, there are no server costs, which means unlimited free transcription for as long as you need.
Is my audio sent to a server or stored anywhere?
No. All audio processing and transcription happens entirely inside your browser using WebAssembly. Your recordings and uploaded audio files never leave your device — not even temporarily. There are no API calls, no cloud uploads, and no analytics on your audio content. This makes it safe for transcribing confidential meetings, medical dictation, legal depositions, private interviews, or any recording you would not want a third party to hear. Verify this by checking the Network tab in DevTools while transcribing.
What is OpenAI Whisper and why is it used here?
Whisper is an open-source automatic speech recognition model created by OpenAI, trained on 680,000 hours of multilingual audio data collected from the web. It is widely regarded as the most accurate open-source speech-to-text model available, achieving near-human accuracy on clean English audio. OpenAI released the model weights under the MIT license, and this tool runs them in your browser via Hugging Face Transformers.js — a JavaScript library that brings machine learning models to the browser using ONNX Runtime and WebAssembly. The result is cloud-grade transcription quality with complete local privacy.
What audio file formats can I upload for transcription?
The tool accepts MP3, WAV, M4A, WebM, OGG, and FLAC audio files — covering the formats produced by virtually every recording app, phone voice memo, podcast tool, and video conferencing platform. You can also record directly from your microphone in the browser. For the best transcription accuracy, WAV or high-bitrate MP3 files produce the cleanest results. Compressed formats like low-bitrate OGG may slightly reduce accuracy due to audio artifacts.
Why does the Whisper model take a few minutes to load the first time?
On first use, the model weights are downloaded as quantized ONNX files to your browser cache. The "Tiny" model is about 45MB and loads in seconds on a decent connection. The "Base" model is around 80MB and the "Small" model is about 250MB. Once downloaded, the files are cached locally so future sessions start almost instantly. If the download seems stuck, check your internet connection or try a smaller model first.
Which Whisper model size should I choose — Tiny, Base, or Small?
Start with "Tiny" for fast results on any device — it loads quickly and handles clear English speech well. Choose "Base" for noticeably better accuracy with accented speech, background noise, or technical vocabulary. Choose "Small" for the highest quality transcription — it approaches professional human transcription accuracy but requires more RAM (1-2 GB) and takes longer to process. If you are on a laptop with 8GB+ RAM, "Small" is worth the wait for important recordings.
Does this speech-to-text tool work on phones and tablets?
It works best on desktop or laptop computers with adequate RAM. Mobile devices can run the "Tiny" model in most cases, but "Base" and "Small" may fail to load due to memory constraints. If you want to transcribe on mobile, use the "Tiny" model and keep recordings short. Newer phones with 8GB+ RAM (iPhone 15 Pro, recent flagship Android devices) have the best chance of running larger models.
Can I transcribe audio in languages other than English?
Yes. Whisper supports 99 languages including Spanish, French, German, Portuguese, Japanese, Chinese, Korean, Arabic, Hindi, Russian, and many more. Use the language dropdown to select the spoken language or leave it on "Auto-detect" to let Whisper identify it automatically. You can also enable "Translate to English" to get an English translation of foreign-language audio. Accuracy varies by language — European languages tend to perform best, while lower-resource languages may have higher error rates.
How do segment and word-level timestamps work?
Whisper can output timestamps alongside the transcribed text. "Segment" timestamps break the audio into phrases or sentences, each with a start and end time — useful for creating SRT or VTT subtitle files. "Word-level" timestamps assign a time to each individual word, which is useful for precise captioning, karaoke-style highlighting, or aligning text to audio. Select your preferred mode from the Timestamps dropdown before transcribing. Both modes are processed entirely on your device.
Can Whisper translate audio to English?
Yes. Whisper was trained on both transcription and translation tasks. When you select a non-English language and enable "Translate to English," the model will transcribe the foreign-language audio and output the result in English. This works for all 99 supported languages. The translation quality is generally good for common languages like Spanish, French, German, and Chinese, and less reliable for lower-resource languages.
What is Transformers.js and how does it run Whisper in the browser?
Transformers.js is an open-source JavaScript library by Hugging Face that brings machine learning models to the browser. It is functionally equivalent to the popular Python transformers library and uses ONNX Runtime to execute models via WebAssembly (WASM). Whisper model weights are converted to ONNX format and quantized to 8-bit integers (q8) for smaller download size and faster inference. This means you get the same model running in your browser tab that developers use on servers — no plugins, no extensions, no cloud dependency.
How accurate is the transcription compared to paid services?
For clear English audio with a single speaker and minimal background noise, the Whisper "Small" model achieves word error rates comparable to professional transcription services like Rev or Otter.ai. Accuracy degrades with background noise, overlapping speakers, heavy accents, mumbling, or poor microphone quality. For best results, use a decent microphone, minimize ambient noise, and speak clearly. The "Tiny" model is noticeably less accurate but still useful for getting the gist of a recording quickly.
Is this the same as the OpenAI Whisper API service?
It uses the same Whisper model architecture and equivalent weights (converted to ONNX format for browser execution), but runs locally in your browser instead of on OpenAI's cloud servers. The OpenAI API charges $0.006 per minute of audio and requires you to upload your recordings to their servers. This tool is free and keeps your audio completely private. The tradeoff is that transcription speed depends on your device hardware rather than powerful cloud GPUs, so processing may be slower on older machines.
How do I free up storage space after using this tool?
The Whisper model files are cached in your browser storage and can take 45MB to 250MB depending on the model size. To reclaim that space: open DevTools (F12) > Application > Cache Storage and delete entries related to Whisper or transformers. Alternatively, go to your browser settings > Privacy > Clear browsing data > Cached images and files. This only removes the model cache — your bookmarks, passwords, and other data are unaffected. The model will simply re-download the next time you use the tool.
What is the maximum audio length I can transcribe?
There is no hard time limit built into the tool, but practical limits depend on your device memory. The tool automatically splits audio into 30-second chunks with overlapping strides for seamless transcription. Most modern laptops can handle 30-60 minutes of audio without issues using the "Tiny" or "Base" model. Very long recordings (2+ hours) may cause the browser to run out of memory, especially with the "Small" model. For long recordings, consider splitting the audio into 30-minute segments and transcribing each one separately.
Can I use this to generate subtitles for YouTube videos?
Yes, and it is now easier with built-in timestamp support. Extract the audio from your video, upload it to this tool, and select "Segments" in the Timestamps dropdown. You will get the transcription with start and end times for each phrase, which you can format as SRT or VTT subtitle files. The Whisper "Base" or "Small" model gives the best balance between accuracy and speed for video subtitles.
AI Agents Orchestration
To Run Your Business on Autopilot
I'm building a modern AI workforce for deploying autonomous AI agents at scale. Live since 15 April 2026 at www.sistava.com.
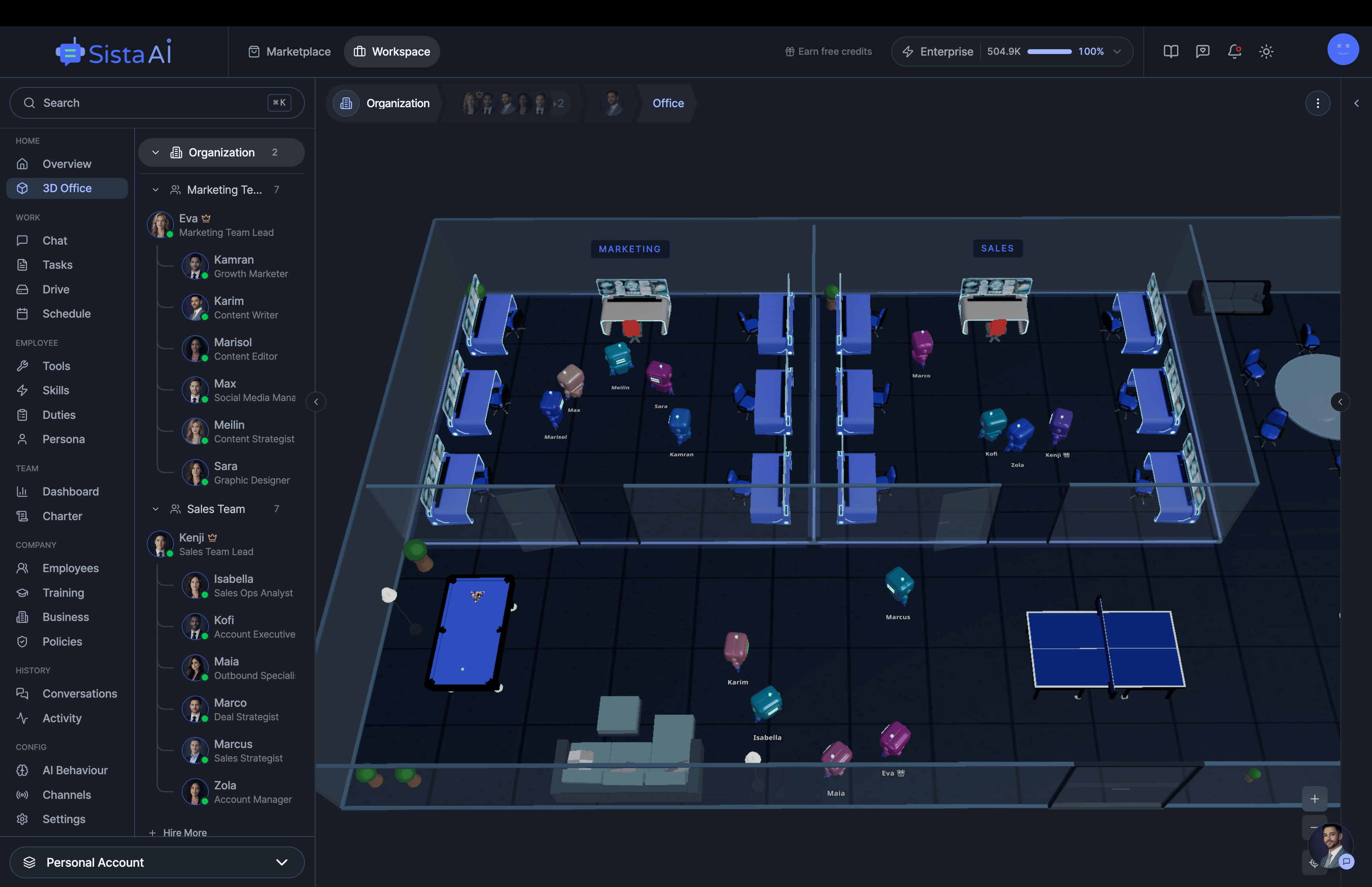
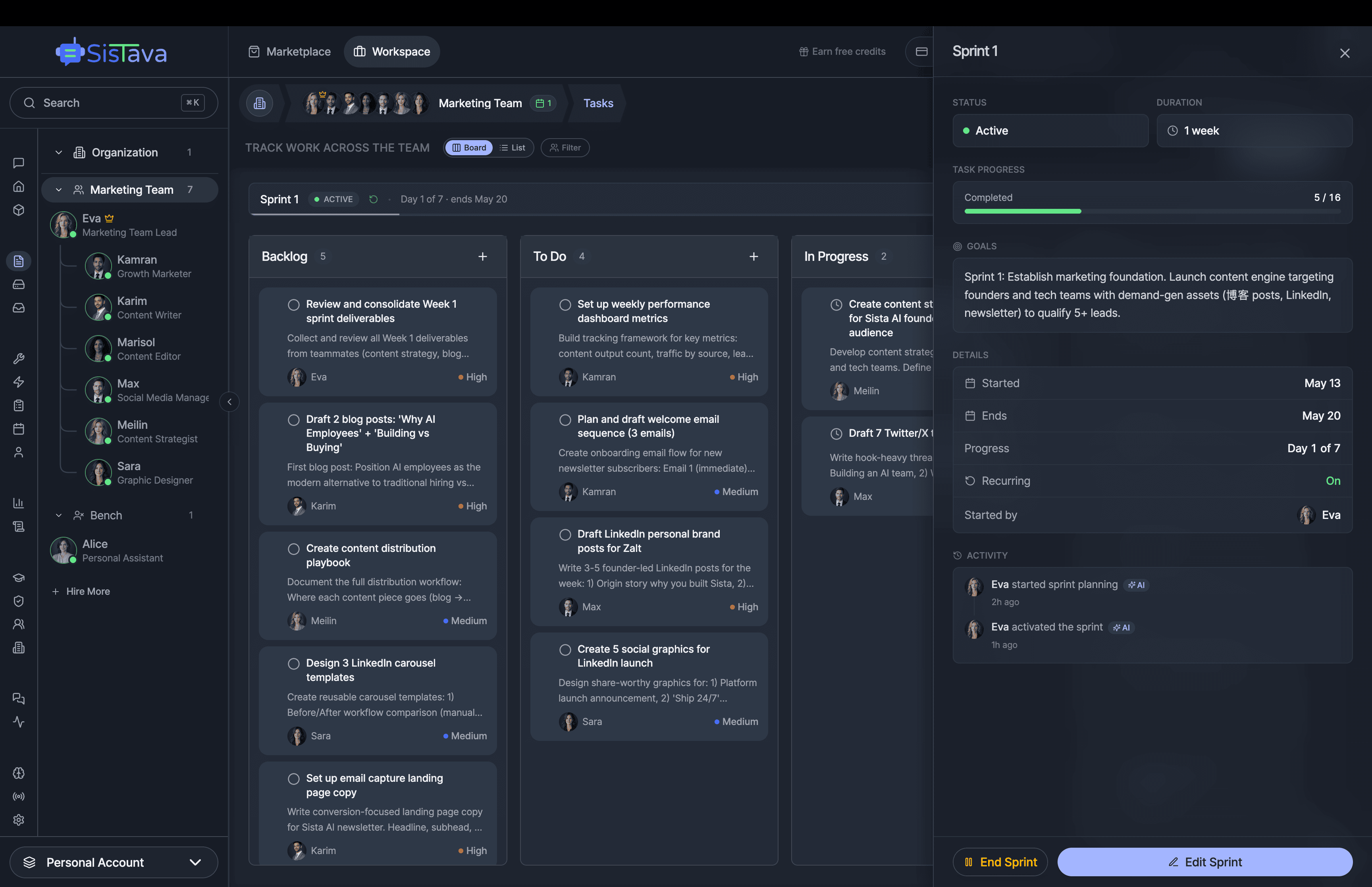
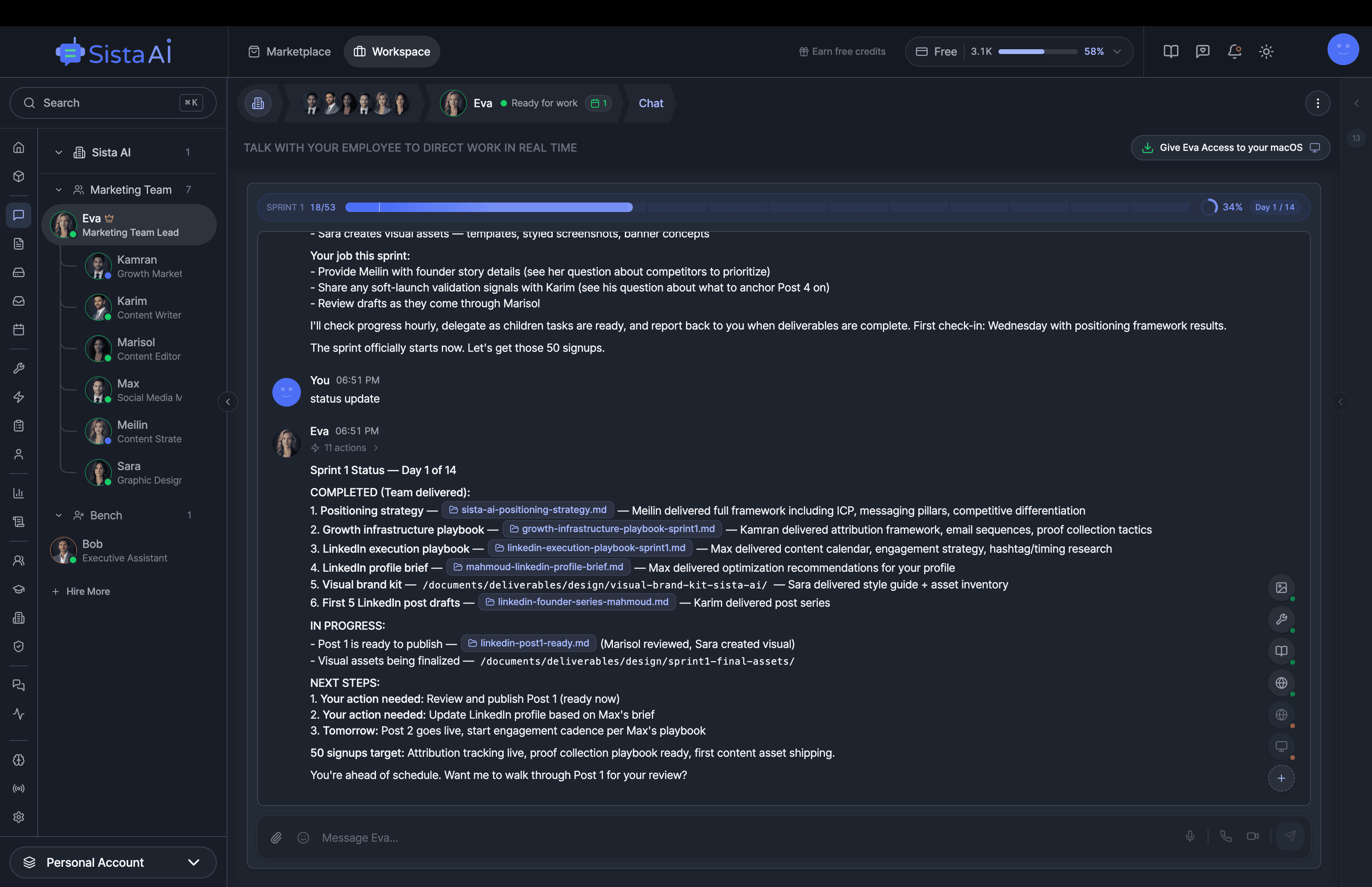
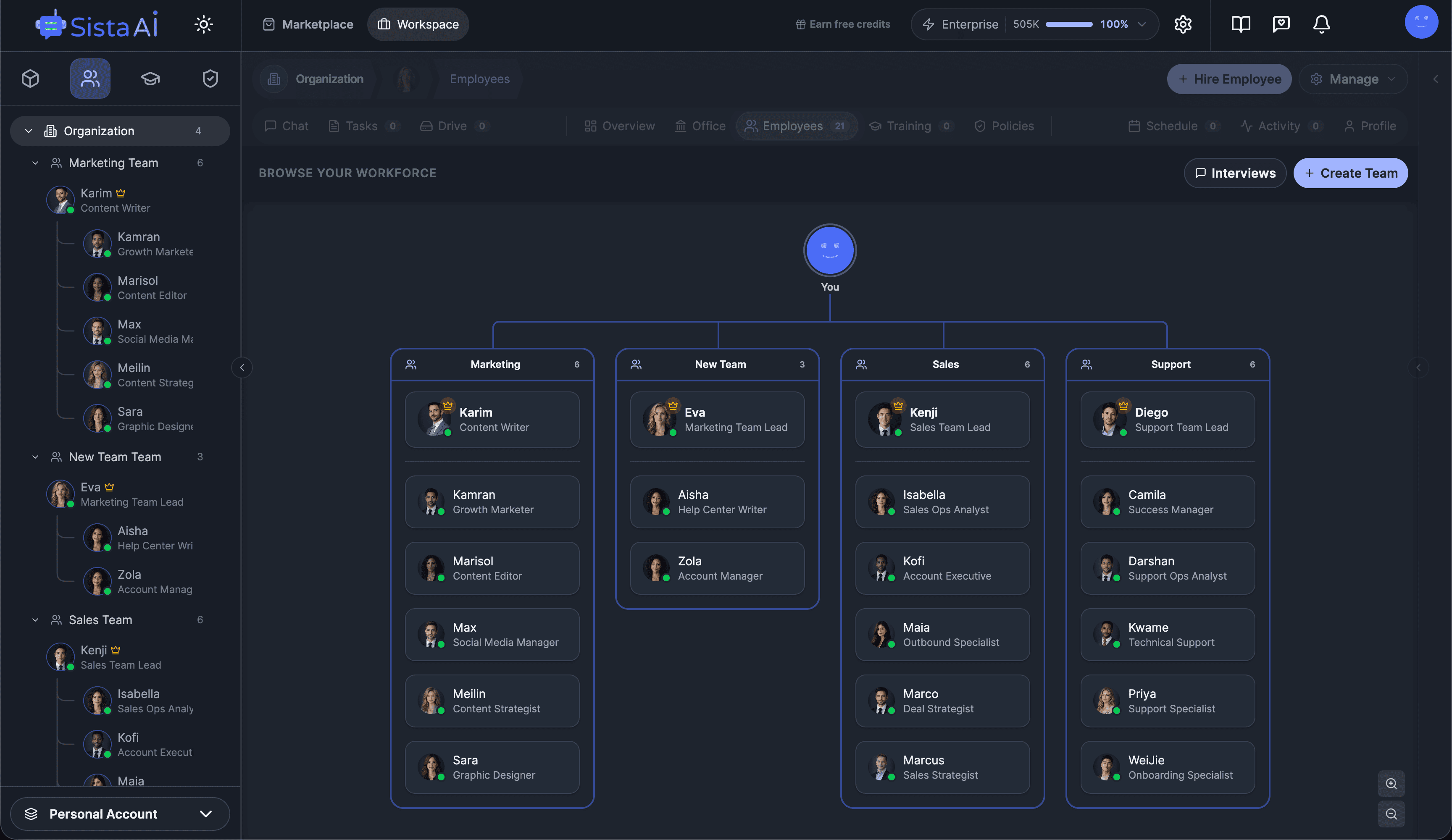
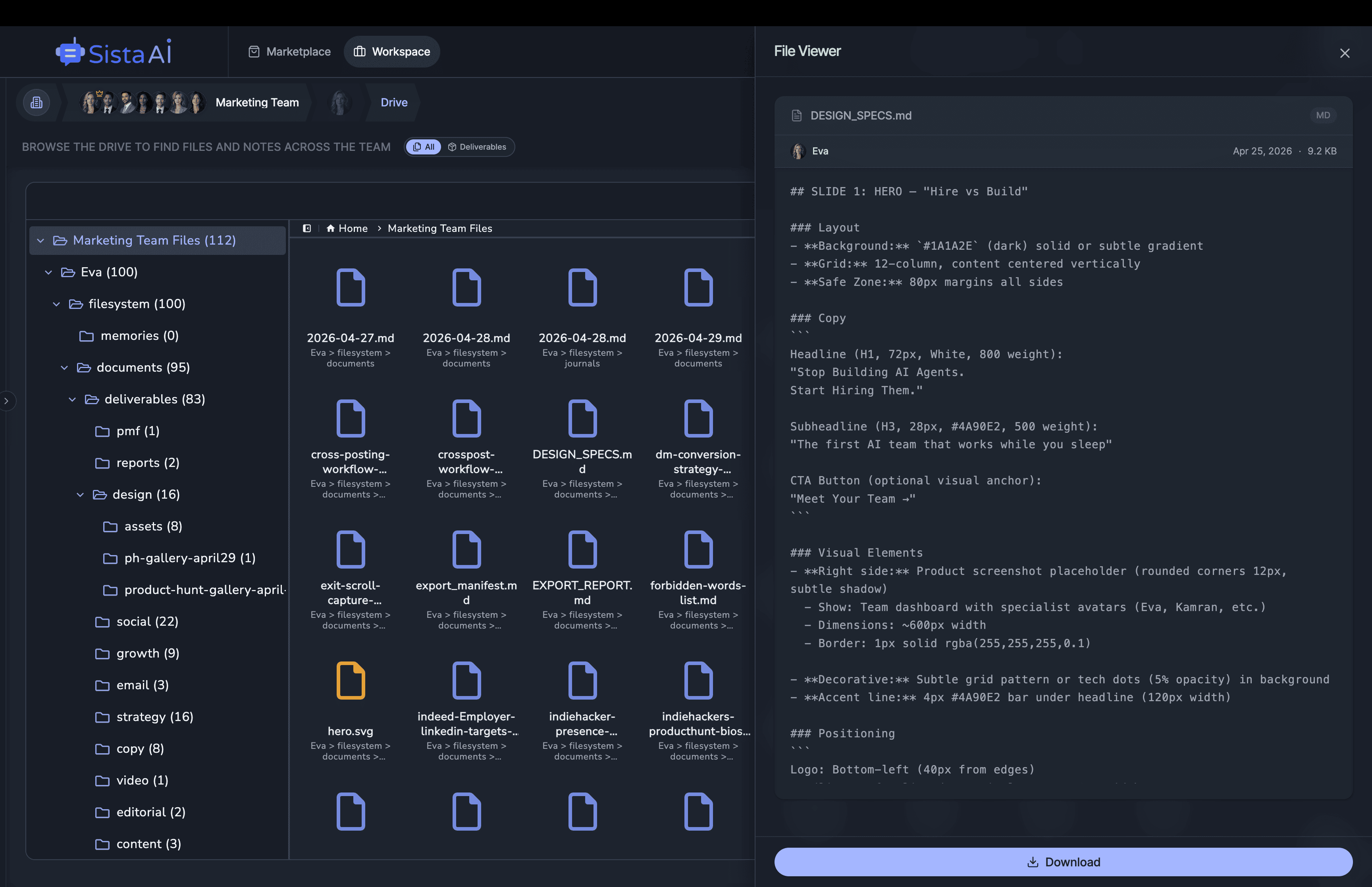
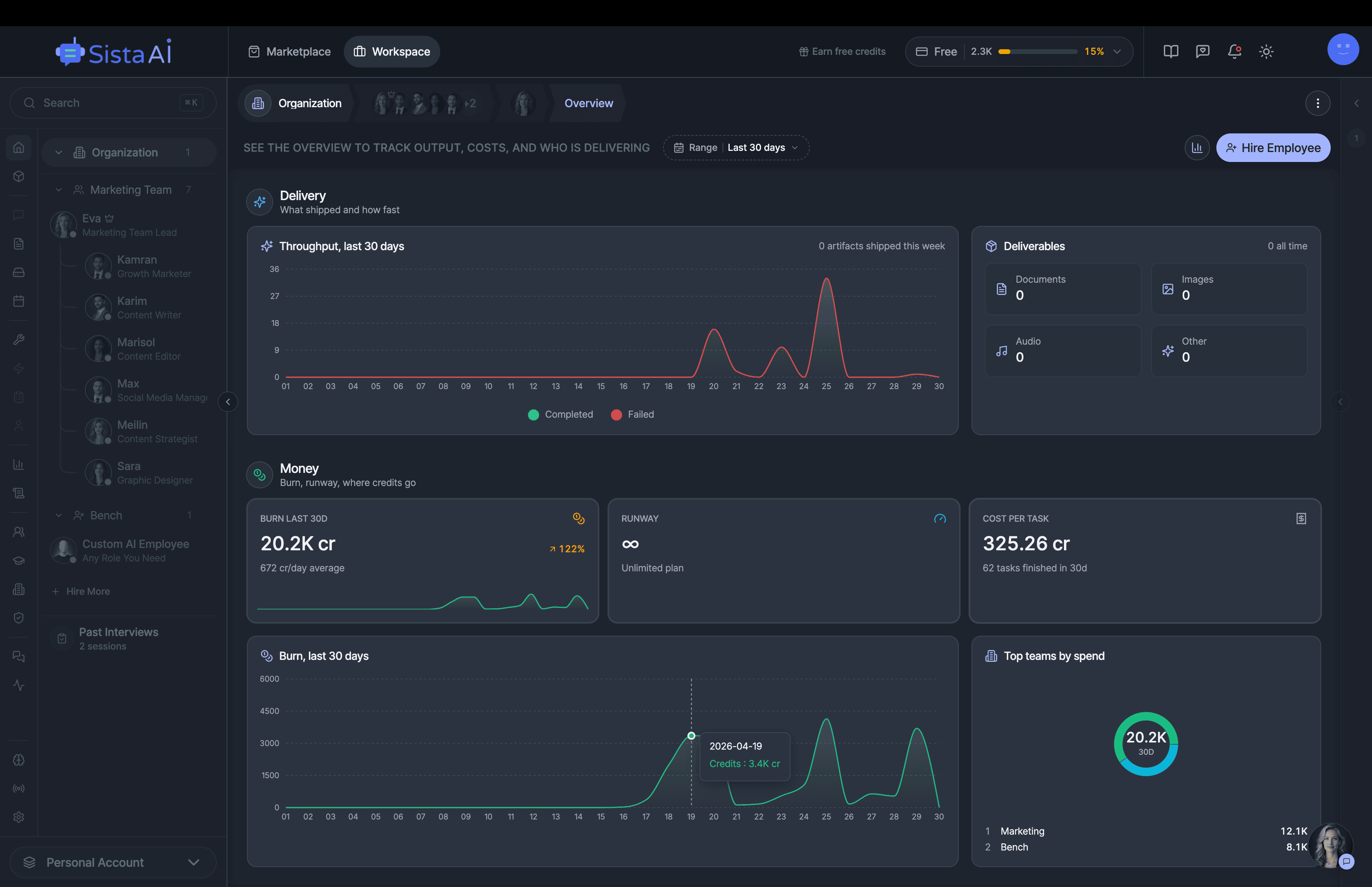

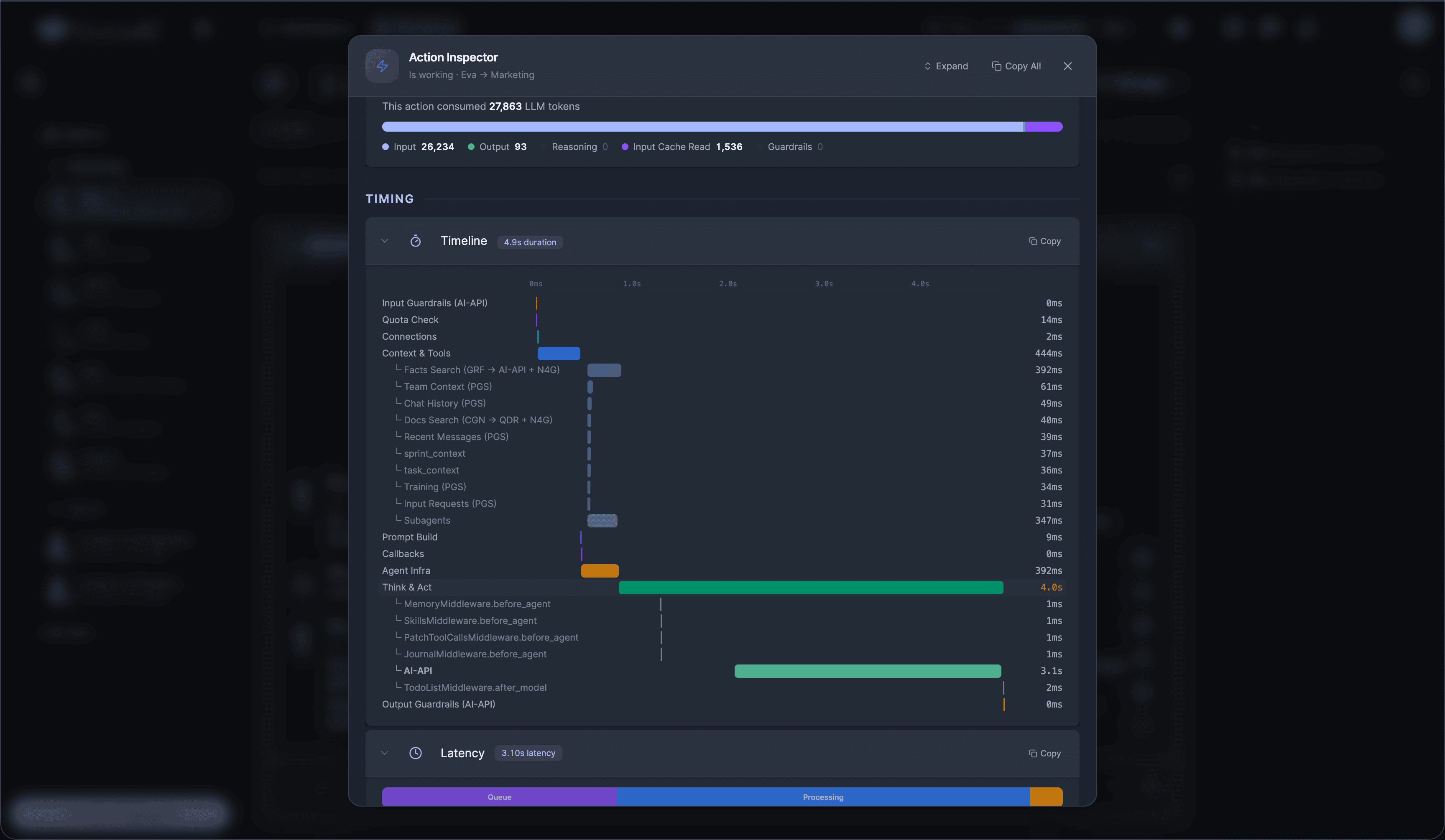
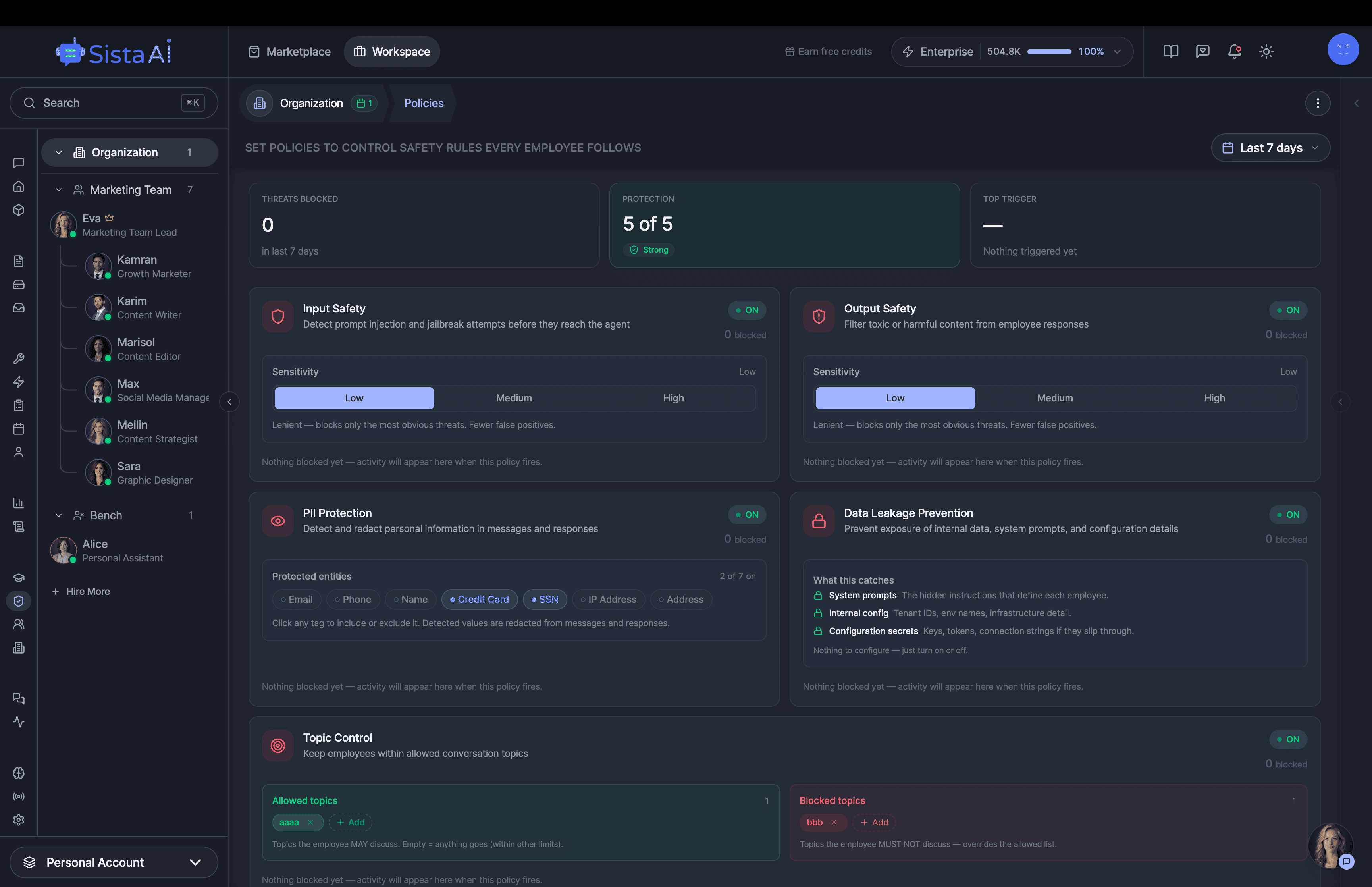
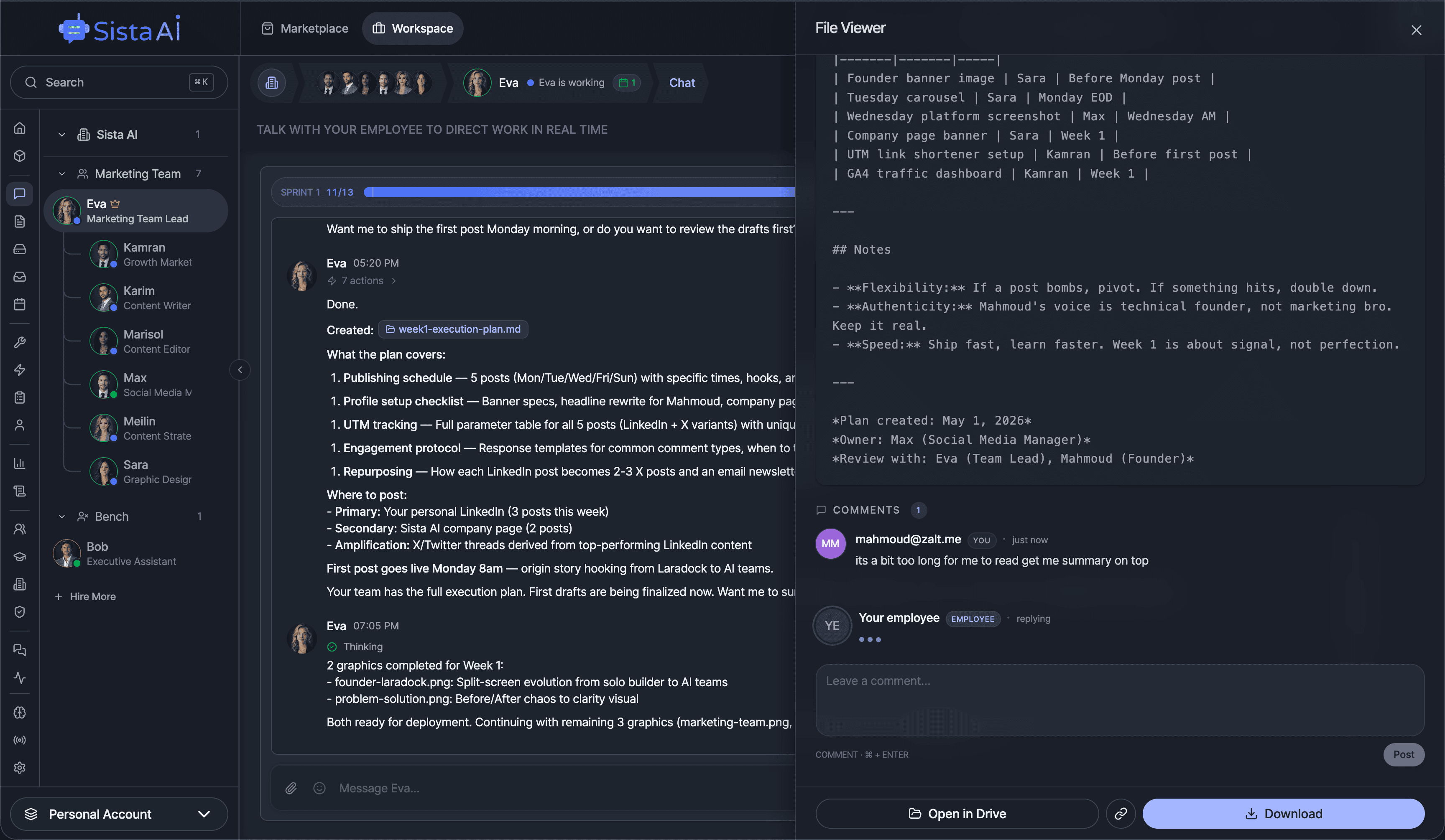
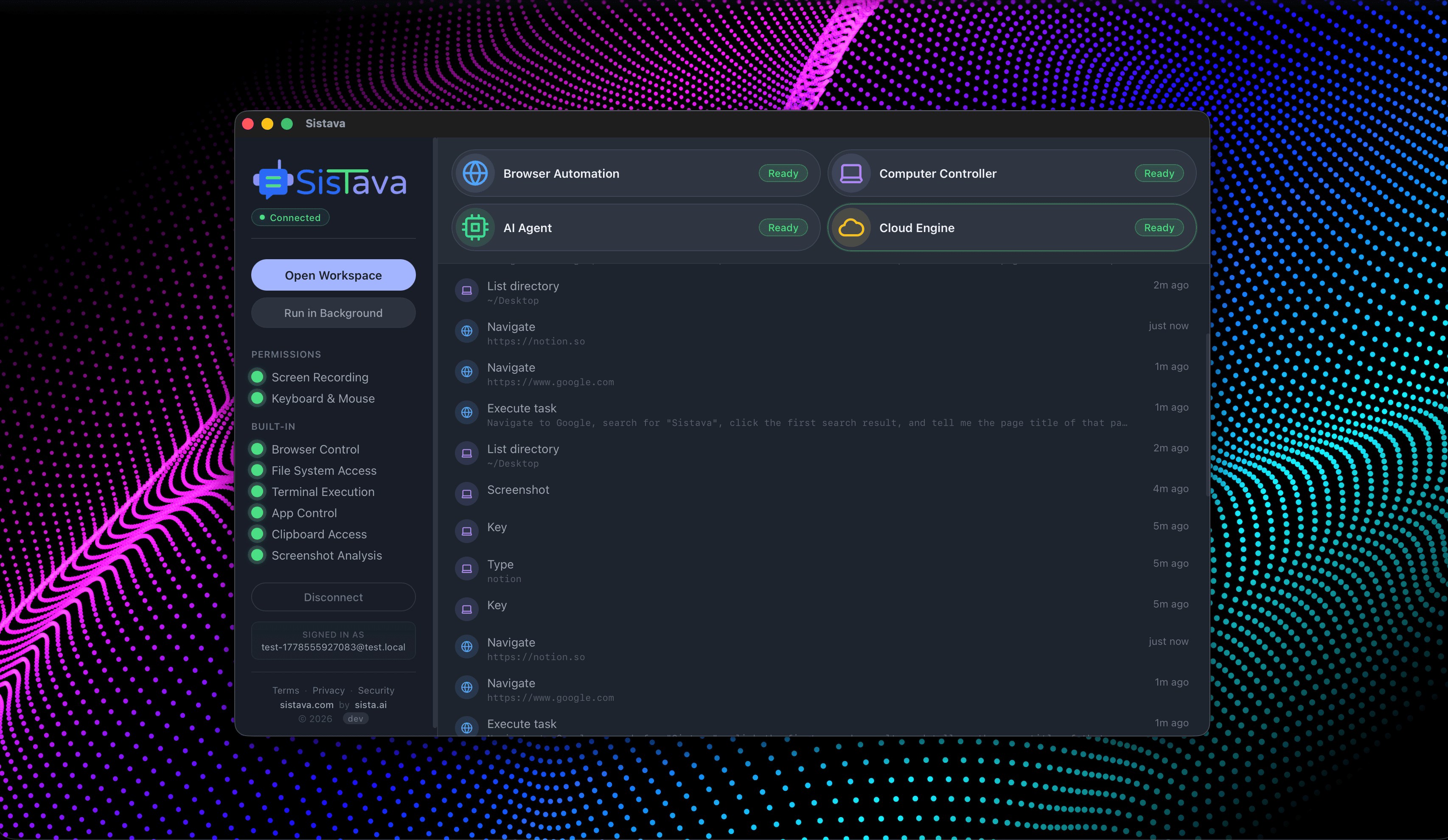
If you're a solo founder looking for AI agents to handle sales, marketing, and ops, check it out, You'll find it valuable. I use it myself to run my business. Your feedback is appreciated.
Building something similar? Let's exchange some knowledge.- Sales outreach
- Persistent memory
- Marketing automation
- MCP integrations
- Browser automation
- RAG knowledge base
- Meeting summaries
- Custom guardrails
- Computer control
- Multi-agent teams
- Ops & admin
- 3D office view